 |
 |
 |
| Niveau : | |
JDBC est l'acronyme de Java DataBase Connectivity et désigne une API pour permettre un accès aux bases de données avec Java.
Ce chapitre présente dans plusieurs sections l'utilisation de cette API :
Les classes de JDBC version 1.0 sont regroupées dans le package java.sql et sont incluses dans le JDK à partir de sa version 1.1. La version 2.0 de cette API est incluse dans la version 1.2 du JDK.
Pour pouvoir utiliser JDBC, il faut un pilote qui est spécifique à la base de données à laquelle on veut accéder. Avec le JDK, Sun fournit un pilote qui permet l'accès aux bases de données via ODBC.
Ce pilote permet de réaliser l'indépendance de JDBC vis à vis des bases de données.
Pour utiliser le pont JDBC-ODBC sous Window 9x, il faut utiliser ODBC en version 32 bits.
Il existe quatre types de pilote JDBC :
Ce type de driver convertit les ordres JDBC pour appeler directement les API de la base de données via un pilote natif sur le client. Ce type de driver nécessite aussi l'utilisation de code natif sur le client.
Ce type de driver utilise un protocole réseau propriétaire spécifique à une base de données. Un serveur dédié reçoit les messages par ce protocole et dialogue directement avec la base de données. Ce type de driver peut être facilement utilisé par une applet mais dans ce cas le serveur intermédiaire doit obligatoirement être installé sur la machine contenant le serveur web.
Ce type de driver, écrit en java, appelle directement le SGBD par le réseau. Il est fourni par l'éditeur de la base de données.
Les drivers se présentent souvent sous forme de fichiers jar dont le chemin doit être ajouté au classpath pour permettre au programme de l'utiliser.
Pour utiliser un pilote de type 1 (pont ODBC-JDBC) sous Windows 9x, il est nécessaire d'enregistrer la base de données dans ODBC avant de pouvoir l'utiliser.
| Attention : ODBC n'est pas fourni en standard avec Windows 9x. |
Pour enregistrer une nouvelle base de données, il faut utiliser l'administrateur de source de données ODBC.
Pour lancer cette application sous Windows 9x, il faut double-cliquer sur l'icône "ODBC 32bits" dans le panneau de configuration. |
|
Sous Windows XP, il faut double cliquer sur l'icône "Source de données (ODBC)" dans le répertoire "Outils d'administration" du panneau de configuration. |
 |
L'outil se compose de plusieurs onglets :
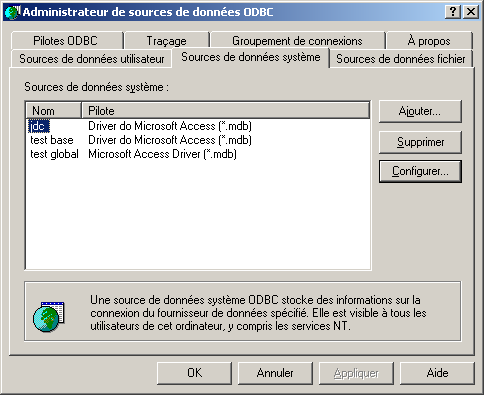
Le plus simple est de créer une telle source de données en cliquant sur le bouton "Ajouter". Une boîte de dialogue permet de sélectionner le pilote qui sera utilisé par la source de données.
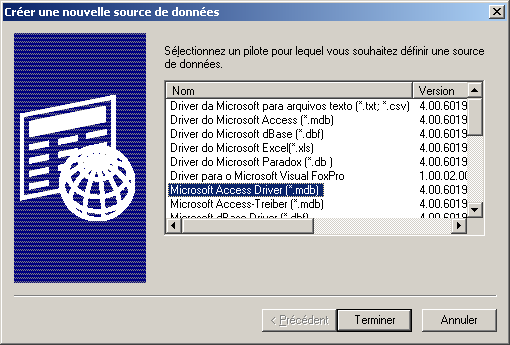
Il suffit de sélectionner le pilote et de cliquer sur "Terminer". Dans l'exemple ci-dessous, le pilote sélectionné concerne une base Microsoft Access.
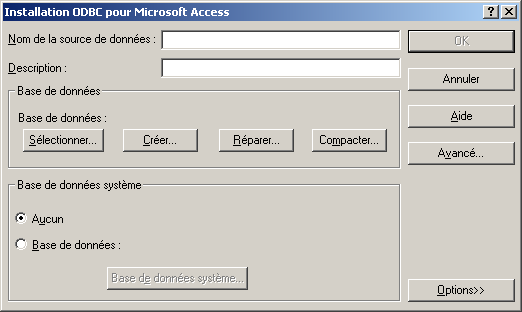
Il suffit de saisir les informations nécessaires notamment le nom de la source de données et de sélectionner la base. Un clic sur le bouton "Ok" crée la source de données qui pourra alors être utilisée.
Toutes les classes de JDBC sont dans le package java.sql. Il faut donc l'importer dans tous les programmes devant utiliser JDBC.
| Exemple : |
import java.sql.*;Il y a 4 classes importantes : DriverManager, Connection, Statement (et PreparedStatement), et ResultSet, chacune correspondant à une étape de l'accès aux données :
| Classe | Rôle |
| DriverManager | Charger et configurer le driver de la base de données. |
| Connection | Réaliser la connexion et l'authentification à la base de données. |
| Statement (et PreparedStatement) | Contenir la requête SQL et la transmettre à la base de données. |
| ResultSet | Parcourir les informations retournées par la base de données dans le cas d'une sélection de données |
Chacune de ces classes dépend de l'instanciation d'un objet de la précédente classe.
La connexion à une base de données requiert au préalable le chargement du pilote JDBC qui sera utilisé pour communiquer avec la base de données. Une fabrique permet alors de créer une instance de type Connection qui va encapsuler la connection à la base de données.
Pour se connecter à une base de données via ODBC, il faut tout d'abord charger le pilote JDBC-ODBC qui fait le lien entre les deux.
| Exemple ( code Java 1.1 ) : |
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");Pour se connecter à une base en utilisant un driver spécifique, la documentation du driver fournit le nom de la classe à utiliser. Par exemple, si le nom de la classe est jdbc.DriverXXX, le chargement du driver se fera avec le code suivant :
Class.forName("jdbc.DriverXXX");
| Exemple : Chargement du pilote pour un base PostgreSQL sous Linux |
Class.forName("postgresql.Driver");Il n'est pas nécessaire de créer une instance de cette classe et de l'enregistrer avec le DriverManager car l'appel à Class.forName le fait automatiquement : ce traitement charge le pilote et crée une instance de cette classe.
La méthode static forName() de la classe Class peut lever l'exception java.lang.ClassNotFoundException.
Pour se connecter à une base de données, il faut instancier un objet de la classe Connection en lui précisant sous forme d'URL la base à accéder.
| Exemple ( code Java 1.1 ) : Etablir une connexion sur la base testDB via ODBC |
String DBurl = "jdbc:odbc:testDB";
con = DriverManager.getConnection(DBurl);La syntaxe URL peut varier d'un type de base de données à l'autre mais elle est toujours de la forme : protocole:sous_protocole:nom
"jbdc" désigne le protocole et vaut toujours "jdbc". "odbc" désigne le sous protocole qui définit le mécanisme de connexion pour un type de base de données.
Le nom de la base de données doit être celui saisi dans le nom de la source sous ODBC.
La méthode getConnection() peut lever une exception de la classe java.sql.SQLException.
Le code suivant décrit la création d'une connexion avec un user et un mot de passe :
| Exemple ( code Java 1.1 ) : |
Connection con = DriverManager.getConnection(url, "myLogin", "myPassword");A la place de " myLogin " ; il faut mettre le nom du user qui se connecte à la base et mettre son mot de passe à la place de "myPassword "
| Exemple ( code Java 1.1 ) : |
String url = "jdbc:odbc:factures";
Connection con = DriverManager.getConnection(url, "toto", "passwd");La documentation d'un autre driver indiquera le sous-protocole à utiliser (le protocole à mettre derrière jdbc dans l'URL).
| Exemple : Connection à la base PostgreSQL nommée test avec le user jumbo et le mot de passe 12345 sur la machine locale |
Connection con=DriverManager.getConnection("jdbc:postgresql://localhost/test","jumbo","12345");
Une fois la connexion établie, il est possible d'exécuter des ordres SQL. Les objets qui peuvent être utilisés pour obtenir des informations sur la base de données sont :
| Classe | Rôle |
| DatabaseMetaData | informations à propos de la base de données : nom des tables, index, version ... |
| ResultSet | résultat d'une requête et information sur une table. L'accès se fait enregistrement par enregistrement. |
| ResultSetMetaData | informations sur les colonnes (nom et type) d'un ResultSet |
Les requêtes d'interrogation SQL sont exécutées avec les méthodes d'un objet Statement que l'on obtient à partir d'un objet Connection
| Exemple ( code Java 1.1 ) : |
ResultSet résultats = null;
String requete = "SELECT * FROM client";
try {
Statement stmt = con.createStatement();
résultats = stmt.executeQuery(requete);
} catch (SQLException e) {
//traitement de l'exception
}Un objet de la classe Statement permet d'envoyer des requêtes SQL à la base. La création d'un objet Statement s'effectue à partir d'une instance de la classe Connection :
| Exemple ( code Java 1.1 ) : |
Statement stmt = con.createStatement();Pour une requête de type interrogation (SELECT), la méthode à utiliser de la classe Statement est executeQuery(). Pour des traitements de mise à jour, il faut utiliser la méthode executeUpdate(). Lors de l'appel à la méthode d'exécution, il est nécessaire de lui fournir en paramètre la requête SQL sous forme de chaine.
Le résultat d'une requête d'interrogation est renvoyé dans un objet de la classe ResultSet par la méthode executeQuery().
| Exemple ( code Java 1.1 ) : |
ResultSet rs = stmt.executeQuery("SELECT * FROM employe");La méthode executeUpdate() retourne le nombre d'enregistrements qui ont été mis à jour
| Exemple ( code Java 1.1 ) : |
...
//insertion d'un enregistrement dans la table client
requete = "INSERT INTO client VALUES (3,'client 3','prenom 3')";
try {
Statement stmt = con.createStatement();
int nbMaj = stmt.executeUpdate(requete);
affiche("nb mise a jour = "+nbMaj);
} catch (SQLException e) {
e.printStackTrace();
}
...Lorsque la méthode executeUpdate() est utilisée pour exécuter un traitement de type DDL ( Data Definition Langage : définition de données ) comme la création d'un table, elle retourne 0. Si la méthode retourne 0, cela peut signifier deux choses : le traitement de mise à jour n'a affecté aucun enregistrement ou le traitement concernait un traitement de type DDL.
Si l'on utilise executeQuery() pour exécuter une requête SQL ne contenant pas d'ordre SELECT, alors une exception de type SQLException est levée.
| Exemple ( code Java 1.1 ) : |
...
requete = "INSERT INTO client VALUES (4,'client 4','prenom 4')";
try {
Statement stmt = con.createStatement();
ResultSet résultats = stmt.executeQuery(requete);
} catch (SQLException e) {
e.printStackTrace();
}
...| Résultat : |
java.sql.SQLException: No ResultSet was produced
java.lang.Throwable(java.lang.String)
java.lang.Exception(java.lang.String)
java.sql.SQLException(java.lang.String)
java.sql.ResultSet sun.jdbc.odbc.JdbcOdbcStatement.executeQuery(java.lang.String)
void testjdbc.TestJDBC1.main(java.lang.String [])| Attention : dans ce cas la requête est quand même effectuée. Dans l'exemple, un nouvel enregistrement est créé dans la table. |
Il n'est pas nécessaire de définir un objet Statement pour chaque ordre SQL : il est possible d'un définir un et de le réutiliser
C'est une classe qui représente une abstraction d'une table qui se compose de plusieurs enregistrements constitués de colonnes qui contiennent les données.
