 |
 |
 |
| Niveau : | |
Les collections sont des objets qui permettent de gérer des ensembles d'objets. Ces ensembles de données peuvent être définis avec plusieurs caractéristiques : la possibilité de gérer des doublons, de gérer un ordre de tri, etc. ...
Une collection est un regroupement d'objets qui sont désignés sous le nom d'éléments.
L'API Collections propose un ensemble d'interfaces et de classes dont le but est de stocker de multiples objets. Elle propose quatre grandes familles de collections, chacune définie par une interface de base :
Ce chapitre contient plusieurs sections :
Les tableaux ne peuvent pas répondre à tous les besoins de stockage d'un ensemble d'objets et surtout ils manquent de fonctionnalités. La large diversité d'implémentations proposées par l'API Collections de Java permet de répondre à la plupart des besoins.
Avant Java 1.2 qui a introduit l'API Collections, seules quelques classes du package java.util permettaient de stocker et de gérer des éléments : Array, Vector, Stack, Hashtable, Properties et BitSet. L'interface Enumeration permet de parcourir le contenu de ces objets.
L'API Collections propose de structurer et de définir un ensemble d'interfaces et de classes de type collection. Les collections sont des conteneurs qui permettent de regrouper des objets en une seule entité.
Java propose l'API Collections qui offre un socle riche et des implémentations d'objets de type collection enrichies au fur et à mesure des versions de Java.
L'API Collections possède deux grandes familles chacune définies par une interface :
Une collection permet de stocker un groupe d'éléments en respectant certaines fonctionnalités selon l'implémentation : de base, elle permet d'ajouter, de supprimer, d'obtenir et de parcours ses éléments.
Les interfaces et les classes de l'API Collections qui ne proposent pas de gestion des accès concurrents sont dans le package java.util. Java 5 propose plusieurs collections dans le package java.util.concurrent telles que CopyOnWriteArrayList, ConcurrentHashMap ou CopyOnWriteArraySet qui permettent des modifications lors de leur parcours.
Les fonctionnalités des collections sont définies dans cinq interfaces de base : Collection, List, Set, Map, Queue.
Plusieurs interfaces spécialisent certaines fonctionnalités particulières :
Elle définit plusieurs classes abstraites qui sont les classes mères de plusieurs implémentations : AbstractCollection, AbstractSet, AbstractList, AbstractSequentialList, AbstractQueue, AbstractMap.
Elle propose plusieurs implémentations à usage généraliste : HashSet, TreeSet, LinkedHashSet, ArrayList, ArrayDeque, LinkedList, PriorityQueue, HashMap, TreeMap, LinkedHashMap.
Elle propose également plusieurs implémentations pour un usage spécifique : WeakHashMap, IdentityHashMap, CopyOnWriteArrayList, CopyOnWriteArraySet, EnumSet, EnumMap.
A partir de Java 5, plusieurs implémentations permettent l'utilisation de collections de manière concurrente dans un environnement multithread : ConcurrentLinkedQueue, LinkedBlockingQueue, ArrayBlockingQueue, PriorityBlockingQueue, DelayQueue, SynchronousQueue, LinkedBlockingDeque, ConcurrentHashMap, ConcurrentSkipListSet, ConcurrentSkipListMap.
|
Utilisation générale |
Utilisation spécifique |
Gestion des accès concurrents |
List |
ArrayList LinkedList |
CopyOnWriteArrayList |
Vector Stack CopyOnWriteArrayList |
Set |
HashSet TreeSet LinkedHashSet |
CopyOnWriteArraySet EnumSet |
CopyOnWriteArraySet ConcurrentSkipListSet |
Map |
HashMap TreeMap LinkedHashMap |
WeakHashMap IdentityHashMap EnumMap |
Hashtable ConcurrentHashMap ConcurrentSkipListMap |
Queue |
LinkedList ArrayDeque PriorityQueue |
|
ConcurrentLinkedQueue LinkedBlockingQueue ArrayBlockingQueue PriorityBlockingQueue DelayQueue SynchronousQueue LinkedBlockingDeque |
Elle définit enfin :
Le framework Collections propose plusieurs implémentations possédant chacune un comportement et des fonctionnalités particulières.
Collection |
Ordonné |
Accès direct |
Clé / valeur |
Doublons |
Null |
Thread Safe |
ArrayList |
Oui |
Oui |
Non |
Oui |
Oui |
Non |
LinkedList |
Oui |
Non |
Non |
Oui |
Oui |
Non |
HashSet |
Non |
Non |
Non |
Non |
Oui |
Non |
TreeSet |
Oui |
Non |
Non |
Non |
Non |
Non |
HashMap |
Non |
Oui |
Oui |
Non |
Oui |
Non |
TreeMap |
Oui |
Oui |
Oui |
Non |
Non |
Non |
Vector |
Oui |
Oui |
Non |
Oui |
Oui |
Oui |
Hashtable |
Non |
Oui |
Oui |
Non |
Non |
Oui |
Properties |
Non |
Oui |
Oui |
Non |
Non |
Oui |
Stack |
Oui |
Non |
Non |
Oui |
Oui |
Oui |
CopyOnWriteArrayList |
Oui |
Oui |
Non |
Oui |
Oui |
Oui |
ConcurrentHashMap |
Non |
Oui |
Oui |
Non |
Non |
Oui |
CopyOnWriteArraySet |
Non |
Non |
Non |
Non |
Oui |
Oui |
Pour combler le manque d'objets adaptés, la version 2 du J.D.K. apporte un framework complet pour gérer les collections. Cette bibliothèque contient un ensemble de classes et interfaces. Elle fournit également un certain nombre de classes abstraites qui implémentent partiellement certaines interfaces.
