| Développons en Java 2.30 | |
| Copyright (C) 1999-2022 Jean-Michel DOUDOUX | (date de publication : 15/06/2022) |
|
|
 |
 |
 |
| Niveau : | |
Javadoc est un outil fourni avec le JDK pour permettre la génération d'une documentation technique à partir du code source.
Cet outil génère une documentation au format HTML à partir du code source Java et des commentaires particuliers qu'il contient. Un exemple concret de l'utilisation de cet outil est la documentation du JDK qui est générée grâce à Javadoc.
Cette documentation contient :
L'intérêt de ce système est de conserver dans le même fichier le code source et les éléments de la documentation qui lui sont associés. Il propose donc une auto-documentation des fichiers sources de façon standard.
Ce chapitre contient plusieurs sections :
Javadoc s'appuie sur le code source et sur un type de commentaires particuliers pour obtenir des données supplémentaires des éléments qui composent le code source.
L'outil Javadoc utilise plusieurs types de fichiers sources pour générer la documentation :
En fonction des paramètres fournis à l'outil, ce dernier recherche les fichiers source .java concernés. Les sources de ces fichiers sont scannées pour déterminer leurs membres, extraire les informations utiles et établir un ensemble de références croisées.
Le résultat de cette recherche peut être enrichi avec des commentaires dédiés insérés dans le code avant chaque élément qu'ils enrichissent. Ces commentaires doivent immédiatement précéder l'entité qu'ils concernent (classe, interface, méthode, constructeur ou champ). Seul le commentaire qui précède l'entité est traité lors de la génération de la documentation.
Ces commentaires suivent des règles précises. Le format de ces commentaires commence par /** et se termine par */. Il peut contenir un texte libre et des balises particulières.
Le commentaire peut être sur une ou plus généralement sur plusieurs lignes. Les caractères d'espacement (espace et tabulation) qui précèdent le premier caractère * de chaque ligne du commentaire ainsi que le caractère lui-même sont ignorés lors de la génération. Ceci permet d'utiliser le caractère * pour aligner le contenu du commentaire.
| Exemple : |
/** Description */ |
Le format général de ces commentaires est :
| Exemple : |
/**
* Description
*
* @tag1
* @tag2
*/ |
Le commentaire doit commencer par une description de l'élément qui peut utiliser plusieurs lignes. La première phrase de cette description est utilisée par javadoc comme résumé. Cette première phrase se termine par un caractère '.' suivi d'un séparateur (espace ou tabulation ou retour chariot) ou à la rencontre du premier tag Javadoc.
Le texte du commentaire doit être au format HTML : les tags HTML peuvent donc être utilisés pour enrichir le formatage de la documentation. Il est donc aussi nécessaire d'utiliser les entités d'échappement pour certains caractères contenus dans le texte tels que < ou >. Il ne faut surtout pas utiliser les tags de titres <Hn> et le tag du séparateur horizontal <HR> car ils sont utilisés par Javadoc pour structurer le document.
| Exemple : |
/**
* Description de la classe avec des <b>mots en gras</b>
*/ |
L'utilisation de balises de formatage HTML est particulièrement intéressante pour formater une description un peu longue en faisant usage notamment du tag <p> pour définir des paragraphes ou du tag <code> pour encadrer un extrait de code.
A partir du JDK 1.4, si la ligne ne commence pas par un caractère *, alors les espaces ne sont plus supprimés (ceci permet par exemple de conserver l'indentation d'un morceau de code contenu dans un tag HTML <PRE>).
Le commentaire peut ensuite contenir des tags Javadoc particuliers qui commencent obligatoirement par le caractère @ et doivent être en début de ligne. Ces tags doivent être regroupés ensemble. Un texte qui suit cet ensemble de tags est ignoré.
Les tags prédéfinis par Javadoc permettent de fournir des informations plus précises sur des composants particuliers de l'élément (auteur, paramètres, valeur de retour, ...). Ces tags sont définis pour un ou plusieurs types d'éléments.
Les tags sont traités de façon particulière par Javadoc. Il existe deux types de tags :
Attention un caractère @ en début de ligne est interprété comme un tag. Si un tel caractère doit apparaître en début de ligne dans la description, il faut utiliser la séquence d'échappement HTML @
Le texte associé à un block tag suit le tag et se termine à la rencontre du tag suivant ou de la fin du commentaire. Ce texte peut donc s'étendre sur plusieurs lignes.
Les tags inline peuvent être utilisés n'importe où dans le commentaire de documentation.
L'outil Javadoc traite de façon particulière les tags dédiés insérés dans le commentaire de documentation. Javadoc définit plusieurs tags qui permettent de préciser certains composants de l'élément décrit de façon standardisée. Ces tags commencent tous par le caractère arobase @.
Il existe deux types de tags :
Les block tags doivent obligatoirement doivent être placés en début de ligne (après d'éventuels blancs et un caractère *).
Attention : les tags sont sensibles à la casse.
Pour pouvoir être interprétés, les tags standards doivent obligatoirement commencer en début de ligne.
| Tag | Rôle | version du JDK |
| @author | permet de préciser le ou les auteurs de l'élément | 1.0 |
| {@code} | 1.5 |
|
| @deprecated | permet de préciser qu'un élément est déprécié | 1.1 |
| {@docRoot} | représente le chemin relatif du répertoire principal de génération de la documentation | 1.3 |
| @exception | permet de préciser une exception qui peut être levée par l'élément | 1.0 |
| {@inheritDoc} | 1.4 |
|
| {@link} | permet d'insérer un lien vers un élément de la documentation dans n'importe quel texte | 1.2 |
| {@linkplain} | 1.4 |
|
| {@literal} | 1.5 |
|
| @param | permet de documenter un paramètre de l'élément | 1.0 |
| @return | permet de fournir une description de la valeur de retour d'une méthode qui en possède une : inutile donc de l'utiliser sur une méthode qui retourne void. | 1.0 |
| @see | permet de préciser un élément en relation avec l'élément documenté | 1.0 |
| @serial | 1.2 |
|
| @serialData | 1.2 |
|
| @serialField | 1.2 |
|
| @since | permet de préciser depuis quelle version l'élément a été ajouté | 1.1 |
| @throws | identique à @exception | 1.2 |
| @version | permet de préciser le numéro de version de l'élément | 1.0 |
| {@value} | 1.4 |
Ces tags ne peuvent être utilisés que pour commenter certaines entités.
| Entité | Tags utilisables |
| Toutes | @see, @since, @deprecated, {@link}, {@linkplain}, {@docroot} |
| Overview (fichier overview.html) | @see, @since, @author, @version, {@link}, {@linkplain}, {@docRoot} |
| Package (fichier package.html) | @see, @since, @serial, @author, @version, {@link}, {@linkplain}, {@docRoot} |
| Classes et Interfaces | @see, @since, @deprecated, @serial, @author, @version, {@link}, {@linkplain}, {@docRoot} |
| Constructeurs et méthodes | @see, @since, @deprecated, @param, @return, @throws, @exception, @serialData, {@link}, {@linkplain}, {@inheritDoc}, {@docRoot} |
| Champs | @see, @since, @deprecated, @serial, @serialField, {@link}, {@linkplain}, {@docRoot}, {@value} |
Chacun des tags sera détaillé dans les sections suivantes.
Par convention, il est préférable de regrouper les tags identiques ensemble.
Le tag @author permet de préciser le ou les auteurs d'une entité.
La syntaxe de ce tag est la suivante :
@author texte
Le texte qui suit la balise est libre. Le doclet standard crée une section "Author" qui contient le texte du tag.
Pour préciser plusieurs auteurs, il est possible d'utiliser un seul ou plusieurs tag @author dans un même commentaire. Dans le premier cas, le contenu du texte est repris intégralement dans la section. Dans le second cas, la section contient le texte de chaque tag séparé par une virgule et un espace.
Exemple :
@author Pierre G.
@author Denis T., Sophie D.
Ce tag n'est utilisable que dans les commentaires d'ensemble, d'une classe ou d'une interface.
A partir du JDK 1.4, il est possible au travers du paramètre -tag de préciser que le tag @author peut être utilisé sur d'autres membres
Exemple :
-tag author:a:"Author:"
Le tag @deprecated permet de préciser qu'une entité ne devrait plus être utilisée même si elle fonctionne toujours : il permet donc de donner des précisions sur un élément déprécié (deprecated).
La syntaxe de ce tag est la suivante :
@deprecated texte
Il est recommandé de préciser depuis quelle version l'élément est déprécié et de fournir dans le texte libre une description de la solution de remplacement, si elle existe, ainsi qu'un lien vers une entité de substitution.
Le doclet standard crée une section "Deprecated" avec l'explication dans la documentation.
Remarque : Ce tag est particulier car il est le seul reconnu par le compilateur : celui-ci prend note de cet attribut lors de la compilation pour permettre d'en informer les utilisateurs. Lors de la compilation, l'utilisation d'entités marquées avec le tag @deprecated générera un avertissement (warning) de la part du compilateur.
Exemple Java 1.1 :
@deprecated Remplacé par setMessage
@see #setMessage
Exemple Java 1.2 :
@deprecated Remplaçé par {@link #setMessage}
Ces tags permettent de documenter une exception levée par la méthode ou le constructeur décrit par le commentaire.
Syntaxe :
@exception nom_exception description
Les tags @exception et @throws sont similaires.
Ils sont suivis du nom de l'exception puis d'une courte description des raisons de la levée de cette dernière. Il faut utiliser autant de tag @exception ou @throws qu'il y a d'exceptions. Ce tag doit être utilisé uniquement pour un élément de type méthode.
Il ne faut pas mettre de séparateur particulier comme un caractère '-' entre le nom et la description puisque l'outil en ajoute un automatiquement. Il est cependant possible d'aligner les descriptions de plusieurs paramètres en utilisant des espaces afin de faciliter la lecture.
Exemple :
@exception java.io.FileNotFoundException le fichier n'existe pas
Le doclet standard crée une section "Throws" qui regroupe les exceptions : l'outil recherche le nom pleinement qualifié de chaque exception si c'est simplement leur nom qui est précisé dans le tag.
Exemple extrait de la documentation de l'API du JDK :