Les principales méthodes pour obtenir des données sont :
| Méthode | Rôle |
| getInt(int) | retourne sous forme d'entier le contenu de la colonne dont le numéro est passé en paramètre. |
| getInt(String) | retourne sous forme d'entier le contenu de la colonne dont le nom est passé en paramètre. |
| getFloat(int) | retourne sous forme d'un nombre flottant le contenu de la colonne dont le numéro est passé en paramètre. |
| getFloat(String) | retourne sous forme d'un nombre flottant le contenu de la colonne dont le nom est passé en paramètre. |
| getDate(int) | retourne sous forme de date le contenu de la colonne dont le numéro est passé en paramètre. |
| getDate(String) | retourne sous forme de date le contenu de la colonne dont le nom est passé en paramètre. |
| next() | se déplace sur le prochain enregistrement : retourne false si la fin est atteinte |
| close() | ferme le ResultSet |
| getMetaData() | retourne un objet de type ResultSetMetaData associé au ResultSet. |
La méthode getMetaData() retourne un objet de la classe ResultSetMetaData qui permet d'obtenir des informations sur le résultat de la requête. Ainsi, le nombre de colonnes peut être obtenu grâce à la méthode getColumnCount() de cet objet.
| Exemple : |
ResultSetMetaData rsmd;
rsmd = results.getMetaData();
nbCols = rsmd.getColumnCount();La méthode next() déplace le curseur sur le prochain enregistrement. Le curseur pointe initialement juste avant le premier enregistrement : il est nécessaire de faire un premier appel à la méthode next() pour se placer sur le premier enregistrement.
Des appels successifs à next permettent de parcourir l'ensemble des enregistrements.
Elle retourne false lorsqu'il n'y a plus d'enregistrement. Il faut toujours protéger le parcours d'une table dans un bloc de capture d'exception
| Exemple ( code Java 1.1 ) : |
//parcours des données retournées
try {
ResultSetMetaData rsmd = resultats.getMetaData();
int nbCols = rsmd.getColumnCount();
while (resultats.next()) {
for (int i = 1; i <= nbCols; i++)
System.out.print(resultats.getString(i) + " ");
System.out.println();
}
resultats.close();
} catch (SQLException e) {
//traitement de l'exception
}Les méthodes getXXX() permettent d'extraire les données selon leur type spécifié par XXX tel que getString(), getDouble(), getInteger(), etc ... . Il existe deux formes de ces méthodes : indiquer le numéro de la colonne en paramètre (en commençant par 1) ou indiquer le nom de la colonne en paramètre. La première méthode est plus efficace mais peut générer plus d'erreurs à l'exécution notamment si la structure de la table évolue.
| Attention : il est important de noter que ce numéro de colonne fourni en paramètre fait référence au numéro de colonne de l'objet resultSet (celui correspondant dans l'ordre SELECT) et non au numéro de colonne de la table. |
La méthode getString() permet d'obtenir la valeur d'un champ de n'importe quel type.
| Exemple ( code Java 1.1 ) : |
import java.sql.*;
public class TestJDBC1 {
private static void affiche(String message) {
System.out.println(message);
}
private static void arret(String message) {
System.err.println(message);
System.exit(99);
}
public static void main(java.lang.String[] args) {
Connection con = null;
ResultSet résultats = null;
String requete = "";
// chargement du pilote
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
} catch (ClassNotFoundException e) {
arret("Impossible de charger le pilote jdbc:odbc");
}
//connection a la base de données
affiche("connexion a la base de données");
try {
String DBurl = "jdbc:odbc:testDB";
con = DriverManager.getConnection(DBurl);
} catch (SQLException e) {
arret("Connection à la base de données impossible");
}
//insertion d'un enregistrement dans la table client
affiche("creation enregistrement");
requete = "INSERT INTO client VALUES (3,'client 3','prenom 3')";
try {
Statement stmt = con.createStatement();
int nbMaj = stmt.executeUpdate(requete);
affiche("nb mise a jour = "+nbMaj);
} catch (SQLException e) {
e.printStackTrace();
}
//creation et execution de la requete
affiche("creation et execution de la requête");
requete = "SELECT * FROM client";
try {
Statement stmt = con.createStatement();
résultats = stmt.executeQuery(requete);
} catch (SQLException e) {
arret("Anomalie lors de l'execution de la requête");
}
//parcours des données retournées
affiche("parcours des données retournées");
try {
ResultSetMetaData rsmd = résultats.getMetaData();
int nbCols = rsmd.getColumnCount();
boolean encore = résultats.next();
while (encore) {
for (int i = 1; i <= nbCols; i++)
System.out.print(résultats.getString(i) + " ");
System.out.println();
encore = résultats.next();
}
résultats.close();
} catch (SQLException e) {
arret(e.getMessage());
}
affiche("fin du programme");
System.exit(0);
}
}| Résultat : |
connexion a la base de données
creation enregistrement
nb mise a jour = 1
creation et execution de la requête
parcours des données retournées
1.0 client 1 prenom 1
2.0 client 2 prenom 2
3.0 client 3 prenom 3
fin du programme
L'API JDBC propose plusieurs interfaces pour permettre d'obtenir des dynamiquement des informations concernant les métadonnées sur la base de données ou sur un ResultSet
La méthode getMetaData() d'un objet ResultSet retourne un objet de type ResultSetMetaData. Cet objet permet de connaître le nombre, le nom et le type des colonnes.
| Méthode | Rôle |
| int getColumnCount() | Retourner le nombre de colonnes du ResultSet |
| String getColumnName(int) | Retourner le nom de la colonne dont le numéro est donné |
| String getColumnLabel(int) | Retourner le libellé de la colonne donnée |
| boolean isCurrency(int) | Retourner true si la colonne contient un nombre au format monétaire |
| boolean isReadOnly(int) | Retourner true si la colonne est en lecture seule |
| boolean isAutoIncrement(int) | Retourner true si la colonne est auto incrémentée |
| int getColumnType(int) | Retourner le type de données SQL de la colonne |
Un objet de la classe DatabaseMetaData permet d'obtenir des informations sur la base de données dans son ensemble : nom des tables, nom des colonnes dans une table, méthodes SQL supportées
| Méthode | Rôle |
| ResultSet getCatalogs() | Retourner la liste du catalogue d'informations ( Avec le pont JDBC-ODBC, on obtient la liste des bases de données enregistrées dans ODBC). |
| ResultSet getTables(catalog, schema, tableNames, columnNames) | Retourner une description de toutes les tables correspondant au TableNames donné et à toutes les colonnes correspondantes à columnNames. |
| ResultSet getColumns(catalog, schema, tableNames, columnNames) | Retourner une description de toutes les colonnes correspondant au TableNames donné et à toutes les colonnes correspondantes à columnNames. |
| String getURL() | Retourner l'URL de la base à laquelle on est connecté |
| String getDriverName() | Retourner le nom du driver utilisé |
La méthode getTables() de l'objet DataBaseMetaData demande quatre arguments :
getTables(catalog, schema, tablemask, types[]);
| Exemple ( code Java 1.1 ) : |
con = DriverManager.getConnection(url);
dma =con.getMetaData();
String[] types = new String[1];
types[0] = "TABLE"; //set table type mask
results = dma.getTables(null, null, "%", types);
while (results.next()) {
for (i = 1; i <= numCols; i++)
System.out.print(results.getString(i)+" ");
System.out.println();
}
L'interface PreparedStatement définit les méthodes pour un objet qui va encapsuler une requête précompilée. Ce type de requête est particulièrement adapté pour une exécution répétée d'une même requête avec des paramètres différents.
Cette interface hérite de l'interface Statement.
Lors de l'utilisation d'un objet de type PreparedStatement, la requête est envoyée au moteur de la base de données pour que celui-ci prépare son exécution.
Un objet qui implémente l'interface PreparedStatement est obtenu en utilisant la méthode preparedStatement() d'un objet de type Connection. Cette méthode attend en paramètre une chaîne de caractères contenant la requête SQL. Dans cette chaîne, chaque paramètre est représenté par un caractère ?.
Un ensemble de méthode setXXX() (ou XXX représente un type primitif ou certains objets tels que String, Date, Object, ...) permet de fournir les valeurs de chaque paramètre défini dans la requête. Le premier paramètre de ces méthodes précise le numéro du paramètre dont la méthode va fournir la valeur. Le second paramètre précise cette valeur.
| Exemple ( code Java 1.1 ) : |
package com.jmd.test.dej;
import java.sql.*;
public class TestJDBC2 {
private static void affiche(String message) {
System.out.println(message);
}
private static void arret(String message) {
System.err.println(message);
System.exit(99);
}
public static void main(java.lang.String[] args) {
Connection con = null;
ResultSet resultats = null;
String requete = "";
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
} catch (ClassNotFoundException e) {
arret("Impossible de charger le pilote jdbc:odbc");
}
affiche("connexion a la base de données");
try {
String DBurl = "jdbc:odbc:testDB";
con = DriverManager.getConnection(DBurl);
PreparedStatement recherchePersonne =
con.prepareStatement("SELECT * FROM personnes WHERE nom_personne = ?");
recherchePersonne.setString(1, "nom3");
resultats = recherchePersonne.executeQuery();
affiche("parcours des données retournées");
boolean encore = resultats.next();
while (encore) {
System.out.print(resultats.getInt(1) + " : "+resultats.getString(2)+" "+
resultats.getString(3)+"("+resultats.getDate(4)+")");
System.out.println();
encore = resultats.next();
}
resultats.close();
} catch (SQLException e) {
arret(e.getMessage());
}
affiche("fin du programme");
System.exit(0);
}
}Pour exécuter la requête, l'interface PreparedStatement propose deux méthodes :
Une transaction permet de ne valider un ensemble de traitements sur la base de données que s'ils se sont tous effectués correctement.
Par exemple, une opération bancaire de transfert de fond d'un compte vers un autre oblige à la réalisation de l'opération de débit sur un compte et de l'opération de crédit sur l'autre compte. La réalisation d'une seule de ces opérations laisserait les données de la base dans un état inconsistant.
Une transaction est un mécanisme qui permet donc de s'assurer que toutes les opérations qui la compose seront réellement effectuées.
Une transaction est gérée à partir de l'objet Connection. Par défaut, une connexion est en mode auto-commit. Dans ce mode, chaque opération est validée unitairement, chacune dans sa propre transaction.
Pour pouvoir rassembler plusieurs traitements dans une transaction, il faut tout d'abord désactiver le mode auto-commit. La classe Connection possède la méthode setAutoCommit() qui attend un booléen qui précise le mode de fonctionnement.
Exemple :
connection.setAutoCommit(false);
Une fois le mode auto-commit désactivé, un appel à la méthode commit() de la classe Connection permet de valider la transaction courante. L'appel à cette méthode valide la transaction courante et créé implicitement une nouvelle transaction.
Si une anomalie intervient durant la transaction, il est possible de faire un retour en arrière pour revenir à la situation de la base de données au début de la transaction en appelant la méthode rollback() de la classe Connection.
L'interface CallableStatement définit les méthodes pour un objet qui va permettre d'appeler une procédure stockée.
Cette interface hérite de l'interface PreparedStatement.
Un objet qui implémente l'interface CallableStatement est obtenu en utilisant la méthode prepareCall() d'un objet de type Connection. Cette méthode attend en paramètre une chaîne de caractères contenant la chaîne d'appel de la procédure stockée.
L'appel d'une procédure étant particulier à chaque base de données supportant une telle fonctionnalité, JDBC propose une syntaxe unifiée qui sera transcrite par le pilote en un appel natif à la base de données. Cette syntaxe peut prendre plusieurs formes :
Un ensemble de méthode setXXX() (ou XXX représente un type primitif ou certains objets tels que String, Date, Object, ...) permet de fournir les valeurs de chaque paramètre défini dans la requête. Le premier paramètre de ces méthodes précise le numéro du paramètre dont la méthode va fournir la valeur. Le second paramètre précise cette valeur.
Un ensemble de méthode getXXX() (ou XXX représente un type primitif ou certains objets tels que String, Date, Object, ...) permet d'obtenir la valeur du paramètre de retour en fournissant la valeur 0 comme index de départ et un autre index pour les paramètres définis en entrée/sortie dans la procédure stockée.
Pour exécuter la requête, l'interface PreparedStatement propose deux méthodes :
JDBC permet de connaitre les avertissements et les exceptions générées par la base de données lors de l'exécution de requête.
La classe SQLException représente les erreurs émises par la base de données. Elle contient trois attributs qui permettent de préciser l'erreur :
La classe SQLException possède une méthode getNextException() qui permet d'obtenir les autres exceptions levées durant la requête. La méthode renvoie null une fois la dernière exception renvoyée.
| Exemple ( code Java 1.1 ) : |
package com.jmd.test.dej;
import java.sql.*;
public class TestJDBC3 {
private static void affiche(String message) {
System.out.println(message);
}
private static void arret(String message) {
System.err.println(message);
System.exit(99);
}
public static void main(java.lang.String[] args) {
Connection con = null;
ResultSet resultats = null;
String requete = "";
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
} catch (ClassNotFoundException e) {
arret("Impossible de charger le pilote jdbc:odbc");
}
affiche("connexion a la base de données");
try {
String DBurl = "jdbc:odbc:testDB";
con = DriverManager.getConnection(DBurl);
requete = "SELECT * FROM tableinexistante";
Statement stmt = con.createStatement();
resultats = stmt.executeQuery(requete);
affiche("parcours des données retournées");
boolean encore = resultats.next();
while (encore) {
System.out.print(resultats.getInt(1) + " : " + resultats.getString(2) +
" " + resultats.getString(3) + "(" + resultats.getDate(4) + ")");
System.out.println();
encore = resultats.next();
}
resultats.close();
} catch (SQLException e) {
System.out.println("SQLException");
do {
System.out.println("SQLState : " + e.getSQLState());
System.out.println("Description : " + e.getMessage());
System.out.println("code erreur : " + e.getErrorCode());
System.out.println("");
e = e.getNextException();
} while (e != null);
arret("");
} catch (Exception e) {
e.printStackTrace();
}
affiche("fin du programme");
System.exit(0);
}
}
La version 2.0 de l'API JDBC a été intégrée au JDK 1.2. Cette nouvelle version apporte plusieurs fonctionnalités très intéressantes dont les principales sont :
L'API JDBC 2.0 est séparée en deux parties :
Les possibilités de l'objet ResultSet dans la version 1.0 de JDBC sont très limitées : parcours séquentiel de chaque occurrence de la table retournée.
La version 2.0 apporte de nombreuses améliorations à cet objet : le parcours des occurrences dans les deux sens et la possibilité de faire des mises à jour sur une occurrence.
Concernant le parcours, il est possible de préciser trois modes de fonctionnement :
Il est aussi possible de préciser si le ResultSet peut être mise à jour ou non :
C'est à la création d'un objet de type Statement qu'il faut préciser ces deux modes. Si ces deux modes ne sont pas précisés, ce sont les caractéristiques de la version 1.0 de JDBC qui sont utilisées (TYPE_FORWARD_ONLY et CONCUR_READ_ONLY).
| Exemple (code jdbc 2.0) : |
Statement statement = connection.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_READ_ONLY);
ResultSet resultSet = statement.executeQuery("SELECT nom, prenom FROM employes");
Le support de ces fonctionnalités est optionnel pour un pilote. L'objet DatabaseMetadata possède la méthode supportsResultSetType() qui attend en paramètre une constante qui représente une caractéristique : la méthode renvoie un booléen qui indique si la caractéristique est supportée ou non.
A la création du ResultSet, le curseur est positionné avant la première occurrence à traiter. Pour se déplacer dans l'ensemble des occurrences, il y a toujours la méthode next() pour se déplacer sur le suivant mais aussi plusieurs autres méthodes pour permettre le parcours des occurrences en fonctions du mode utilisé dont les principales sont :
| Méthode | Rôle |
| boolean isBeforeFirst() | Renvoyer un booléen qui indique si la position courante du curseur se trouve avant la première ligne |
| boolean isAfterLast() | Renvoyer un booléen qui indique si la position courante du curseur se trouve après la dernière ligne |
| boolean isFirst() | Renvoyer un booléen qui indique si le curseur est positionné sur la première ligne |
| boolean isLast() | Renvoyer un booléen qui indique si le curseur est positionné sur la dernière ligne |
| boolean first() | Déplacer le curseur sur la première ligne |
| boolean last() | Déplacer le curseur sur la dernière ligne |
| boolean absolute(int) | Déplacer le curseur sur la ligne dont le numéro est fourni en paramètre à partir du début s'il est positif et à partir de la fin s'il est négatif. 1 déplace sur la première ligne, -1 sur la dernière, -2 sur l'avant dernière ... |
| boolean relative(int) | Déplacer le curseur du nombre de lignes fourni en paramètre par rapport à la position courante du curseur. Le paramètre doit être négatif pour se déplacer vers le début et positif pour se déplacer vers la fin. Avant l'appel de cette méthode, il faut obligatoirement que le curseur soit positionné sur une ligne. |
| boolean previous() | Déplacer le curseur sur la ligne précédente. Le boolen indique si la première occurrence est dépassée. |
| void afterLast() | Déplacer le curseur après la dernière ligne |
| void beforeFirst() | Déplacer le curseur avant la première ligne |
| int getRow() | Renvoyer le numéro de la ligne courante |
| Exemple (code jdbc 2.0) : |
Statement statement = connection.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_READ_ONLY);
ResultSet resultSet = statement.executeQuery(
"SELECT nom, prenom FROM employes ORDER BY nom");
resultSet.afterLast();
while (resultSet.previous()) {
System.out.println(resultSet.getString("nom")+
" "+resultSet.getString("prenom"));
}Durant le parcours d'un ResultSet, il est possible d'effectuer des mises à jour sur la ligne courante du curseur. Pour cela, il faut déclarer l'objet ResultSet comme acceptant les mises à jour. Avec les versions précédentes de JDBC, il fallait utiliser la méthode executeUpdate() avec une requête SQL.
Maintenant pour réaliser ces mises à jour, JDBC 2.0 propose de les réaliser via des appels de méthodes plutôt que d'utiliser des requêtes SQL.
| Méthode | Rôle |
| updateXXX(String, XXX) | permet de mettre à jour la colonne dont le nom est fourni en paramètre. Le type Java de cette colonne est XXX |
| updateXXX(int, XXX) | permet de mettre à jour la colonne dont l'index est fourni en paramètre. Le type Java de cette colonne est XXX |
| updateRow() | permet d'actualiser les modifications réalisées avec des appels à updateXXX() |
| boolean rowsUpdated() | indique si la ligne courante a été modifiée |
| deleteRow() | supprime la ligne courante |
| rowDeleted() | indique si la ligne courante est supprimée |
| moveToInsertRow() | permet de créer une nouvelle ligne dans l'ensemble de résultat |
| insertRow() | permet de valider la création de la ligne |
Pour réaliser une mise à jour dans la ligne courante désignée par le curseur, il faut utiliser une des méthodes updateXXX() sur chacun des champs à modifier. Une fois toutes les modifications faites dans une ligne, il faut appeler la méthode updateRow() pour reporter ces modifications dans la base de données car les méthodes updateXXX() ne font des mises à jour que dans le jeu de résultats. Les mises à jour sont perdues si un changement de ligne intervient avant l'appel à la méthode updateRow().
La méthode cancelRowUpdates() permet d'annuler toutes les modifications faites dans la ligne. L'appel à cette méthode doit être effectué avant l'appel à la méthode updateRow().
Pour insérer une nouvelle ligne dans le jeu de résultat, il faut tout d'abord appeler la méthode moveToInsertRow(). Cette méthode déplace le curseur vers un buffer dédié à la création d'une nouvelle ligne. Il faut alimenter chacun des champs nécessaires dans cette nouvelle ligne. Pour valider la création de cette nouvelle ligne, il faut appeler la méthode insertRow().
Pour supprimer la ligne courante, il faut appeler la méthode deleteRow(). Cette méthode agit sur le jeu de résultats et sur la base de données.
JDBC 2.0 permet de réaliser des mises à jour de masse en regroupant plusieurs traitements pour les envoyer en une seule fois au SGBD. Ceci permet d'améliorer les performances surtout si le nombre de traitements est important.
Cette fonctionnalité n'est pas obligatoirement supportée par le pilote. La méthode supportsBatchUpdates() de la classe DatabaseMetaData permet de savoir si elle est utilisable avec le pilote.
Plusieurs méthodes ont été ajoutées à l'interface Statement pour pouvoir utiliser les mises à jour de masse :
| Méthode | Rôle |
| void addBatch(String) | permet d'ajouter une chaîne contenant une requête SQL |
| int[] executeBatch() | permet d'exécuter toutes les requêtes. Elle renvoie un tableau d'entiers qui contient pour chaque requête, le nombre de mises à jour effectuées. |
| void clearBatch() | supprime toutes les requêtes stockées |
Lors de l'utilisation de batchupdate, il est préférable de positionner l'attribut autocommit à false afin de faciliter la gestion des transactions et le traitement d'une erreur dans l'exécution d'un ou plusieurs traitements.
| Exemple (code jdbc 2.0) : |
connection.setAutoCommit(false);
Statement statement = connection.createStatement();
for(int i=0; i<10 ; i++) {
statement.addBatch("INSERT INTO personne VALUES('nom"+i+"','prenom"+i+"')");
}
statement.executeBatch();Une exception particulière peut être levée en plus de l'exception SQLException lors de l'exécution d'une mise à jour de masse. L'exception SQLException est levée si une requête SQL d'interrogation doit être exécutée (requête de type SELECT). L'exception BatchUpdateException est levée si une des requêtes de mise à jour échoue.
L'exception BatchUpdateException possède une méthode getUpdateCounts() qui renvoie un tableau d'entiers contenant le nombre d'occurrences impactées par chaque requête réussie.
Ce package est une extension à l'API JDBC qui propose des fonctionnalités pour les développements coté serveur. C'est pour cette raison que cette extension est uniquement intégrée à J2EE.
Les principales fonctionnalités proposées sont :
DataSource et Rowset peuvent être utilisées directement. Les pools de connexions et les transactions distribuées sont utilisés par une implémentation dans les serveurs d'applications pour fournir ces services.
A partir de JDBC version 3.0 fournie avec Java 1.4, l'interface javax.sql.DataSource propose de fournir une meilleure alternative à la classe DriverManager pour assurer la création d'instance de connexions à une base de données.
Une implémentation de l'interface DataSource est une fabrique pour créer des connexions vers une source de données. Il existe plusieurs types d'implémentation de l'interface DataSource :
Les fournisseurs de pilotes doivent proposer au moins une implémentation de l'interface DataSource.
Une fois créé, un objet de type DataSource peut être enregistré dans un service de nommage. Il suffit alors d'utiliser JNDI pour obtenir une instance de classe DataSource.
| Exemple : |
// ...
Context ctx = new InitialContext();
DataSource ds = (DataSource) ctx.lookup("jdbc/applicationDB");
Connection con = ds.getConnection("admin", "mpadmin");
// ...Si aucun service de nommage n'est utilisable, il est possible de créer une instance de la classe implémentant DataSource proposée par le fournisseur du pilote JDBC.
| Exemple : |
package com.jmdoudoux.test.jdbc;
import java.sql.Connection;
import java.sql.SQLException;
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
public class TestDataSource {
public static void main(String[] args) {
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUser("root");
// dataSource.setPassword("password");
dataSource.setServerName("localhost");
dataSource.setPort(3306);
dataSource.setDatabaseName("mabdd");
try {
Connection connection = dataSource.getConnection();
// utilisation de la connexion
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Un pool de connexions permet de maintenir et réutiliser un ensemble de connexions établies vers une base de données. L'établissement d'une connexion est très coûteux en ressources. L'intérêt du pool de connexions est de limiter le nombre de ces créations et ainsi d'améliorer les performances surtout si le nombre de connexions est important.
 |
|
La suite de cette section sera développée dans une version future de ce document
|
Les connexions obtenues à partir d'un objet DataSource peuvent participer à une transaction distribuée.
|
|
|
La suite de cette section sera développée dans une version future de ce document
|
L'interface javax.sql.Rowset définit des objets qui permettent de manipuler les données d'une base de données.
Pour utiliser l'interface RowSet, il est nécessaire d'avoir une implémentation : l'implémentation de référence, une implémentation d'un tiers (par exemple le fournisseur du pilote JDBC) ou développée par soi-même.
L'implémentation d'un RowSet peut être de deux types :
Un RowSet de type déconnecté doit posséder un objet de type RowSetReader pour permettre la lecture des données et un objet de type RowSetWriter pour permettre l'enregistrement des données.
Avant Java 5, l'implémentation de référence de Rowset était téléchargeable séparément.
Java 5 fournit en standard une implémentation de référence des interfaces filles de l'interface RowSet définies dans la JSR 114 :
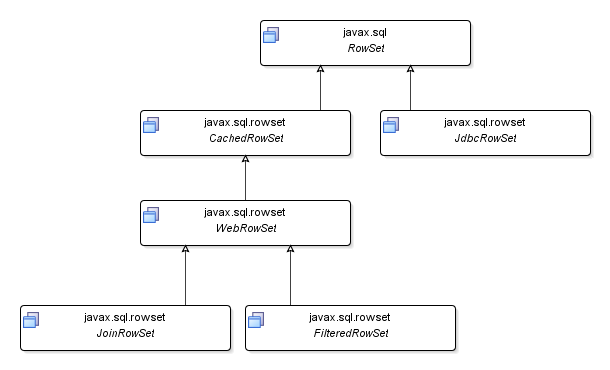
Ces interfaces filles sont définies dans le package javax.sql. Les implémentations sont nommées du nom de l'interface suivi de impl : elles sont regroupées dans le package javax.sql.rowset.