Le tag @param permet de documenter un paramètre d'une méthode ou d'un constructeur. Ce tag doit être utilisé uniquement pour un élément de type constructeur ou méthode.
La syntaxe de ce tag est la suivante :
@param nom_paramètre description du paramètre
Ce tag est suivi du nom du paramètre (ne pas utiliser le type) puis d'une courte description de ce dernier. A partir de Java 5, il est possible d'utiliser le type du paramètre entre les caractères < et > pour une classe ou une méthode.
Il ne faut pas mettre de séparateur particulier comme un caractère '-' entre le nom et la description puisque l'outil en ajoute un automatiquement. Il est cependant possible d'aligner les descriptions de plusieurs paramètres en utilisant des espaces afin de faciliter la lecture.
Il faut utiliser autant de tag @param que de paramètres dans la signature de l'entité concernée. La description peut être contenue sur plusieurs lignes.
Le doclet standard crée une section "Parameters" qui regroupe les tags @param du commentaire. Il génère pour chaque tag une ligne dans cette section avec son nom et sa description dans la documentation.
Exemple extrait de la documentation de l'API du JDK :

Par convention les paramètres doivent être décrits dans leur ordre dans la signature de la méthode décrite
Exemple :
@param nom nom de la personne
@param message chaîne de caractères à traiter. Si cette valeur est <code>null</code> alors une exception est levée
Exemple 2 : /** * @param <E> Type des elements stockés dans la collection */
public interface List<E> extends Collection<E> { }
Le tag @return permet de fournir une description de la valeur de retour d'une méthode qui en possède une.
La syntaxe de ce tag est la suivante :
@return description_de_la_valeur_de retour_de_la_méthode
Il ne peut y avoir qu'un seul tag @return par commentaire : il doit être utilisé uniquement pour un élément de type méthode qui renvoie une valeur.
Avec le doclet standard, ce tag crée une section "Returns" qui contient le texte du tag. La description peut tenir sur plusieurs lignes.
Exemple extrait de la documentation de l'API du JDK :