Les exemples de cette section utilisent une base de données JavaDB en mode embeded ou client/server selon les besoins. La table utilisée est composée de 3 champs :
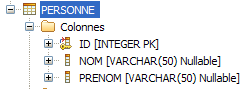
La table personne contient 3 occurrences

Un RowSet est un objet qui encapsule les données d'une source de données. L'implémentation d'un RowSet est un Javabean. Un RowSet peut obtenir lui-même ses données en se connectant à la base de données.
L'interface RowSet est définie depuis la version 2.0 de l'API JDBC. Elle hérite de l'interface ResultSet : elle encapsule donc des données tabulaires dont l'utilisation générale est similaire.
L'intérêt des objets de type RowSet est que ce sont des javabeans : ils gèrent donc des propriétés, sont sérialisables et peuvent mettre en oeuvre un mécanisme d'événements. Cela permet la mise en oeuvre de JDBC au travers d'un javabean.
Le fait que les RowSet soient des JavaBeans permet de les serialiser (pour des échanges à travers le réseau par exemple) ou de les utiliser directement avec d'autres Java Beans (avec les composants Swing dans une interface graphique par exemple).
Les implémentations de l'interface RowSet sont sérialisables ce qui facilite leur utilisation par rapport aux objets de type ResultSet qui ne le sont pas. Ils peuvent par exemple être utilisés par des EJB.
Cette interface propose un ensemble de propriétés pour permettre la connexion à une source de données. La propriété command contient la requête SQL qui permet d'obtenir les données. Ceci permet d'éviter la mise en oeuvre des différents objets de l'API JDBC (Connection et Statment notamment).
La méthode setURL() permet de préciser l'url JDBC utilisée lors de la connexion. Les méthodes setUsername() et setPassword() permettent de fournir le nom du user et son mot de passe pour la connexion.
La méthode setCommand() permet de préciser la requête qui sera exécutée pour obtenir les données.
La méthode execute() permet de réaliser les traitements pour charger les données (connexion à la base de données, exécution de la requête, parcours des données et éventuellement fermeture de la connexion selon l'implémentation du RowSet).
Le parcours des données se fait de la même façon que pour un ResultSet sachant qu'il peut toujours se faire dans les deux sens selon le paramétrage du RowSet (utilisation des méthodes first(), last(), next() et previous()).
Un RowSet peut être rempli de deux façons :
Une fois rempli, le RowSet peut toujours être parcouru dans les deux sens même si le pilote JDBC utilisé pour remplir les données ne permet pas cette fonctionnalité. La méthode size() permet de connaître le nombre d'occurrences contenues dans le RowSet.
Attention : lorsque le RowSet est rempli grâce à un ResultSet, il est nécessaire pour faire des modifications dans la table de la base de données de fournir au Rowset les informations de connexion et même la table concernée en utilisant la méthode setTableName().
Il est possible de préciser le niveau d'isolation de la transaction utilisée avec la connexion.
| Exemple : |
rs.setTransactionIsolation(
Connection.TRANSACTION_READ_COMMITTED);Les interfaces des spécifications de RowSet sont contenues dans le package javax.sql.rowset.
L'implémentation fournie avec le JDK est contenue dans le package com.sun.rowset : elle a été spécifiée par la JSR 114. Elle propose 5 RowSets standards : JdbcRowSet, CachedRowSet, WebRowSet, FilteredRowSet et JoinRowSet
Le JdbcRowSet fonctionne en mode connecté alors que CachedRowSet, WebRowSet, FilteredRowSet et JoinRowSet fonctionnent en mode déconnecté.
JdbcRowSet est un Rowset connecté qui encapsule un ResultSet.
Contrairement au ResultSet, JdbcRowSet permet d'encapsuler un ensemble de données et de proposer un parcours des données dans les deux sens même si l'implémentation du ResultSet utilisé pour le remplir ne le permet pas.
JdbcRowSet peut donc être parcouru dans les deux sens et peut être mis à jour.
Java 5 fournit une implémentation de cette interface avec la classe com.sun.rowset.JdbcRowSetImpl
La classe JdbcRowSetImpl possède deux constructeurs :
En utilisant le constructeur sans paramètre, il est nécessaire d'utiliser les méthodes utiles à la configuration de la connexion et de la requête à exécuter.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.ResultSet;
import javax.sql.rowset.JdbcRowSet;
import com.sun.rowset.JdbcRowSetImpl;
public class TestJdbcRowSet {
public static void main(String[] args) {
JdbcRowSet rs;
try {
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
rs = new JdbcRowSetImpl();
rs.setUrl("jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest");
rs.setUsername("APP");
rs.setPassword("");
rs.setCommand("SELECT * FROM PERSONNE");
rs.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs.execute();
while (rs.next()) {
System.out.println("nom : "
+ rs.getString("nom")
+ ", prenom : "
+ rs.getString("prenom"));
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}Il est possible d'utiliser des paramètres dans la requête passée en paramètre de la méthode setCommand(). Chacun des paramètres est défini avec le caractère « ? ». La valeur de chaque paramètre est fournie en utilisant une des méthodes setXXX() qui attend en paramètre l'index du paramètre et sa valeur.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.ResultSet;
import javax.sql.rowset.JdbcRowSet;
import com.sun.rowset.JdbcRowSetImpl;
public class TestJdbcRowSet2 {
public static void main(String[] args) {
JdbcRowSet rs;
try {
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
rs = new JdbcRowSetImpl();
rs.setUrl("jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest");
rs.setUsername("APP");
rs.setPassword("");
rs.setCommand("SELECT * FROM PERSONNE where id > ?");
rs.setInt(1, 2);
rs.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs.execute();
while (rs.next()) {
System.out.println("nom : "
+ rs.getString("nom")
+ ", prenom : "
+ rs.getString("prenom"));
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}En utilisant le constructeur attendant en paramètre un objet de type ResultSet, l'instance obtenue encapsule les données du ResultSet. Ces données peuvent être parcourues dans les deux sens et sont modifiables.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import javax.sql.rowset.JdbcRowSet;
import com.sun.rowset.JdbcRowSetImpl;
public class TestJdbcRowSet3 {
public static void main(String[] args) {
JdbcRowSet rs;
try {
Connection conn = null;
Statement stmt = null;
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
conn = DriverManager.getConnection(
"jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest;user=APP");
stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("select * from personne");
rs = new JdbcRowSetImpl(resultSet);
while (rs.next()) {
System.out.println("nom : "
+ rs.getString("nom")
+ ", prenom : "
+ rs.getString("prenom"));
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}Les données encapsulées dans le RowSet peuvent être mises à jour en fournissant la valeur ResultSet.CONCUR_UPDATABLE à la méthode setConcurrency(). Des méthodes updateXXX() héritées de la classe ResultSet permettent de mettre à jour une donnée en fonction de son type.
La méthode updateRow() permet de demander la mise à jour des données dans le RowSet.
La méthode commit() permet de demander la répercussion des modifications dans la base de données.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.ResultSet;
import javax.sql.rowset.JdbcRowSet;
import com.sun.rowset.JdbcRowSetImpl;
public class TestJdbcRowSet4 {
public static void main(String[] args) {
JdbcRowSet rs;
try {
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
rs = new JdbcRowSetImpl();
rs.setUrl("jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest");
rs.setUsername("APP");
rs.setPassword("");
rs.setCommand("SELECT * FROM PERSONNE");
rs.setConcurrency(ResultSet.CONCUR_UPDATABLE);
rs.execute();
rs.absolute(2);
rs.updateString("nom", "nom2 modifie");
rs.updateRow();
rs.commit();
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
L'interface CachedRowSet définit un RowSet déconnecté : la connexion à la base de données n'est maintenue que pour récupérer toutes les données. Toutes ces données sont stockées dans l'objet et la connexion est fermée. Il est alors possible de manipuler ces données (consultation et mise à jour). Les modifications peuvent alors être rendues persistantes en utilisant une nouvelle connexion dédiée à cette tâche.
Ceci peut permettre de réduire les ressources réseaux et serveurs mais introduit généralement des problématiques de synchronisation des mises à jour.
L'implémentation standard de l'interface CachedRowSet est proposée par la classe com.sun.rowset.CachedRowSetImpl. Cet objet maintient l'état des données qu'il encapsule en mémoire. Il a simplement besoin de la connexion pour remplir les données et plus tard au moment de rendre les modifications sur ces données persistantes.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.ResultSet;
import javax.sql.rowset.CachedRowSet;
import com.sun.rowset.CachedRowSetImpl;
public class TestCachedRowSet {
public static void main(String[] args) {
CachedRowSet rs;
try {
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
rs = new CachedRowSetImpl();
rs.setUrl("jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest");
rs.setCommand("SELECT * FROM PERSONNE");
rs.setUsername("APP");
rs.setPassword("");
rs.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs.execute();
while (rs.next()) {
System.out.println("nom : " + rs.getString("nom"));
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}La méthode populate() permet de remplir le rowSet avec les données d'un ResultSet.
Ce premier exemple n'est pas pertinent car il aurait été plus efficace d'utiliser directement le ResultSet. Par contre, le CachedRowSet devient intéressant dès qu'il faut faire des mises à jour sans être connecté à la base de données
Les mises à jour sont faites uniquement dans l'objet CachedRowSet. Pour reporter ces modifications dans la base de données, il faut utiliser la méthode acceptChanges(). Lors de l'appel à cette méthode, l'objet CachedRowSet se reconnecte à la base de données et effectue les mises à jour.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import javax.sql.rowset.CachedRowSet;
import com.sun.rowset.CachedRowSetImpl;
public class TestCachedRowSet3 {
public static void main(String[] args) {
CachedRowSet rs;
try {
Connection conn = null;
Statement stmt = null;
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
conn = DriverManager.getConnection(
"jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest;user=APP");
stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery"select * from personne");
rs = new CachedRowSetImpl();
rs.populate(resultSet);
rs.absolute(2);
rs.updateString("nom", "nom2");
rs.updateRow();
rs.acceptChanges(conn);
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}La propriété COMMIT_ON_ACCEPT_CHANGES est un booléen qui permet de préciser si un commit est réalisé automatiquement à la fin de la méthode acceptChanges(). La valeur par défaut est true. Si sa valeur est false, il faut explicitement faire appel à la méthode commit() pour valider la transaction.
Il est tout à fait possible que les données dans la base soient modifiées entre la récupération des données et leur mise à jour dans la base de données. Avant chaque mise à jour, CachedRowSet vérifie les données courantes dans la base avec leur valeur initiale lors du remplissage des données. Si une différence est détectée alors une exception de type SyncProviderException est levée.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import javax.sql.rowset.CachedRowSet;
import com.sun.rowset.CachedRowSetImpl;
public class TestCachedRowSet3 {
public static void main(String[] args) {
CachedRowSet rs;
try {
Connection conn = null;
Statement stmt = null;
Class.forName("org.apache.derby.jdbc.ClientDriver");
java.util.Properties props = new java.util.Properties();
props.put("user","APP");
props.put("password","APP");
conn = DriverManager.getConnection("jdbc:derby://localhost:1527/MaBaseDeTest", props);
stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("select * from personne");
rs = new CachedRowSetImpl();
rs.populate(resultSet);
System.out.println("debut attente");
Thread.sleep(60000);
// mise à jour de l'occurence dans la base de données par un outil externe
System.out.println("fin attente");
rs.absolute(2);
rs.updateString("nom", "nom2");
rs.updateRow();
rs.acceptChanges(conn);
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}| Résultat : |
debut attente
fin attente
javax.sql.rowset.spi.SyncProviderException: 3 conflicts while synchronizing
at com.sun.rowset.internal.CachedRowSetWriter.writeData(CachedRowSetWriter.java:373)
at com.sun.rowset.CachedRowSetImpl.acceptChanges(CachedRowSetImpl.java:862)
at com.sun.rowset.CachedRowSetImpl.acceptChanges(CachedRowSetImpl.java:921)
at com.jmdoudoux.test.rowset.TestCachedRowSet3.main(TestCachedRowSet3.java:43)Le CachedRowSet propose un mécanisme pour gérer ce cas de figure. Ce mécanisme impose de préciser au CachedRowSet la ou les colonnes qui représentent la clé ceci afin de lui permettre de faire correspondre ces occurrences avec celles de la base de données : c'est la méthode setKeyColumns() qui attend en paramètre un tableau entier contenant les index des colonnes.
Remarque : l'index des colonnes utilisées dans un CachedRowSet commence à 1 à non à 0.
Le traitement des conflits est à faire dans le traitement de l'exception de type SyncProviderException. Cette exception propose la méthode getSyncResolver() qui renvoie un objet de type SyncResolver.
L'objet de type SyncResolver permet d'obtenir les conflits détectés et de les résoudre en fonction des besoins. L'interface SyncResolver définit plusieurs méthodes :
Méthode |
Rôle |
Object getConflictValue() |
Retourne la valeur dans la base de données de l'occurrence courante du SyncResolver pour la colonne fournie en paramètre (index ou nom selon la surcharge utilisée). La valeur retournée est null pour une colonne qui n'est pas en conflit. |
int getStatus() |
Renvoie un entier qui précise le type d'opération tentée sur la base de données : DELETE_ROW_CONFLICT, INSERT_ROW_CONFLICT, UPDATE_ROW_CONFLICT ou NO_ROW_CONFLICT |
boolean nextConflict() |
Se déplace sur le prochain conflit s'il existe et renvoie true si le déplacement a eu lieu |
boolean previousConflict() |
Se déplace sur le conflit précédent s'il existe et renvoie true si le déplacement a eu lieu |
void setResolvedValue() |
Permet de définir la valeur dans la base de données de l'occurrence courante du SyncResolver pour la colonne fournie en paramètre (index ou nom selon la surcharge utilisée) |
Chaque fournisseur propose sa propre implémentation de SyncProvider. Les exemples de cette section utilisent l'implémentation de référence fournie avec le JDK à partir de la version 5.0. Cette implémentation propose un mode de gestion optimiste des accès concurrents (aucun verrou n'est posé sur les occurrences dans la base de données).
Il faut réaliser une itération sur les conflits en utilisant la méthode nextConflict().
La méthode getStatus() permet de connaître le type de mise jour tentée sur la base de données
La méthode getRow() héritée de l'interface ResultSet permet de connaître l'index de l'occurrence concernée par le conflit. Ceci permet de se déplacer dans le RowSet pour obtenir les nouvelles valeurs.
La méthode getConflictValue() est utilisée dans une itération sur les colonnes pour déterminer celles qui sont en conflit : dans ce cas la valeur retournée est différente de null.
A partir de la nouvelle valeur, de la valeur courante dans la base de données et du type de mises à jour, les traitements doivent déterminer la valeur à mettre dans la base de données.
Cette valeur est fournie en utilisant la méthode setResolvedValue().
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import javax.sql.rowset.CachedRowSet;
import com.sun.rowset.CachedRowSetImpl;
import javax.sql.rowset.spi.SyncProviderException;
import javax.sql.rowset.spi.SyncResolver;
public class TestCachedRowSet4 {
public static void main(String[] args) {
CachedRowSet rs=null;
try {
Connection conn = null;
Statement stmt = null;
Class.forName("org.apache.derby.jdbc.ClientDriver");
java.util.Properties props = new java.util.Properties();
props.put("user", "APP");
props.put("password", "APP");
conn = DriverManager.getConnection(
"jdbc:derby://localhost:1527/MaBaseDeTest", props);
stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("select * from personne");
rs = new CachedRowSetImpl();
rs.populate(resultSet);
rs.setTableName("PERSONNE");
// la première colonne compose la clé
rs.setKeyColumns(new int[] { 1 });
System.out.println("debut attente");
Thread.sleep(60000);
// mise à jour de l'occurrence dans la
// base de données par un outil externe
System.out.println("fin attente");
rs.absolute(2);
rs.updateString("nom", "nom2");
rs.updateRow();
rs.acceptChanges(conn);
rs.close();
} catch (SyncProviderException spe) {
SyncResolver resolver = spe.getSyncResolver();
try {
while (resolver.nextConflict()) {
if (resolver.getStatus() == SyncResolver.UPDATE_ROW_CONFLICT) {
int row = resolver.getRow();
rs.absolute(row);
int nbColonne = rs.getMetaData().getColumnCount();
for (int i = 1; i <= nbColonne; i++) {
if (resolver.getConflictValue(i) != null) {
Object valeur = rs.getObject(i);
Object valeurResolver = resolver.getConflictValue(i);
System.out.println("champ = "
+ rs.getMetaData().getColumnName(i)
+" , Valeur = "+valeur+"
, valeur dans la base="+valeurResolver);
// Determiner la valeur à mettre dans la base
// dans ce cas simplement la nouvelle valeur
resolver.setResolvedValue(i, valeur);
}
}
}
}
} catch (SQLException e) {
e.printStackTrace();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}| Résultat : |
debut attente
fin attente
champ = NOM , Valeur = nom2 , valeur dans la base=nom2 modL'interface CachedRowSet propose plusieurs méthodes pour annuler des mises à jour faites dans les données encapsulées (avant l'appel à la méthode acceptChanges()) :
Méthode |
Rôle |
void undoDelete() |
Annule l'opération de suppression de l'occurrence courante |
void undoInsert() |
Annule l'opération d'insertion de l'occurrence courante |
void undoUpdate() |
Annule l'opération de modification de l'occurence |
void restoreOriginal() |
Remettre l'ensemble des données à leur valeur originale (toutes les modifications sont perdues) et remet le curseur avant la première occurrence |
La méthode getOriginal() renvoie un ResultSet qui contient toutes les valeurs originales des données du RowSet.
Le stockage des données en mémoire rend le CachedRowSet inapproprié à une utilisation avec de gros volume de données. Dans ce cas, le CachedRowSet peut travailler en paginant sur des portions de données : l'ensemble des données est traité par page (une page contenant un certain nombre d'occurrences). La méthode setPageSize() permet de préciser le nombre maximum d'occurrences dans une page. La méthode nextPage() permet d'obtenir la page suivante. Ce mécanisme est particulièrement utile pour traiter de grosses quantités de données.
La méthode release() permet de supprimer toutes les données contenues dans le RowSet : attention son appel fait perdre toutes les modifications dans les données qui n'ont pas été reportées dans la base de données .
WebRowSet possède la capacité de lire ou d'écrire le contenu du RowSet au format XML. Cette faculté lui permet d'être utilisé pour échanger des données non pas sous une forme sérialisée mais sous la forme d'un document XML (par exemple dans une requête HTTP ou SOAP).
Dans l'implémentation standard, le document XML respecte le schéma :
http://java.sun.com/xml/ns/jdbc/webrowset.xsd
Le contenu au format XML d'un WebRowSet peut être exporté dans un flux quelconque : par exemple, l'envoi du contenu XML d'un WebRowSet dans une réponse d'une servlet.
Le document XML issu d'un WebRowSet possède un noeud racine <webRowSet> qui possède trois noeuds fils :
Chaque occurrence de données est stockée dans un tag <currentRow>. La valeur de chaque colonne est stockée dans un tag <columnValue>.
Les occurrences ajoutées sont stockées dans un tag <insertRow>.
Les occurrences modifiées sont stockées dans un tag <updateRow>. La valeur de chaque colonne modifiée est stockée dans un tag fils <updateValue>
Les occurrences supprimées sont stockées dans un tag <deleteRow>.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.ResultSet;
import javax.sql.rowset.WebRowSet;
import com.sun.rowset.WebRowSetImpl;
public class TestWebRowSet {
public static void main(String[] args) {
WebRowSet rs;
try {
Class.forName("org.apache.derby.jdbc.ClientDriver");
rs = new WebRowSetImpl();
rs.setUrl("jdbc:derby://localhost:1527/MaBaseDeTest");
rs.setCommand("SELECT * FROM PERSONNE");
rs.setUsername("APP");
rs.setPassword("APP");
rs.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs.execute();
rs.writeXml(System.out);
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}| Résultat : |
<?xml version="1.0"?>
<webRowSet
xmlns="http://java.sun.com/xml/ns/jdbc"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/jdbc
http://java.sun.com/xml/ns/jdbc/webrowset.xsd">
<properties>
<command>SELECT * FROM PERSONNE</command>
<concurrency>1007</concurrency>
<datasource><null/></datasource>
<escape-processing>true</escape-processing>
<fetch-direction>1000</fetch-direction>
<fetch-size>0</fetch-size>
<isolation-level>2</isolation-level>
<key-columns>
</key-columns>
<map>
</map>
<max-field-size>0</max-field-size>
<max-rows>0</max-rows>
<query-timeout>0</query-timeout>
<read-only>true</read-only>
<rowset-type>ResultSet.TYPE_SCROLL_INSENSITIVE</rowset-type>
<show-deleted>false</show-deleted>
<table-name>PERSONNE</table-name>
<url>jdbc:derby://localhost:1527/MaBaseDeTest</url>
<sync-provider>
<sync-provider-name>com.sun.rowset.providers.RIOptimisticProvider</sync-provider-name>
<sync-provider-vendor>Sun Microsystems Inc.</sync-provider-vendor>
<sync-provider-version>1.0</sync-provider-version>
<sync-provider-grade>2</sync-provider-grade>
<data-source-lock>1</data-source-lock>
</sync-provider>
</properties>
<metadata>
<column-count>3</column-count>
<column-definition>
<column-index>1</column-index>
<auto-increment>false</auto-increment>
<case-sensitive>false</case-sensitive>
<currency>false</currency>
<nullable>0</nullable>
<signed>true</signed>
<searchable>true</searchable>
<column-display-size>11</column-display-size>
<column-label>ID</column-label>
<column-name>ID</column-name>
<schema-name>APP</schema-name>
<column-precision>10</column-precision>
<column-scale>0</column-scale>
<table-name>PERSONNE</table-name>
<catalog-name></catalog-name>
<column-type>4</column-type>
<column-type-name>INTEGER</column-type-name>
</column-definition>
<column-definition>
<column-index>2</column-index>
<auto-increment>false</auto-increment>
<case-sensitive>true</case-sensitive>
<currency>false</currency>
<nullable>1</nullable>
<signed>false</signed>
<searchable>true</searchable>
<column-display-size>50</column-display-size>
<column-label>NOM</column-label>
<column-name>NOM</column-name>
<schema-name>APP</schema-name>
<column-precision>50</column-precision>
<column-scale>0</column-scale>
<table-name>PERSONNE</table-name>
<catalog-name></catalog-name>
<column-type>12</column-type>
<column-type-name>VARCHAR</column-type-name>
</column-definition>
<column-definition>
<column-index>3</column-index>
<auto-increment>false</auto-increment>
<case-sensitive>true</case-sensitive>
<currency>false</currency>
<nullable>1</nullable>
<signed>false</signed>
<searchable>true</searchable>
<column-display-size>50</column-display-size>
<column-label>PRENOM</column-label>
<column-name>PRENOM</column-name>
<schema-name>APP</schema-name>
<column-precision>50</column-precision>
<column-scale>0</column-scale>
<table-name>PERSONNE</table-name>
<catalog-name></catalog-name>
<column-type>12</column-type>
<column-type-name>VARCHAR</column-type-name>
</column-definition>
</metadata>
<data>
<currentRow>
<columnValue>1</columnValue>
<columnValue>nom1</columnValue>
<columnValue>prenom1</columnValue>
</currentRow>
<currentRow>
<columnValue>2</columnValue>
<columnValue>nom2</columnValue>
<columnValue>prenom2</columnValue>
</currentRow>
<currentRow>
<columnValue>3</columnValue>
<columnValue>nom3</columnValue>
<columnValue>prenom3</columnValue>
</currentRow>
</data>
</webRowSet>La méthode readXml() permet de remplir l'objet WebRowSet avec un fichier XML par exemple précédemment créé grâce à la méthode writeXml().
L'interface FilteredRowSet qui hérite de l'interface WebRowSet permet de mettre en oeuvre un filtre par programmation sans utiliser SQL.
FilteredRowSet est particulièrement utile car il permet de filtrer un ensemble de données sans avoir à effectuer une requête sur la base de données avec le filtre.
Le filtre est encapsulé dans une classe qui implémente l'interface Predicate. Dans cette classe, il faut redéfinir les méthodes evaluate() qui renvoit un booléen précisant si l'occurrence est conservée ou non par le filtre.