Il ne faut pas utiliser ce tag pour des méthodes ne possédant pas de valeur de retour (void).
Exemple:
@return le nombre d'occurrences contenues dans la collection
@return <code>true</code> si les traitements sont correctement exécutés sinon <code>false</code>
Le tag @see permet de définir un renvoi vers une autre entité incluse dans une documentation de type Javadoc ou vers une url.
La syntaxe de ce tag est la suivante :
@see référence à une entité suivie d'un libellé optionnel ou lien ou texte entre double quote
@see package
@see package.Class
@see class
@see #champ
@see class#champ
@see #method(Type,Type,...)
@see class#method(Type,Type,...)
@see package.class#method(Type,Type,...)
@see <a href="..."> ... </a>
@see " ... "
Le tag génère un lien vers une entité ayant un lien avec celle documentée.
Il peut y avoir plusieurs tags @see dans un même commentaire.
L'entité vers laquelle se fait le renvoi peut être un package, une classe, une méthode ou un lien vers une page de la documentation. Le nom de la classe doit être de préférence pleinement qualifié.
Le caractère # permet de séparer une classe d'un de ses membres (champ, constructeur ou méthode). Attention : il ne faut surtout pas utiliser le caractère "." comme séparateur entre une classe ou une interface et le membre précisé.
Pour indiquer une version surchargée particulière d'une méthode ou d'un constructeur, il suffit de préciser la liste des types d'arguments de la version concernée.
Il est possible de fournir un libellé optionnel à la suite de l'entité. Ce libellé sera utilisé comme libellé du lien généré : ceci est pratique pour forcer un libellé à la place de celui généré automatiquement (par défaut le nom de l'entité).
Si le tag est suivi d'un texte entre double cote, le texte est simplement repris avec les cotes sans lien.
Si le tag est suivi d'un tag HTML <a>, le lien proposé par ce tag est repris intégralement.
Le doclet standard crée une section "See Also" qui regroupe les tags @see du commentaire en les séparant par une virgule et un espace.
Exemple extrait de la documentation de l'API du JDK :

Remarque : pour insérer un lien n'importe où dans le commentaire, il faut utiliser le tag {@link}
Exemple :
@see String
@see java.lang.String
@see String#equals
@see java.lang.Object#wait(int)
@see MaClasse nouvelle classe
@see <a href="test.htm">Test</a>
@see "Le dossier de spécification détaillée"
Ce tag permet de définir des liens vers d'autres éléments de l'API.
Le tag @since permet de préciser un numéro de version de la classe ou de l'interface à partir de laquelle l'élément décrit est disponible. Ce tag peut être utilisé avec tous les éléments.
La syntaxe de ce tag est la suivante :
@since texte
Le texte qui représente le numéro de version est libre. Le doclet standard crée une section "Since" qui contient le texte du tag.
Exemple extrait de la documentation de l'API du JDK :