La méthode evaluate() acceptant en paramètre un objet de type RowSet est utilisée par l'objet FilteredRowSet lors du parcours de ses occurrences.
Les surcharges de la méthode evaluate() acceptant un objet et une colonne (par index ou par nom) sont utilisées par l'objet FilteredRowSet pour déterminer si une valeur d'une colonne correspond au filtre.
| Exemple (Java 5) : ne conserver que les personnes dont le nom se termine par 2 |
package com.jmdoudoux.test.rowset;
import java.sql.SQLException;
import javax.sql.RowSet;
import javax.sql.rowset.Predicate;
public class PersonnePredicate implements Predicate {
public boolean evaluate(Object value, int column) throws SQLException {
// inutilisé dans cet exemple
return false;
}
public boolean evaluate(Object value, String columnName) throws SQLException {
// inutilisé dans cet exemple
return false;
}
public boolean evaluate(RowSet rowset) {
try {
String nom = rowset.getString("nom");
if (nom.endsWith("2")) {
return true;
} else {
return false;
}
} catch (SQLException sqle) {
return false;
}
}
}Le filtre est précisé au FilteredRowSet en utilisant la méthode setFilter() qui attend en paramètre une instance de la classe Predicate.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.ResultSet;
import javax.sql.rowset.FilteredRowSet;
import com.sun.rowset.FilteredRowSetImpl;
public class TestFilteredRowSet {
public static void main(String[] args) {
FilteredRowSet rs;
try {
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
rs = new FilteredRowSetImpl();
rs.setUrl("jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest");
rs.setCommand("SELECT * FROM PERSONNE");
rs.setUsername("APP");
rs.setPassword("");
rs.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs.setFilter(new PersonnePredicate());
rs.execute();
while (rs.next()) {
System.out.println("nom : " + rs.getString("nom"));
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}| Résultat : |
nom : nom2
L'interface JoinRowSet qui hérite de l'interface WebRowSet permet de faire des jointures entre plusieurs instances de l'interface Joinable. Les interfaces qui héritent de Joinable sont : CachedRowSet, FilteredRowSet, JdbcRowSet, JoinRowSet, WebRowSet.
JoinRowSet peut être particulièrement utile si les données des RowSet qu'il encapsule appartiennent à des sources de données différentes
Pour utiliser un JoinRowSet, il faut en créer une instance et utiliser la méthode addRowSet() pour ajouter les instances de l'interface Joinable à utiliser dans la jointure. La méthode adddRowSet() possède plusieurs surcharges qui permettent de préciser l'instance de Joinable et la ou les clés utilisées lors de la jointure.
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.ResultSet;
import javax.sql.rowset.CachedRowSet;
import javax.sql.rowset.JoinRowSet;
import com.sun.rowset.CachedRowSetImpl;
import com.sun.rowset.JoinRowSetImpl;
public class TestJoinRowSetRowSet {
public static void main(String[] args) {
CachedRowSet rs1;
CachedRowSet rs2;
JoinRowSet rs;
try {
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
rs1 = new CachedRowSetImpl();
rs1.setUrl("jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest");
rs1.setCommand("SELECT * FROM PERSONNE");
rs1.setUsername("APP");
rs1.setPassword("");
rs1.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs1.execute();
rs2 = new CachedRowSetImpl();
rs2.setUrl("jdbc:derby:C:/Program Files/Java/jdk1.6.0/db/MaBaseDeTest");
rs2.setCommand("SELECT * FROM ADRESSE");
rs2.setUsername("APP");
rs2.setPassword("");
rs2.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs2.execute();
rs = new JoinRowSetImpl();
rs.addRowSet(rs1,1);
rs.addRowSet(rs2,1);
while (rs.next()) {
System.out.println("nom : " + rs.getString("nom")+", rue : " + rs.getString("rue"));
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}| Résultat : |
nom : nom3, rue : rue3
nom : nom2, rue : rue2
nom : nom1, rue : rue1La méthode setJoinType() permet de préciser le type de jointure à effectuer en utilisant les constantes définies dans l'interface JoinRowSet : CROSS_JOIN, FULL_JOIN, INNER_JOIN (par défaut), LEFT_OUTER_JOIN et RIGHT_OUTER_JOIN. Les implémentations n'ont pas d'obligation à supporter tous les types de jointures : l'utilisation d'un type de jointure non supporté par l'implémentation lève une exception de type SQLException.
L'interface RowSetListener permet de gérer certains événements d'un RowSet. Le modèle d'événement des Javabeans est mis en oeuvre au travers de ce listener de type RowSetListener et d'un événement de type RowSetEvent.
Les méthodes addRowSetListener() et removeRowSetListener() de l'interface RowSet permettent respectivement d'enregistrer et de supprimer un listener
L'interface RowSetListener définit trois méthodes :
| Exemple (Java 5) : |
package com.jmdoudoux.test.rowset;
import java.sql.ResultSet;
import javax.sql.RowSetEvent;
import javax.sql.RowSetListener;
import javax.sql.rowset.JdbcRowSet;
import com.sun.rowset.JdbcRowSetImpl;
public class TestRowSetListener {
public static void main(String[] args) {
JdbcRowSet rs;
try {
Class.forName("org.apache.derby.jdbc.ClientDriver");
rs = new JdbcRowSetImpl();
rs.setUrl("jdbc:derby://localhost:1527/MaBaseDeTest");
rs.setCommand("SELECT * FROM PERSONNE");
rs.setUsername("APP");
rs.setPassword("APP");
rs.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs.addRowSetListener(new RowSetListener() {
public void cursorMoved(RowSetEvent event) {
System.out.println("L'evenement cursorMoved est emis");
}
public void rowChanged(RowSetEvent event) {
System.out.println("L'evenement rowChanged est emi"");
}
public void rowSetChanged(RowSetEvent event) {
System.out.println("L'evenement rowSetChanged est emis");
}
});
rs.execute();
while (rs.next())
System.out.println("nom : " + rs.getString("nom"));
rs.close();
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public TestRowSetListener() {
JdbcRowSet rs;
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
rs = new JdbcRowSetImpl();
rs.setUrl("jdbc:oracle:thin:@localhost:1521:test");
rs.setCommand("SELECT * FROM article");
rs.setUsername("test");
rs.setPassword("test");
rs.setConcurrency(ResultSet.CONCUR_READ_ONLY);
rs.addRowSetListener(new RowSetListener() {
public void cursorMoved(RowSetEvent event) {
System.out.println("L'evenement cursorMoved est emis");
}
public void rowChanged(RowSetEvent event) {
System.out.println("L'evenement rowChanged est emis");
}
public void rowSetChanged(RowSetEvent event) {
System.out.println("L'evenement rowSetChanged est emis");
}
});
rs.execute();
while (rs.next())
System.out.println("libelle : " + rs.getString("libelle"));
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}| Résultat : |
L'evenement rowSetChanged est emis
L'evenement cursorMoved est emis
nom : nom1
L'evenement cursorMoved est emis
nom : nom2
L'evenement cursorMoved est emis
nom : nom3
L'evenement cursorMoved est emis
Les spécifications de l'API JDBC version 3.0, disponible depuis mai 2002, sont issues des travaux de la JSR 0054 et sont directement intégrées dans la plate-forme J2SE 1.4.
Ces spécifications ont été développées en tenant compte de plusieurs points : conserver une compatibilité avec la version précédente de l'API, assurer une meilleure interaction avec la technologie JCA, le support de SQL 99, ...
Cette version propose plusieurs améliorations dont les savepoints, le support de SQL 99, la récupération des identifiants générés détaillées dans les sections suivantes.
JDBC n'est qu'une spécification : l'implémentation réalisée au travers des pilotes peut proposer tout ou uniquement une partie de ces fonctionnalités.
Avant la version 3.0, lors de l'utilisation d'une instance de l'interface CallableStatement, pour assigner une valeur à un paramètre, il fallait obligatoirement utiliser son index. Il est dorénavant possible d'utiliser un nom pour un paramètre et d'utiliser ce nom pour mettre à jour sa valeur.
L'interface CallableStatement s'est vu rajouter des surcharges des méthodes getXXX() et setXXX() attendant en premier paramètre une chaîne de caractères qui va contenir le nom du paramètre.
Cette fonctionnalité est intéressante notamment pour l'appel de procédures stockées qui possèdent des valeurs par défaut pour certains paramètres. Il est ainsi possible de ne fournir que les valeurs voulues lors de l'appel.
Deux nouveaux types sont supportés : java.sql.Types.DATALINK pour des url vers des ressources externes et java.sql.Types.BOOLEAN pour les booléens. Les valeurs d'une donnée de ces types sont obtenues en utilisant respectivement les méthodes getURL() et getBoolean() de la classe ResultSet.
La plupart des bases de données relationnelles proposent des fonctionnalités pour permettre la génération d'une valeur, généralement auto incrémentée dans un champ d'une base de données, permettant la génération d'un identifiant unique. Ceci est très pratique pour définir un champ qui sera la clé primaire d'une table. Cependant avant la version 3.0 de JDBC, il était nécessaire d'effectuer une lecture après l'insertion des données.
Ceci pose souvent des problèmes notamment pour arriver à utiliser une clause where dans la requête d'interrogation qui soit sûre de renvoyer les données de la ligne insérée. De plus, cela impose de réaliser une opération supplémentaire sur la base de données.
Il est maintenant possible d'obtenir facilement la valeur d'un identifiant généré par la base de données lors de l'insertion d'une nouvelle occurrence dans une table. Attention, le support de cette fonctionnalité par le pilote est optionnel.
Il suffit de préciser lors de l'appel à la méthode executeUpdate() de l'interface Statement la valeur Statement.RETURN_GENERATED_KEYS au paramètre autoGeneratedKeys de type int.
Pour obtenir la valeur de la clé ou des clés générées, il suffit d'appeler la méthode getGeneratedKeys() de l'instance de l'interface Statement utilisée pour exécuter la mise à jour : le ResultSet retourné par cette méthode contient un champ pour chaque champ généré par la base de données.
| Exemple : |
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
public class TestJdbc101 {
public static void main(java.lang.String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet resultats = null;
String requete = "";
// chargement du pilote
try {
Class.forName("com.mysql.jdbc.Driver").newInstance();
} catch (Exception e) {
e.printStackTrace();
System.exit(99);
}
try {
String DBurl = "jdbc:mysql://localhost:3306/testjava";
con = DriverManager.getConnection(DBurl);
stmt = con.createStatement();
stmt.executeUpdate(
"INSERT INTO personne (nom, prenom, taille) "
+ "values ('nom1', 'prenom1', 174)",
Statement.RETURN_GENERATED_KEYS);
int idGenere = -1;
resultats = stmt.getGeneratedKeys();
if (resultats.next()) {
idGenere = resultats.getInt(1);
} else {
System.out.println("Impossible d'obtenir la valeur generee");
}
resultats.close();
resultats = null;
System.out.println("valeur id genere = " + idGenere);
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (resultats != null) {
try {
resultats.close();
} catch (SQLException ex) {
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException ex) {
}
}
if (con != null) {
try {
con.close();
} catch (SQLException ex) {
}
}
}
System.exit(0);
}
}
| Résultat : |
valeur id genere = 1
Pour utiliser les transactions, il est nécessaire de demander la désactivation du mode auto-commit de la connexion. Il faut appeler la méthode setAutoCommit() avec le paramètre false de l'instance de la classe Connection qui encapsule la connexion à la base de données.
La transaction peut alors être validée ou annulée en totalité avec respectivement les méthodes commit() et rollback().
Avant la version 3.0 de JDBC, il n'était possible que de valider toutes les opérations ou d'annuler toutes les opérations de la transaction. Il n'était pas possible de réaliser des validations ou des annulations d'un sous-ensemble d'opérations de la transaction.
Avec la version 3.0 de JDBC, les savepoints permettent de définir des points nommés entre l'exécution de deux opérations de la transaction. Ce savepoint peut être considéré comme un marqueur. Toutes les opérations réalisées depuis la définition de ce marqueur peuvent être annulées sans que les opérations réalisées avant le marqueur ne soient annulées.
Pour définir un savepoint, il suffit d'appeler la méthode setSavePoint() de la classe Connection. Cette méthode renvoie un objet de type Savepoint qu'il faut passer en paramètre de la méthode rollback() pour annuler les opérations réalisées depuis la définition du savepoint.
| Exemple : |
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Savepoint;
import java.sql.Statement;
public class TestJdbc102 {
public static void main(java.lang.String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet resultats = null;
String requete = "";
// chargement du pilote
try {
Class.forName("com.mysql.jdbc.Driver").newInstance();
} catch (Exception e) {
e.printStackTrace();
System.exit(99);
}
try {
String DBurl = "jdbc:mysql://localhost:3306/test";
con = DriverManager.getConnection(DBurl);
stmt = con.createStatement();
con.setAutoCommit(false);
con.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);
stmt.executeUpdate("UPDATE personne SET nom = 'nom1 modif1' WHERE id=1");
Savepoint svpt = con.setSavepoint("savepoint_1");
stmt.executeUpdate("UPDATE personne SET nom = 'nom1 modif2' WHERE id=1");
con.rollback(svpt);
con.commit();
// creation et execution de la requête
requete = "SELECT * FROM personne";
stmt = con.createStatement();
resultats = stmt.executeQuery(requete);
ResultSetMetaData rsmd = resultats.getMetaData();
int nbCols = rsmd.getColumnCount();
boolean encore = resultats.next();
while (encore) {
for (int i = 1; i <= nbCols; i++)
System.out.print(resultats.getString(i) + " ");
System.out.println();
encore = resultats.next();
}
resultats.close();
resultats = null;
} catch (SQLException e) {
e.printStackTrace();
if (con != null) {
try {
con.rollback();
} catch (SQLException ex) {
}
}
} finally {
if (resultats != null) {
try {
resultats.close();
} catch (SQLException ex) {
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException ex) {
}
}
if (con != null) {
try {
con.close();
} catch (SQLException ex) {
}
}
}
System.exit(0);
}
}
Dans l'exemple ci-dessus, seule la première mise à jour est effective suite au commit de la transaction.
Il est maintenant possible d'utiliser un pool d'objets de type PreparedStatement. Cette mise en pool est transparente pour le développeur car elle est gérée par le pool de connexions.
Lors de la suppression d'un objet PreparedStatement, celui-ci est mis dans le pool pour permettre une réutilisation et ainsi évite une recompilation d'un nouvel objet de ce type.
Ceci permet d'éviter la répétition des traitements coûteux effectués lors de la création d'un objet PreparedStatement (vérification et optimisation de la requête par la base de données).
Un pilote compatible avec la version 3.0 de JDBC va ainsi mettre en place un pool pour ces objets : à leur fermeture, les objets sont remis dans le pool. Lorsque le PreparedStatement est réutilisé, l'objet est repris du pool plutôt que recréé.
La version 3.0 de JDBC propose un contrôle plus précis sur les paramètres du pool de connexions tel que la taille du pool, le nombre minimum et maximum de connexions qu'il contient, ...
L'utilisation de ces propriétés peut améliorer les performances sans modification dans le code qui met en oeuvre l'API JDBC. En effet, elles affectent des mécanismes transparents pour le développeur et il n'est pas recommandé de modifier ces paramètres via l'API (il est préférable de les configurer au travers du serveur d'applications).
Ceci permet aussi de standardiser ces propriétés et de rendre la configuration moins dépendante des fournisseurs de pilotes.
|
Propriété |
Description |
|
maxStatements |
Précise le nombre maximum de statements gérés par le pool La valeur 0 indique une désactivation du mécanisme de mise en pool |
|
initialPoolSize |
Précise le nombre de connexions créées par le pool à sa création |
|
minPoolSize |
Précise le nombre de connexions minimum gérées par le pool. La valeur 0 précise que les connexions seront créées en fonction des besoins. |
|
maxPoolSize |
Précise le nombre maximum de connexions gérées par le pool. La valeur 0 indique qu'il n'y a pas de maximum. |
|
maxIdleTime |
Précise la durée en secondes avant qu'une connexion inutilisée du pool ne soit fermée. La valeur 0 indique qu'il n'y aura pas de cloture des connexions. |
La méthode getType Info() permet d'obtenir un ResultSet qui contient la liste des types de données supportés par la base de données et le pilote.
La version 2 de l'API JDBC ne permet à un objet Statement de n'avoir qu'un seul ResultSet ouvert à un instant donné.
La version 3 de l'API propose une fonctionnalité pour outrepasser cette limitation. Par défaut, la méthode execute() ferme le ResultSet retourné par sa précédente exécution. L'interface Statement a été enrichie d'une nouvelle méthode nommée getMoreResults(). Cette méthode attend un paramètre qui peut prendre les valeurs :
|
CLOSE_ALL_RESULTS |
Les ResultSets précédemment ouverts sont fermés à l'appel de la méthode |
|
CLOSE_CURRENT_RESULT |
L'objet ResultSet courant est fermé lors de l'appel à la méthode |
|
KEEP_CURRENT_RESULT |
L'objet ResultSet courant reste ouvert lors de l'appel à la méthode |
Elle retourne un booléen qui vaut true s'il y a encore au moins un ResultSet à traiter.
Cette fonctionnalité peut être pratique notamment pour utiliser des procédures stockées qui renvoient plusieurs curseurs de données.
Un ResultSet est automatiquement fermé à la fin d'une transaction. JDBC 3.0 propose une fonctionnalité qui permet de préciser si dans ce cas le ResultSet doit être maintenu ouvert ou fermé.
Une version surchargée des méthodes createStatement(), prepareCall() et prepareStatement() de la classe Connection attend en paramètre un entier nommé resultSetHoldability qui peut prendre les valeurs :
|
ResultSet.HOLD_CURSORS_OVER_COMMIT |
maintient l'objet ouvert après l'exécution d'un commit d'une transaction |
|
ResultSet.CLOSE_CURSORS_AT_COMMIT |
ferme l'objet après l'exécution d'un commit d'une transaction |
La norme SQL99 propose les types de données BLOB (Binary Large OBject) et CLOB (Character Large OBject) pour permettre la gestion des données de grandes tailles respectivement de type binaire ou chaîne de caractères.
JDBC 2.0 ne proposait que des fonctionnalités pour lire des données de ces types. Chaque pilote souhaitant proposer des fonctionnalités pour les mettre à jour le faisait de façon particulière : ceci rend le code dépendant du fournisseur du pilote.
JDBC 3.0 propose en standard un mécanisme pour mettre à jour les champs de type BLOB et CLOB.
L'API propose dans l'interface java.sql.Blob une nouvelle méthode setBinaryStream() qui renvoie un objet de type OutputStream.
L'API propose dans l'interface java.sql.Clob plusieurs méthodes pour modifier le contenu du champ :
L'exemple ci-dessous utilise la table suivante :

| Exemple : |
import java.io.BufferedReader;
import java.io.IOException;
import java.io.Writer;
import java.sql.Clob;
import java.sql.Connection;
import java.sql.Date;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class TestJdbc103 {
public static void main(java.lang.String[] args) {
Connection con = null;
Statement stmt = null;
PreparedStatement pstmt = null;
ResultSet resultats = null;
String requete = "";
// chargement du pilote
try {
Class.forName("com.mysql.jdbc.Driver").newInstance();
} catch (Exception e) {
e.printStackTrace();
System.exit(99);
}
try {
String DBurl = "jdbc:mysql://localhost:3306/test";
con = DriverManager.getConnection(DBurl);
pstmt = con
.prepareStatement("insert into messages (dthr, contenu) Values (?, ?) ");
pstmt.setDate(1, new Date(new java.util.Date().getTime()));
Clob contenu = con.createClob();
Writer writer = contenu.setCharacterStream(1);
writer.write("contenu du message 1");
writer.close();
pstmt.setClob(2, contenu);
pstmt.executeUpdate();
// creation et execution de la requête
requete = "SELECT id, dthr, contenu FROM messages where id=1";
stmt = con.createStatement();
resultats = stmt.executeQuery(requete);
resultats.next();
contenu = resultats.getClob(3);
System.out.println("contenu=" + ClobToString(contenu));
} catch (SQLException e) {
e.printStackTrace();
if (con != null) {
try {
con.rollback();
} catch (SQLException ex) {
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (resultats != null) {
try {
resultats.close();
} catch (SQLException ex) {
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException ex) {
}
}
if (pstmt != null) {
try {
pstmt.close();
} catch (SQLException ex) {
}
}
if (con != null) {
try {
con.close();
} catch (SQLException ex) {
}
}
}
System.exit(0);
}
public static String ClobToString(Clob cl) throws IOException, SQLException {
StringBuffer resultat = new StringBuffer("");
if (cl != null) {
String ligne = null;
BufferedReader br = new BufferedReader(cl.getCharacterStream());
while ((ligne = br.readLine()) != null)
resultat.append(ligne);
}
return resultat.toString();
}
}
MySQL est une des bases de données open source les plus populaires.
Il suffit de télécharger le fichier mysql-3.23.49-win.zip sur le site www.mysql.com, de décompresser ce fichier dans un répertoire et d'exécuter le fichier setup.exe


Il faut ensuite télécharger le pilote ODBC, MyODBC-3.51.03.exe, et l'exécuter

Cette section est une présentation rapide de quelques fonctionnalités de base pour pouvoir utiliser MySQL. Pour un complément d'informations sur toutes les possibilités de MySQL, consultez la documentation de cet excellent outil.
Pour utiliser MySQL, il faut s'assurer que le serveur est lancé sinon il faut exécuter la commande
c:\mysql\bin\mysqld-max
Pour exécuter des commandes SQL, il faut utiliser l'outil c:\mysql\bin\mysql. Cet outil est un interpréteur de commandes en mode console.
| Exemple : pour voir les databases existantes |
mysql>show databases;
+----------+
| Database |
+----------+
| mysql |
| test |
+----------+
2 rows in set (0.00 sec)Un des premières choses à faire, c'est de créer une base de données qui va recevoir les différentes tables.
| Exemple : Pour créer une nouvelle base de données nommée "testjava" |
mysql> create database testjava;
Query OK, 1 row affected (0.00 sec)
mysql>use testjava;
Database changedCette nouvelle base de données ne contient aucune table. Il faut créer la ou les tables utiles aux développements.
| Exemple : Création d'une table nommée personne contenant trois champs : nom, prenom et date de naissance |
mysql> show tables;
Empty set (0.06 sec)
mysql> create table personne (nom varchar(30), prenom varchar(30), datenais date
);
Query OK, 0 rows affected (0.00 sec)
mysql>show tables;
+--------------------+
| Tables_in_testjava |
+--------------------+
| personne |
+--------------------+
1 row in set (0.00 sec)Pour voir la définition d'une table, il faut utiliser la commande DESCRIBE :
| Exemple : voir la définition de la table |
mysql> describe personne;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| nom | varchar(30) | YES | | NULL | |
| prenom | varchar(30) | YES | | NULL | |
| datenais | date | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)Cette table ne contient aucun enregistrement. Pour ajouter un enregistrement, il faut utiliser la commande SQL insert.
| Exemple : insertion d'une ligne dans la table |
mysql> select * from personne;
Empty set (0.00 sec)
mysql> insert into personne values ('Nom 1','Prenom 1','1970-08-11');
Query OK, 1 row affected (0.05 sec)
mysql> select * from personne;
+-------+----------+------------+
| nom | prenom | datenais |
+-------+----------+------------+
| Nom 1 | Prenom 1 | 1970-08-11 |
+-------+----------+------------+
1 row in set (0.00 sec)Il existe des outils graphiques libres ou commerciaux pour faciliter l'administration et l'utilisation de MySQL.
Sous Windows, il est possible d'utiliser une base de données MySQL avec Java en utilisant ODBC. Dans ce cas, il faut définir une source de données ODBC sur la base de données et l'utiliser avec le pilote de type 1 fourni en standard avec J2SE.
Dans le panneau de configuration, cliquez sur l'icône " Source de données ODBC ".
Le plus simple est de créer une source de données Systeme qui pourra être utilisée par tous les utilisateurs en cliquant sur l'onglet " DSN système "

Pour ajouter une nouvelle source de données, il suffit de cliquer sur le bouton "Ajouter ... ". Une boîte de dialogue permet de sélectionner le type de pilote qui sera utilisé par la source de données.

Il faut sélectionner le pilote MySQL et cliquer sur le bouton "Finish".

Une nouvelle boîte de dialogue permet de renseigner les informations sur la base de données à utiliser notamment le nom de DSN et le nom de la base de données.
Pour vérifier si la connexion est possible, il suffit de cliquer sur le bouton " Test Data Source "

Cliquer sur Ok pour fermer la fenêtre et cliquer sur Ok pour valider les paramètres et créer la source de données.