Par convention, pour limiter le nombre de sections Since dans la documentation, lorsqu'une nouvelle classe ou interface est ajoutée, il est préférable de mettre un tag @since sur le commentaire de la classe et de ne pas le reporter sur chacun de ses membres. Le tag @since est utilisé sur un membre uniquement lors de l'ajout du membre.
Dans la documentation de l'API Java, ce tag précise depuis qu'elle version du JDK l'entité décrite est utilisable.
Exemple :
@since 2.0
Le tag @version permet de préciser un numéro de version. Ce tag doit être utilisé uniquement pour un élément de type classe ou interface.
La syntaxe de ce tag est la suivante :
@version texte
Le texte qui suit la balise est libre : il devrait correspondre à la version courante de l'entité documentée. Le doclet standard crée une section "Version" qui contient le texte du tag.
Il ne devrait y avoir qu'un seul tag @version dans un commentaire.
Par défaut, le doclet standard ne prend pas en compte ce tag : il est nécessaire de demander sa prise en compte avec l'option -version de la commande javadoc.
Exemple :
@version 1.00
Ce tag permet de créer un lien vers un autre élément de la documentation.
La syntaxe de ce tag est la suivante :
{@link package.class#membre texte }
Le mode de fonctionnement de ce tag est similaire au tag @see : la différence est que le tag @see crée avec le doclet standard un lien dans la section "See also" alors que le tag {@link} crée un lien à n'importe quel endroit de la documentation.
Si une accolade fermante doit être utilisée dans le texte du tag il faut utiliser la séquence d'échappement }.
Exemple :
Utiliser la {@link #maMethode(int) nouvelle méthode}
Ce tag permet d'afficher la valeur d'un champ.
La syntaxe de ce tag est la suivante :
{@value}
{@value package.classe#champ_static}
Lorsque le tag {@value} est utilisé sans argument avec un champ static, le tag est remplacé par la valeur du champ.
Lorsque le tag {@value} est utilisé avec comme argument une référence à un champ static, le tag est remplacé par la valeur du champ précisé. La référence utilisée avec ce tag suit la même forme que celle du tag @see
Exemple :
{@value}
{@value #MA_CONSTANTE}
Ce tag permet d'afficher un texte qui ne sera pas interprété comme de l'HTML.
La syntaxe de ce tag est la suivante :
{@literal texte}
Le contenu du texte est repris intégralement sans interprétation. Notamment les caractères < et > ne sont pas interprétés comme des tags HTML.
Pour afficher du code, il est préférable d'utiliser le tag {@code}
Exemple :
{@literal 0<b>10}
Ce tag permet de créer un lien vers un autre élément de la documentation dans une police normale.
Ce tag est similaire au tag @link. La différence réside dans la police d'affichage.
Ce tag permet de demander explicitement la recopie de la documentation de l'entité de la classe mère la plus proche correspondante.
La syntaxe de ce tag est la suivante:
{@inheritDoc}
Ce tag permet d'éviter le copier/coller de la documentation d'une entité.
Il peut être utilisé :
Ce tag représente le chemin relatif à la documentation générée.
La syntaxe de ce tag est la suivante :
{@docRoot}
Ce tag est pratique pour permettre l'inclusion de fichiers dans la documentation.
Exemple :
<a href="{@docRoot}/historique.htm">Historique</a>
Ce tag permet d'afficher un texte dans des tags <code> ... </code> qui ne sera pas interprété comme de l'HTML.
La syntaxe de ce tag est la suivante :
{@code texte}
Le contenu du texte est repris intégralement sans interprétation. Notamment les caractères < et > ne sont pas interprétés comme des tags HTML.
Le tag {@code texte} est équivalent à <code>{@literal texte}</code>
Exemple :
{@code 0<b>10}
Il est pratique d'inclure des fragments de code source dans les commentaires de documentation pour illustrer des cas d'utilisation.
Historiquement, cela se fait avec un tag {@code ...} ou <pre>{@code ...}</pre>.
| Exemple ( code Java 5.0 ) : |
/**
* Point d'entrée de l'application.
*
* Le code invoque l'instruction :
* <pre>{@code
* System.out.println("Hello World");
* }</pre>
*/
public static void main(String[] args) {
// ...
} |
Le Doclet standard génère de l'HTML qui reflète précisément le corps du tag {@code ...}, y compris l'indentation sans valider le code.
Le but de la JEP 413, ajoutée en Java 18, est de faciliter l'inclusion de fragments d'exemples de code dans la Javadoc. La JEP 413 ajoute une fonctionnalité à l'outil JavaDoc pour améliorer la prise en charge des exemples de code dans la documentation des API en utilisant le tag @snippet.
Le tag {@snippet ...} remplace les précédentes techniques de manière plus pratique et offre plus de possibilités et de flexibilité.
Le tag @snippet permet de définir un fragment de code qui sera inclus dans la documentation générée. Ce fragment peut être en ligne (inclus dans le tag lui-même) ou externe (lu à partir d'un fichier source).
Dans un fragment de code, il est possible d'utiliser des tags de marquage dans des commentaires de marquages pour formatter ou remplacer des portions de texte (@highlight et @replace) ou lier une portion texte à d'autres éléments (@link).
La configuration d'un fragment se fait grâce à des attributs sous la forme de paires nom=valeur qui suivent le tag @snippet, chacune séparée de la précédente par un caractère d'espacement (espace, tabulation, retour chariot, ...).
Le nom d'un attribut est un simple identifiant. Une valeur peut être entourée d'une paire de simple ou double quote. Les séquences d'échappement ne sont pas supportées dans les valeurs.
L'attribut id permet de définir un identifiant au fragment utilisable via l'API et dans le code HTML généré. Le Doclet standard n'utilise pas directement cet attribut.
| Exemple ( code Java 18 ) : |
/**
* {@snippet id="main" :
* public static void main(String[] args) {
* System.out.println("Hello World");
* }
* }
*/
|
L'attribut lang permet de préciser le type de contenu du fragment (source Java ou d'un autre langage, properties, XML, Json, texte, ...). Pour un fragment en ligne (in line), la valeur par défaut est java. Pour un fragment externe, la valeur est déterminée en fonction de l'extension du fichier.
Le Doclet standard de Java 18 supporte les valeurs java et properties.
| Exemple ( code Java 18 ) : |
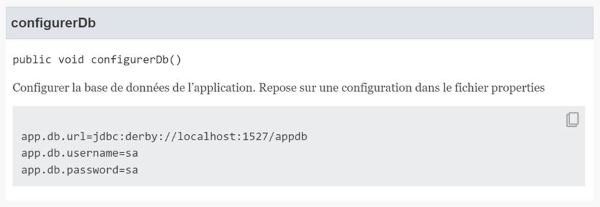
/**
* Configurer la base de données de l'application.
* Repose sur une configuration dans le fichier properties
* {@snippet lang="properties" :
* app.db.url=jdbc:derby://localhost:1527/appdb
* app.db.username=sa
* app.db.password=sa
* }
*/
|
La sortie générée est :
Trois autres attributs peuvent aussi être utilisés avec le tag @snippet :
Les fragments en ligne sont inclus dans le tag @snippet lui-même.
Le contenu du fragment, qui est inclus dans la documentation générée, est le texte compris entre le saut de ligne après les deux points « : » et l'accolade fermante « } ».
Dans sa forme la plus simple, le tag {@snippet ...} peut être utilisé pour contenir un fragment de texte, comme du code source ou toute autre forme de texte structuré.
| Exemple ( code Java 18 ) : |
/**
* Méthode de test
* {@snippet id="main" :
* public static void main(String[] args) {
* System.out.println("Hello World");
* }
* }
*/
|
Il n'est pas nécessaire d'échapper les caractères tels que <, > et & avec des entités HTML. Il n'est pas nécessaire non plus d'échapper les tags de commentaires de la documentation.
Les caractères d'espacement en tête sont supprimés du contenu à l'aide de la méthode stripIndent() de la classe String. Cela permet de remédier à un inconvénient des blocs <pre>{@code ...}</pre> qui imposait que le texte à afficher commence toujours immédiatement après les espaces et les astérisques.
Dans les tags @snippet, l'indentation dans la sortie générée est l'indentation relative à la position de l'accolade fermante dans le fichier source. Ceci est similaire à l'indentation d'un bloc de texte par rapport à la position du délimiteur de fin """.
Cela permet de contrôler l'indentation dans la sortie générée en ajustant la position de la dernière parenthèse fermante.
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* public static void main(String[] args) {
* System.out.println("Hello World");
* }
* }
*/ |

| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* public static void main(String[] args) {
* System.out.println("Hello World");
* }
* }
*/ |

Le contenu du fragment possède plusieurs restrictions liées au fait que le tag est inclus dans un commentaire de documentation :
Les régions sont des portions de code dont le nom est facultatif et qui identifient le texte à utiliser par un fragment. Elles définissent également la portée des actions telles que la mise en évidence ou la modification du texte.
Le début de la définition d'une région peut se faire de plusieurs manières :
La fin de la définition d'une région peut se faire de plusieurs manières :
Si un nom de région est précisé, le tag @end termine la région commencée avec ce nom. Si aucun nom n'est donné, le tag termine la région la plus proche commencée qui n'a pas déjà un tag @end correspondante.
Il n'y a aucune contrainte sur les régions créées par différentes paires de tag @start et @end correspondantes. Même si cela n'est pas recommandé, les régions peuvent même se chevaucher.
Par défaut, les commentaires de marquage ne s'appliquent que sur le contenu précédent de la même ligne. Il est parfois pratique de l'appliquer sur plusieurs lignes : dans ce cas, il faut utiliser une région.
Une région peut être anonyme ou nommée.
Pour qu'un tag s'applique à une région anonyme, il faut le placer au début de la région et utiliser un tag @end pour marquer la fin de la région.
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* // @start region="exemple" :
* System.out.println("Hello World");
* // @end
* }
*/ |
Il est possible d'indiquer explicitement la correspondance entre le début et la fin d'une région en attribuant un nom avec l'attribut region et en utilisant ce nom comme valeur de l'attribut region du tag @end.
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* // @start region="exemple" :
* System.out.println("Hello World");
* // @end region="exemple"
* }
*/ |
Si le nom de la région indiqué dans le tag @end n'est pas défini comme un nom de région valide alors une erreur est émise à la génération de la documentation.
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* // @start region="exempledeb" :
* System.out.println("Hello World");
* // @end region="exemplefin"
* }
*/ |
| Résultat : |
D:\java18\src\main\java\fr\jmdoudoux\dej\java18\App.java:145:
error: snippet markup: unpaired region
* // @end region="exemplefin"
^
|
Nommer une région n'a aucune incidence sur le contenu généré : sa seule utilité est la définition de la région et son identification.
Les régions peuvent être imbriquées. Les régions imbriquées ne doivent pas nécessairement être nommées, mais l'utilisation de régions nommées apporte plus de clarté.
Les régions peuvent se chevaucher : il faut alors utiliser des régions nommées pour faciliter la définition des régions.
Les fragments externes sont stockés dans un fichier externe. Contrairement aux fragments en ligne, les fragments externes n'ont pas de restrictions : ils peuvent contenir des commentaires multilignes par exemple.
Le fichier externe contenant le fragment peut être précisé de deux manières :
L'attribut file du tag {@snippet ...} permet de préciser le chemin relatif du fichier contenant le code source qui sera ajouté dans la documentation.
| Exemple ( code Java 18 ) : |
/**
* Exemple d'utilisation.
* {@snippet file="com/jmdoudoux/dej/ExempleDoc.java"
* }
*/ |
Exemple avec le fichier Utils.java qui contient :
| Exemple ( code Java 18 ) : |
package fr.jmdoudoux.dej.java18;
/**
* Utilitaires divers.
*/
public class Utils {
/**
* Afficher un message à la console
* @param message le message à afficher
*/
public static void afficher(String message) {
System.out.println(message);
}
} |
L'attribut class du tag {@snippet ...} permet de préciser le nom de la classe contenant le code source qui sera ajouté dans la documentation.
Dans un fragment externe, les deux points, le saut de ligne et le contenu suivant peuvent être omis.
| Exemple ( code Java 18 ) : |
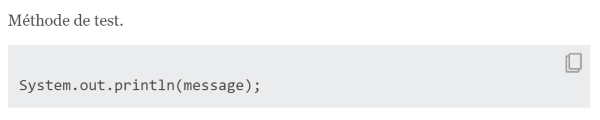
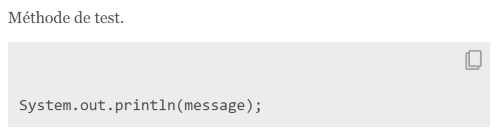
/**
* Méthode de test.
* {@snippet class="fr.jmdoudoux.dej.java18.Utils" region="exemple"}
*/ |
Par défaut, tout le contenu du code source de la classe est ajouté dans la documentation générée.

Les fichiers externes peuvent être placés :
Lors de l'utilisation des attributs class et file, le fichier peut être placé dans une hiérarchie de répertoires ayant pour racine le sous-répertoire snippet-files du répertoire contenant le code source avec le tag {@snippet ...}. L'utilisation des sous-répertoires snippet-files est similaire à l'utilisation actuelle des sous-répertoires doc-files pour les fichiers de documentation auxiliaires. Les fichiers contenus dans un répertoire snippet-files peuvent être partagés entre les fragments d'un même paquet, et sont isolés des fragments des répertoires snippet-files d'autres packages.
Attention : certains outils peuvent considérer de manière erronée que le sous-répertoire snippet-files est inclus dans la hiérarchie des répertoires des packages. snippet-files n'est pas un identifiant Java valide et ne peut donc pas être utilisé dans le nom du package. Dans ce cas, il ne faut pas utiliser de sous-répertoires snippet-files.
Le fichier peut également être placé sur un chemin de recherche précisé par l'option --snippet-path de l'outil javadoc. Les fichiers du chemin de recherche auxiliaire existent dans un espace de nom partagé unique et peuvent être référencés depuis n'importe quel endroit de la documentation.
L'utilisation d'un fragment externe est parfois requise pour plusieurs besoins :
Il peut être pratique de valider le contenu d'un fragment en le compilant et éventuellement en le testant. Cela peut permettre d'éviter des erreurs liées à une faute de frappe ou à une évolution dans le code. Un des intérêts des fragments externes est qu'ils peuvent être compilés et testés par des outils externes.
Il est possible de n'ajouter qu'une portion du code source de la classe en définissant une région et en lui attribuant un nom. Les tags @start et @end dans des commentaires de marquage dans le fichier définissent les limites de la région.
Le fichier Utils.java contient :
| Exemple ( code Java 18 ) : |
package fr.jmdoudoux.dej.java18;
/**
* Utilitaires divers.
*/
public class Utils {
/**
* Afficher un message à la console
* @param message le message à afficher
*/
public static void afficher(String message) {
// @start region="exemple" :
System.out.println(message);
// @end
}
} |
L'attribut region du tag {@snippet ...} précise le nom de la région du fichier externe à inclure.
| Exemple ( code Java 18 ) : |
/**
* Méthode de test.
* {@snippet class="fr.jmdoudoux.dej.java18.Utils" region="exemple"}
*/ |
La documentation générée contient :
Un fichier externe peut contenir plusieurs régions avec des noms différents qui pourront être utilisées par différents tags @snippet.
Il est aussi possible de mélanger les régions au sein d'un fichier source externe, des régions utilisables pour définir les parties du fichier référençables dans un tag @snippet, et des régions utilisables avec des tags de marquage pour mettre en évidence ou modifier le texte à inclure dans la documentation générée.
Les fragments externes ne sont pas restreints à n'être que du code source Java.
L'attribut file du tag @snippet permet de préciser le chemin d'un fichier texte relatif au sous-répertoire snippet-files ou au sous-répertoire précisé avec l'option --snippet-path de la commande javadoc.
| Exemple ( code Java 18 ) : |
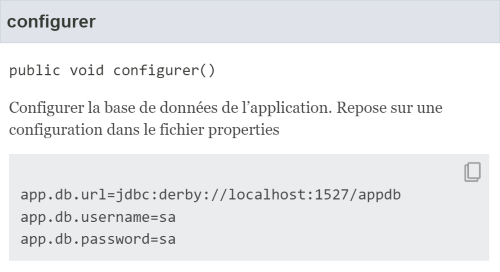
/**
* Configurer la base de données de l'application.
* Repose sur une configuration via le fichier properties
* {@snippet file=app-config.properties region=db }
*/
public void configurer() {
} |
Avec le fichier app-config.properties qui contient :
| Résultat : |
app.titre=Mon application
# @start region=db
app.db.url=jdbc:derby://localhost:1527/db
app.db.username=root
app.db.password=root
# @end region=db
app.cache=true |
La documentation générée contient :
Dans un fichier de propriétés, les commentaires de marquage utilisent la syntaxe de commentaires pour ces fichiers : les lignes commençant par un caractère dièse « # ».
Comme l'étendue par défaut des commentaires de marquage est la ligne courante, et que les fichiers de propriétés ne permettent pas de placer des commentaires sur la même ligne que le contenu sans commentaire, il faut utiliser la forme de commentaire de marquage qui se termine par « : » afin que le commentaire de marquage soit traité comme s'appliquant à la ligne suivante.
| Résultat : |
app.titre=Mon application
# @start region=db
app.db.url=jdbc:derby://localhost:1527/db
app.db.username=root
# @replace substring="root" replacement="xxxx" :
app.db.password=root
# @end region=db
app.cache=true |