La source de données est créée.
Pour utiliser la source de données, il faut écrire et tester une classe Java. La seule particularité est l'utilisation du pont JDBC-ODBC comme pilote JDBC et l'URL spécifique à ce pilote qui contient le nom de la source de données définie.
| Exemple : |
import java.sql.*;
public class TestJDBC10 {
private static void affiche(String message) {
System.out.println(message);
}
private static void arret(String message) {
System.err.println(message);
System.exit(99);
}
public static void main(java.lang.String[] args) {
Connection con = null;
ResultSet resultats = null;
String requete = "";
// chargement du pilote
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
} catch (ClassNotFoundException e) {
arret("Impossible de charger le pilote jdbc:odbc");
}
//connection à la base de données
affiche("connection a la base de donnees");
try {
String DBurl = "jdbc:odbc:test_java";
con = DriverManager.getConnection(DBurl);
} catch (SQLException e) {
arret("Connection à la base de donnees impossible");
}
//creation et execution de la requête
affiche("creation et execution de la requête");
requete = "SELECT * FROM personne";
try {
Statement stmt = con.createStatement();
resultats = stmt.executeQuery(requete);
} catch (SQLException e) {
arret("Anomalie lors de l'execution de la requête");
}
//parcours des données retournees
affiche("parcours des données retournees");
try {
ResultSetMetaData rsmd = resultats.getMetaData();
int nbCols = rsmd.getColumnCount();
boolean encore = resultats.next();
while (encore) {
for (int i = 1; i <= nbCols; i++)
System.out.print(resultats.getString(i) + "");
System.out.println();
encore = resultats.next();
}
resultats.close();
} catch (SQLException e) {
arret(e.getMessage());
}
affiche("fin du programme");
System.exit(0);
}
}| Résultat : |
C:\$user>javac TestJDBC10.java
C:\$user>java TestJDBC10
connexion a la base de donnees
creation et execution de la requ_te
parcours des donn_es retournees
Nom 1 Prenom 1 1970-08-11
fin du programme
mm.mysql est un pilote JDBC de type IV développé sous licence LGPL par Mark Matthews pour accéder à une base de données MySQL.
Le téléchargement du pilote JDBC se fait sur le site http://mmmysql.sourceforge.net/ . Le fichier mm.mysql-2.0.14-you-must-unjar-me.jar contient les sources et les binaires du pilote.
Pour utiliser cette archive, il faut la décompresser, par exemple dans le répertoire d'installation de mysql.
Il faut s'assurer que les fichiers jar sont accessibles dans le classpath ou les préciser manuellement lors de la compilation et de l'exécution comme dans l'exemple ci-dessous.
| Exemple : |
import java.sql.*;
public class TestJDBC11 {
private static void affiche(String message) {
System.out.println(message);
}
private static void arret(String message) {
System.err.println(message);
System.exit(99);
}
public static void main(java.lang.String[] args) {
Connection con = null;
ResultSetresultats = null;
String requete = "";
// chargement du pilote
try {
Class.forName("org.gjt.mm.mysql.Driver").newInstance();
} catch (Exception e) {
arret("Impossible decharger le pilote jdbc pour mySQL");
}
//connexion a la base de données
affiche("connexion a la base de donnees");
try {
String DBurl = "jdbc:mysql://localhost/testjava";
con = DriverManager.getConnection(DBurl);
} catch (SQLException e) {
arret("Connexion a la base de donnees impossible");
}
//creation et execution de la requête
affiche("creation et execution dela requête");
requete = "SELECT * FROM personne";
try {
Statement stmt = con.createStatement();
resultats = stmt.executeQuery(requete);
} catch (SQLException e) {
arret("Anomalie lors de l'execution de la requete");
}
//parcours des données retournees
affiche("Parcours des donnees retournees");
try {
ResultSetMetaData rsmd = resultats.getMetaData();
int nbCols = rsmd.getColumnCount();
boolean encore = resultats.next();
while (encore) {
for (int i = 1; i <= nbCols; i++)
System.out.print(resultats.getString(i) + "");
System.out.println();
encore = resultats.next();
}
resultats.close();
} catch (SQLException e) {
arret(e.getMessage());
}
affiche("fin du programme");
System.exit(0);
}
}Le programme est identique au précédent utilisant ODBC sauf :
| Résultat : |
C:\$user>javac -classpath c:\j2sdk1.4.0-rc\jre\lib\mm.mysql-2.0.14-bin.jar TestJDBC11.java
C:\$user>
C:\$user>java -cp .;c:\j2sdk1.4.0-rc\jre\lib\mm.mysql-2.0.14-bin.jar TestJDBC11
connexion a la base de donnees
creation et execution de la requ_te
Parcours des donnees retournees
Nom 1 Prenom 1 1970-08-11
fin du programme
Les opérations d'accès à une base de données sont généralement nombreuses et source de nombreux ralentissements dans une application : il est donc nécessaire de procéder à des opérations de tuning sur ces traitements.
Ces opérations doivent être prises en compte dès le début d'un projet.
Comme pour toutes opérations de tuning, des outils de test de charge et de monitoring sont nécessaires pour pouvoir quantifier les performances des accès aux bases de données.
Le choix des outils utilisés peut grandement influencer les performances notamment :
Voici quelques recommandations de base qui permettent d'améliorer les performances regroupées par catégories.
La qualité du pilote JDBC est importante notamment en termes de rapidité, type de pilote, version de JDBC supportée, ...
Le type du pilote influe grandement sur les performances :
Il est donc préférable d'utiliser des pilotes de type 4 ou 3.
Il peut être intéressant de tester le pilote proposé par le fournisseur de la base de données mais aussi de tester des pilotes fournis par des tiers.
Il est préférable d'utiliser un pilote qui supporte la version la plus récente de JDBC.
Plusieurs best practices sont communément mises en oeuvre lors de l'utilisation de JDBC :
Il est préférable de maintenir une connexion ouverte et la réutiliser plutôt que de créer une nouvelle connexion et la fermer à chaque opération sur la base de données. C'est ce que permettent les pools de connexions.
Si les accès sont en lecture seule, il est préférable d'utiliser la méthode setReadOnly() de l'objet Connection en lui passant le paramètre true pour permettre au pilote de faire des optimisations.
Il est possible de paramétrer la quantité de données reçues de la base de données en utilisant les méthodes setMaxRows(), setMaxFieldSize() et SetFetchSize() de l'interface Statement.
La méthode nativeSQL() de la classe Connection permet d'obtenir la requête SQL native qui sera envoyée par le pilote à la base de données.
La création d'une connexion vers une base de données est coûteuse en temps et en ressources. Le rôle d'un pool de connexions est de maintenir un certain nombre de connexions ouvertes à disposition de l'application dans un cache et de les proposer au besoin.
Un pool peut être fourni par l'environnement d'exécution (par exemple un serveur d'application) soit être fourni par un tiers (il en existe plusieurs en open source) soit être développé de toute pièce.
L'utilisation d'un pool de connexions est sûrement l'action la plus efficace pour des applications qui utilisent les accès à la base de données de façon importante.
Il peut être important de configurer correctement le pool de connexions utilisé notamment la taille du pool pour limiter la création et la destruction des connexions.
Un pool de connexions peut fonctionner selon deux modes principaux :
Une bonne configuration et utilisation des objets de type ResultSet peuvent améliorer les performances.
Il faut utiliser le curseur adapté aux besoins :
Il faut éviter d'utiliser la méthode getObject() mais utiliser la méthode getXXX() adaptée au type d'une donnée pour extraire sa valeur.
Il est intéressant d'utiliser les PreparedStatement notamment pour les requêtes qui sont exécutées plusieurs fois avec les mêmes paramètres ou des paramètres différents (les valeurs des données fournies à la requête peuvent être paramétrées).
Une même requête exécutée avec des paramètres différents nécessite certains traitements identiques par la base de données : une partie de ces traitements est réalisé une et une seule fois lors de la première utilisation d'un PreparedStatement par une connexion. Les appels suivants avec la même connexion sont plus rapides puisque ces traitements ne sont pas refaits.
A partir de JDBC 3.0, les objets de type PreparedStatement peuvent être stockés dans un cache partagé des connexions d'un même pool : ceci améliore les performances car cela évite d'avoir certaines opérations mises en oeuvre à chaque appel (vérification de la syntaxe, optimisation des chemins d'accès et des plans d'exécution, ...).
Par exemple pour obtenir un nombre d'occurrences, il est préférable d'effectuer une requête SQL contenant un count(*) plutôt que de parcourir un ResultSet avec un compteur incrémenté à chaque itération.
Il est possible d'utiliser les procédures stockées pour les traitements lourds ou complexes sur la base de données plutôt que d'effectuer plusieurs appels à la base de données pour réaliser les mêmes traitements côté Java. Les performances sont accrues car les traitements sont réalisés par la base de données ce qui évite notamment des échanges réseaux.
Attention ceci n'est vrai que pour des traitements complexes : une simple requête SQL s'exécutera plus rapidement qu'en appelant une procédure stockée qui contient simplement la requête.
Il est préférable d'utiliser les marqueurs de paramètres dans les requêtes des objets de type Statement plutôt que de les passer en dur dans la requête.
Il est possible d'exécuter de nombreuses requêtes en utilisant les BatchUpdates : ceci permet de regrouper plusieurs opérations sur la base de données en un seul appel.
Pour mettre en oeuvre le BatchUpdates, il faut :
Il faut minimiser les conflits engendrés par les transactions (deadlocks notamment)
Par défaut, une connexion est en mode autocommit ce qui implique la création et la validation d'une transaction à chaque opération.
L'autocommit qui est le mode par défaut pour une connexion implique une nouvelle transaction pour chaque opération réalisée.
Il est donc préférable d'inhiber l'autocommit en passant false à la méthode setAutoCommit() et de réaliser plusieurs opérations dans une même transaction avant de la valider par un commit. Il ne faut cependant pas laisser une transaction ouverte trop longtemps pour éviter des problèmes de concurrence d'accès : une transaction posant des verrous sur la base de données, il est important de minimiser le temps d'exécution d'une transaction.
Le choix du mode de transaction influe sur les performances. Il faut choisir en fonction des besoins car plus le niveau d'isolation est important moins les performances sont bonnes : TRANSACTION_NONE, TRANSACTION_READ_UNCOMMITED, TRANSACTION_READ_COMMITED, TRANSACTION_REPEATABLE_READ, TRANSACTION_SERIALIZABLE
La méthode setTransactionIsolation() permet de préciser le mode de transaction à utiliser.
Il est préférable d'éviter d'utiliser les transactions distribuées autant que possible.
JDBC 3.0 propose des fonctionnalités pour améliorer les performances notamment au niveau du cache des connexions et des objets de type PreparedStatement, les objets RowSet, ...
Le pool de connexions et le pool de Statement travaillent ensemble pour qu'une connexion puisse utiliser un objet Statement du pool qui a été créé par une autre connexion. Ainsi un objet de type Statement n'est plus lié à une connexion mais partagé entre les connexions d'un même pool ce qui améliore encore les performances.
Un objet de typeCacheRowSet permet d'obtenir des données, de libérer la connexion, de les modifier en local et de les resynchroniser dans la base de données avec une nouvelle connexion. Il n'est donc pas nécessaire d'avoir une connexion ouverte durant tous les traitements. Il faut cependant prêter une attention particulière aux éventuels conflits de mise à jour.
Les savePoints sont assez gourmands en ressources : il est nécessaire de libérer ces ressources en utilisant la méthode releaseSavePoint() de la classe Connection.
Les optimisations côté Java sont importantes mais il est aussi nécessaire de procéder à des optimisations côté base de données, généralement réalisées par un DBA dans des structures de taille moyenne ou importante.
Les quelques optimisations fournies ci-dessous sont assez généralistes : elles ne dispensent pas d'effectuer des optimisations spécifiques à la base de données utilisée.
L'utilisation d'un cache pour stocker les données peut éviter des accès à la base de données. Ceci est particulièrement adapté pour des données lues de façon répétitives ou dont les valeurs évoluent très peu ou pas du tout (données en lecture seule, données de références, ...).
Il faut cependant faire attention à la durée de vie des objets dans le cache afin d'éviter des problèmes de rafraichissement de données.
Il ne faut pas mettre en cache les objets de type ResultSet : il faut les parcourir, stocker les données dans des objets du domaine et mettre ces objets dans le cache.