Les fragments en ligne sont pratiques à utiliser, surtout pour de courts exemples, car ils permettent de voir le contenu du fragment dans le contexte du commentaire qui le contient.
Les fragments externes sont pratiques à utiliser car ils peuvent être compilés et même testés.
Un fragment hybride est à la fois un fragment interne et un fragment externe. Il contient le contenu du fragment dans le tag lui-même, pour la commodité de lecture du code source de la classe documentée, et il fait également référence à un fichier séparé qui contient le contenu du fragment.
Une erreur se produit lors du traitement d'un extrait hybride si le contenu en ligne ne correspond au contenu du fragment externe.
Les fragments hybrides offrent le meilleur des deux styles mais avec quelques contraintes.
Un fragment hybride est une combinaison d'un fragment en ligne et d'un fragment externe : il a un contenu en ligne et les attributs pour spécifier un fichier externe et éventuellement une région dans ce fichier.
| Exemple ( code Java 18 ) : |
/**
* Afficher un message à la console
* @param message le message à afficher
*/
public static void afficher(String message) {
// @start region="exemple" :
System.out.println(message);
// @end
} |
Avec le fichier Utils.java qui contient :
| Exemple ( code Java 18 ) : |
package fr.jmdoudoux.dej.java18;
/**
* Utilitaires divers.
*/
public class Utils {
/**
* Afficher un message à la console
* @param message le message à afficher
*/
public static void afficher(String message) {
// @start region="exemple" :
System.out.println(message);
// @end
}
}
|
Pour éviter une désynchronisation entre les deux contenus, le Doclet standard vérifie que le résultat du traitement du tag @snippet en tant que fragment en ligne est le même que celui du traitement en tant que fragment externe. Si ce n'est pas le cas alors une erreur est émise à la génération de la documentation.
| Exemple ( code Java 18 ) : |
/**
* Méthode de test.
* {@snippet file="fr/jmdoudoux/dej/java18/Utils.java" region="exemple" :
*
*System.out.println(message);
*
*}
*/ |
| Résultat : |
D:\java18\src\main\java\fr\jmdoudoux\dej\java18\App.java:27:
error: contents mismatch:
* {@snippet file="fr/jmdoudoux/dej/java18/Utils.java" region="exemple" :
^
----------------- inline -------------------
System.out.println(message);
----------------- external -----------------
System.out.println(message); |
Les tags de marquage (markup tags) permettent de réaliser différentes actions selon le tag utilisé :
Ces tags peuvent être utilisés dans des fragments internes, externes et hybrides.
Ils s'appliquent sur une ligne ou sur une région dans le contenu d'un fragment.
Ils peuvent avoir des attributs en fonction des besoins.
Ils doivent être placé dans un commentaire pour ne pas interférer avec le code source : par exemple, après une séquence // pour du code Java ou # pour un fichier properties. Ces commentaires sont nommés commentaires de marquage (markup comments).
Plusieurs tags peuvent être inclus dans un même commentaire de marquage.
Les commentaires de fin de ligne sont pratiques à utiliser comme commentaires de marquage mais ils peuvent présenter certaines limitations :
Pour contourner ces limitations, il y a une syntaxe spéciale pour les commentaires de marquage : si le commentaire de marquage se termine par un caractère deux points « : », il est traité comme s'il s'agissait d'un commentaire de fin de ligne sur la ligne suivante.
Ainsi, les tags de marquage s'appliquent à la ligne de source contenant le commentaire, sauf si le commentaire se termine par deux points « : », auquel cas les tags de marquage s'appliquent uniquement à la ligne suivante. Cette syntaxe peut être utile si le commentaire de marquage est particulièrement long, ou si le format syntaxique du contenu d'un extrait ne permet pas aux commentaires d'apparaître sur la même ligne que la source sans commentaire.
Les commentaires de marquage n'apparaissent pas dans la sortie générée.
Comme certains langages utilisent des méta-commentaires similaires aux commentaires de marquage, les commentaires qui commencent par @ suivi d'un nom non reconnu sont ignorés. Si le nom est reconnu, mais que des erreurs sont présentes dans le commentaire de marquage, une erreur est signalée. Dans ce cas, la sortie générée est indéfinie par rapport à la sortie générée à partir du snippet.
Un fragment peut contenir des commentaires de marquage, qui peuvent être utilisés pour modifier ce qui est affiché dans la sortie générée. Les commentaires de marquage sont des commentaires de fin de ligne dans le langage déclaré pour le fragment.
Les tags de marquage sont généralement de la forme @nom [arguments] ... La plupart des arguments sont des paires nom=valeur, auquel cas les valeurs ont la même syntaxe que celle des attributs du tag @snippet.
Le tag de marquage @highlight permet de mettre en évidence une portion de texte sur une ou plusieurs lignes.
Plusieurs attributs permettent de préciser l'étendue du texte à prendre en compte, le texte à mettre en évidence dans cette étendue et le type de mise en évidence :
|
Attribut |
Rôle |
|
region |
Préciser que la portée est la région indiquée jusqu'au tag @end correspondant |
|
substring=chaine |
Préciser la portion de chaîne de caractères littérale à mettre en évidence dans la portée. Le texte peut être entouré par une paire de simple ou double quotes |
|
regex=chaine |
Préciser une expression régulière pour désigner les portions de texte qui la respectent dans la portée |
|
type=nom |
Préciser le type de mise en évidence à utiliser. Trois valeurs sont utilisables, chacune correspondant à une classe CSS qui peuvent être redéfinie :
|
Si l'attribut region n'est pas précisé alors l'étendue est juste la ligne courante ou la ligne suivante si le commentaire se termine un caractère « : ».
| Exemple ( code Java 18 ) : |
/**
* Afficher.
* {@snippet :
* // @highlight substring='"Hello World"' :
* System.out.println("Hello World");
*}
*/ |
La documentation générée contient :

Si ni l'attribut substring ni l'attribut regex ne sont précisés alors l'intégralité de la ligne ou de la région est mise en évidence.
| Exemple ( code Java 18 ) : |
/**
* Afficher.
* {@snippet :
* // @highlight :
* System.out.println("Hello");
* System.out.println("World");
*}
*/ |
La documentation générée contient :

L'attribut type permet de préciser le type de mise en évidence à utiliser.
| Exemple ( code Java 18 ) : |
/**
* Afficher.
* {@snippet :
* // @highlight substring='"Hello World"' type="bold" :
* System.out.println("Hello World");
* // @highlight substring='"Hello World"' type="italic" :
* System.out.println("Hello World");
* // @highlight substring='"Hello World"' type="highlighted" :
* System.out.println("Hello World");
*}
*/
|
La documentation générée contient :

Pour appliquer la mise en évidence sur plusieurs lignes, il faut utiliser l'attribut region pour délimiter la première ligne concernée et utiliser le tag de marquage @end dans un commentaire de marquage pour indiquer la dernière ligne.
| Exemple ( code Java 18 ) : |
/**
* Afficher.
* {@snippet :
* // @highlight substring="out" region
* System.out.println("Hello World");
* System.out.println("Hello World");
* System.out.println("Hello World");
* // @end
*}
*/ |
La documentation générée contient :

Les portions à mettre évidence peuvent aussi être définies en utilisant une expression régulière grâce à l'attribut regex.
| Exemple ( code Java 18 ) : |
/**
* Afficher.
* {@snippet :
* // @highlight region regex = "\bout\b"
* System.out.println("Hello World");
* System.out.println("Hello World");
* System.out.println("Hello World");
* // @end
*}
*/ |
La documentation générée contient :

Si les attributs substring et regex sont utilisés simultanément alors une erreur est émise.
| Exemple ( code Java 18 ) : |
/**
* Afficher.
* {@snippet :
* // @highlight substring="out" region regex = "\bout\b"
* System.out.println("Hello World");
* System.out.println("Hello World");
* System.out.println("Hello World");
* // @end
*}
*/ |
| Résultat : |
D:\java18\src\main\java\fr\jmdoudoux\dej\java18\App.java:62:
error: snippet markup: attributes "substring" and "regex" used simultaneously
* // @highlight substring="out" region regex = "\out\b"
^
|
Il peut être pratique d'écrire le contenu un fragment contenant du code validable par des outils externes, mais de l'afficher sous une forme différente qui ne compile pas. Par exemple, on peut vouloir afficher du code avec une ellipse ou un autre marqueur pour indiquer que du code supplémentaire ou différent doit être utilisé à cet endroit. Cela peut se faire en remplaçant des portions du contenu du fragment par du texte de remplacement.
| Exemple ( code Java 18 ) : |
/**
* Définir une variable de type String.
* {@snippet :
* // @replace substring='""' replacement=" ... " :
* String texte = "";
*}
*/
public void definir() {
}
|
La documentation générée contient :

Le tag de marquage @replace permet de modifier le texte du fragment dans la sortie générée.
Plusieurs attributs permettent de préciser l'étendue du texte à prendre en compte, le texte à remplacer dans cette étendue et le texte de remplacement :
|
Attribut |
Rôle |
|
region |
Préciser que la portée est la région indiquée jusqu'au tag @end correspondant |
|
substring=texte |
Préciser la portion de chaîne de caractères littérale à modifier dans la portée. Le texte peut être entouré par une paire de simple ou double quotes |
|
regex=texte |
Préciser une expression régulière pour désigner les portions de texte qui la respectent dans la portée |
|
replacement=texte |
Préciser le texte de remplacement. |
Si l'attribut region n'est pas précisé alors l'étendue est juste la ligne courante ou la ligne suivante si le commentaire se termine un caractère « : ».
Si ni l'attribut substring ni l'attribut regex ne sont précisés alors l'intégralité du fragment est remplacé.
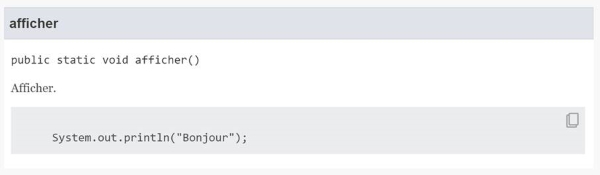
| Exemple ( code Java 18 ) : |
/**
* Afficher.
* {@snippet :
* // @replace substring='"Hello World"' replacement='"Bonjour"' :
* System.out.println("Hello World");
*}
*/
public static void afficher() {
} |
La documentation générée contient :
Pour supprimer du texte, il suffit de mettre une chaîne de caractères vide comme valeur de l'attribut de replacement.
Le tag @link permet de lier du texte à des déclarations situées ailleurs dans la documentation.
Plusieurs attributs permettent de préciser l'étendue de la portée du texte à prendre en compte, le texte à lier dans cette portée et la cible du lien :
|
Attribut |
Rôle |
|
region |
Préciser que la portée est la région indiquée jusqu'au tag @end correspondant |
|
substring=texte |
Préciser la portion de chaîne de caractères littérale à lier dans la portée. Le texte peut être entouré par une paire de simple ou double quotes |
|
regex=texte |
Préciser une expression régulière pour désigner les portions de texte qui la respectent dans la portée |
|
target=lien |
Permettre de préciser la cible du lien. La valeur correspond à celle utilisée dans le tag @link |
|
type=nom |
Préciser le type de lien : les valeurs possibles sont link (par défaut) ou linkplain |
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* public static void main(String[] args) {
* // @link substring="System.out" target="System#out" :
* System.out.println("Hello World");
* }
*}
*/ |
La documentation générée contient :

L'attribut regex permet de préciser une expression régulière qui sera appliquée pour déterminer la portion de texte concernée.
| Exemple ( code Java 18 ) : |
/**
* Initialiser
* {@snippet :
* String message = "Bonjour"; // @replace regex='".*"' replacement="..."
* }
*/ |
La documentation générée contient :

Leur utilisation est parfois très pratique pour faciliter l'identification des portions à modifier.
| Exemple ( code Java 18 ) : |
/**
* Initialiser
* {@snippet lang="properties" :
* # @highlight region regex="[0-9]+":
* server.port=80
* test.server.port=8080
* # @end
* }
*/ |

L'utilisation d'expressions régulières peut cependant s'avérer délicate pour identifier une portion spécifique d'une chaîne de caractères dans une ligne ou une région.
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* int a = 1;
* int a2 = a; // @highlight regex='a'
* }
*/ |
La documentation générée contient :

Dans l'exemple précédent toutes les instances de « a » sont mises en évidence. Pour mettre en évidence uniquement la seconde instance, il faut une expression régulière qui utilise un boundary matcher.
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* int a = 1;
* int a2 = a; // @highlight regex='a\b'
* }
*/ |
La documentation générée contient :

L'expression régulière de l'exemple ci-dessus utilise un word boundary pour identifier une chaîne qui est une sous-chaîne d'une autre chaîne située précédemment sur la ligne.
Il est aussi possible d'utiliser une expression régulière avec un lookahead ou un lookbehind pour identifier certaines séquences.
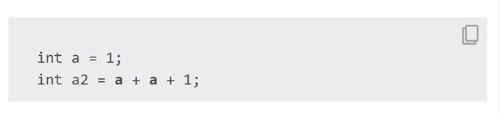
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* int a = 1;
* int a2 = a + a + 1; // @highlight regex='a(?= \+)'
* }
*/ |
La documentation générée contient :
Si la valeur de l'expression régulière n'est pas valide alors une erreur est émise lors de la génération de la documentation.
| Exemple ( code Java 18 ) : |
/**
* {@snippet :
* int a = 1;
* int a2 = a + a + 1; // @highlight regex='a((?= \+)'
* }
*/ |
| Résultat : |
D:\java18\src\main\java\fr\jmdoudoux\dej\java18\App.java:154:
error: snippet markup: invalid regex
* int a2 = a + a + 1; // @highlight regex='a((?= \+)'
^
|
Il est recommandé de vérifier la documentation générée lors de l'utilisation d'une expression régulière afin de s'assurer que le rendu est bien celui attendu.
| Exemple : |
/**
* Résumé du rôle de la méthode.
* Commentaires détaillés sur le role de la methode
* @param val la valeur a traiter
* @return la valeur calculée
* @since 1.0
* @deprecated Utiliser la nouvelle methode xyz
*/
public int maMethode(int val) {
return 0;
} |
Résultat :

Javadoc permet de fournir un moyen de documenter les packages car ceux-ci ne disposent pas de code source particulier : il faut définir des fichiers dont le nom est particulier.
Ces fichiers doivent être placés dans le répertoire désigné par le package.
Le fichier package.html contient une description du package au format HTML. En plus, il est possible d'utiliser les tags @deprecated, @link, @see et @since.
Le fichier overview.html permet de fournir un résumé de plusieurs packages au format html. Ce fichier doit être placé dans le répertoire qui inclut les packages décrits.
Pour générer la documentation, il faut invoquer l'outil javadoc. Javadoc recrée à chaque utilisation la totalité de la documentation.
Pour formater la documentation, javadoc utilise une doclet. Une doclet permet de préciser le format de la documentation générée. Par défaut, Javadoc propose une doclet qui génère une documentation au format HTML. Il est possible de définir sa propre doclet pour changer le contenu ou le format de la documentation (pour par exemple, générer du RTF ou du XML).
La génération de la documentation avec le doclet par défaut crée de nombreux fichiers et des répertoires pour structurer la documentation au format HTML, avec et sans frame.
La documentation de l'API Java fournie par Sun/Oracle est réalisée grâce à Javadoc. La page principale est composée de trois frames :

Par défaut, la documentation générée contient les éléments suivants :
Tous ces fichiers peuvent être regroupés en trois catégories :
Il y a plusieurs fichiers générés à la racine de l'application :
Le fichier allclasses-frame.html affiche toutes les classes, interfaces et exceptions de la documentation avec un lien pour afficher le détail. Cette page est affichée en bas à gauche dans le fichier index.html

Le fichier constant-values.html affiche la liste de toutes les constantes avec leurs valeurs.


Le fichier deprecated-list.html affiche la liste de tous les membres déclarés deprecated. Le lien Deprecated de la barre de navigation permet d'afficher le contenu de cette page.

Le fichier help-doc.html affiche l'aide en ligne de la documentation. Le lien Help de la barre de navigation permet d'afficher le contenu de cette page.

Le fichier index.html est la page principale de la documentation composée de 3 frames.
Le fichier overview-frame.html affiche la liste des packages avec un lien pour afficher la liste des membres du package. Cette page est affichée en haut à gauche dans le fichier index.html.

Le fichier overview-summary.html affiche un résumé des packages de la documentation. Cette page est affichée par défaut dans la partie centrale de la page index.html.
Le fichier overview-tree.html affiche la hiérarchie des classes et interfaces. Le lien Tree de la barre de navigation permet d'afficher le contenu de cette page.


Le fichier package-list est un fichier texte contenant la liste de tous les packages (non affiché dans la documentation).
Le fichier packages.html permet de choisir entre les versions avec et sans frame de la documentation.
Le fichier serialized-form.html affiche la liste des classes qui sont sérialisables.

Le fichier stylesheet.css est la feuille de style utilisée pour afficher la documentation.
Le fichier allclasses-noframe.html affiche la page allclasses-frame.html sans frame.
Il y a un répertoire par package. Ce répertoire contient plusieurs fichiers :
Cette structure est reprise pour les sous-packages.
La page détaillant une classe possède la structure suivante :



Si l'option -linksource est utilisée, les fichiers sources sont stockés dans l'arborescence du sous-répertoire src-html de la documentation.
|
|