Les interfaces à utiliser par des objets qui gèrent des collections sont :
Certaines méthodes définies dans ces interfaces sont dites optionnelles : leur définition est donc obligatoire mais si l'opération n'est pas supportée alors la méthode doit lever une exception particulière. Ceci permet de réduire le nombre d'interfaces et de répondre au maximum de cas.
Le framework propose plusieurs objets qui implémentent ces interfaces et qui peuvent être directement utilisés :
Le framework définit aussi des interfaces pour faciliter le parcours des collections et leur tri :
Deux classes existantes dans les précédentes versions du JDK ont été modifiées pour implémenter certaines interfaces du framework :
Le framework propose la classe Collections qui contient de nombreuses méthodes statiques pour réaliser certaines opérations sur une collection. Plusieurs méthodes unmodifiableXXX() (où XXX représente une interface d'une collection) permettent de rendre une collection non modifiable. Plusieurs méthodes synchronizedXXX() permettent d'obtenir une version synchronisée d'une collection pouvant ainsi être manipulée de façon sûre par plusieurs threads. Enfin plusieurs méthodes permettent de réaliser des traitements sur la collection : tri et duplication d'une liste, recherche du plus petit et du plus grand élément, etc. ...
Le framework fournit plusieurs classes abstraites qui proposent une implémentation partielle d'une interface pour faciliter la création d'une collection personnalisée : AbstractCollection, AbstractList, AbstractMap, AbstractSequentialList et AbstractSet.
Les objets du framework stockent toujours des références sur les objets contenus dans la collection et non les objets eux-mêmes. Ce sont obligatoirement des objets qui doivent être ajoutés dans une collection. Il n'est pas possible de stocker directement des types primitifs : il faut impérativement encapsuler ces données dans des wrappers.
Toutes les classes de gestion de collections du framework ne sont pas synchronisées : elles ne prennent pas en charge les traitements multithreads. Le framework propose des méthodes pour obtenir des objets de gestion de collections qui prennent en charge cette fonctionnalité. Les classes Vector et Hashtable étaient synchronisées mais l'utilisation d'une collection ne se fait généralement pas dans ce contexte. Pour réduire les temps de traitement dans la plupart des cas, elles ne sont pas synchronisées par défaut.
Lors de l'utilisation de ces classes, il est préférable de stocker la référence de ces objets sous la forme d'une interface qu'ils implémentent plutôt que sous leur forme objet. Ceci rend le code plus facile à modifier si le type de l'objet qui gère la collection doit être changé.
Le framework de Java 2 définit 6 interfaces en relation directe avec les collections qui sont regroupées dans deux arborescences :
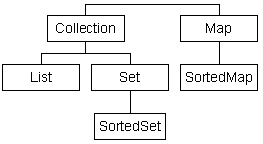
Le JDK ne fournit pas de classe qui implémente directement l'interface Collection.
Le tableau ci-dessous présente les différentes classes qui implémentent les interfaces de bases Set, List et Map :
|
Set
collection d'éléments uniques |
List
collection avec doublons |
Map
collection sous la forme clé/valeur |
|
| Tableau redimensionnable |
ArrayList, Vector (JDK 1.1)
|
||
| Arbre | TreeSet
|
TreeMap
|
|
| Liste chaînée | LinkedList
|
||
| Collection utilisant une table de hachage | HashSet
|
HashMap, Hashtable (JDK 1.1)
|
|
| Classes du JDK 1.1 | Stack
|
Pour gérer toutes les situations de façon simple, certaines méthodes peuvent être définies dans une interface comme «optionnelles ». Pour celles-ci, les classes qui implémentent une telle interface, ne sont pas obligées d'implémenter du code qui réalise un traitement mais simplement lève une exception si cette fonctionnalité n'est pas supportée. Le nombre d'interfaces est ainsi grandement réduit.
Cette exception est du type UnsupportedOperationException. Pour éviter de protéger tous les appels de méthodes d'un objet gérant les collections dans un bloc try-catch, cette exception hérite de la classe RuntimeException.
Toutes les classes fournies par le J.D.K. qui implémentent une des interfaces héritant de Collection implémentent toutes les opérations optionnelles.
L'interface Collection, ajoutée à Java 1.2, définit des méthodes pour des objets qui gèrent des éléments d'une façon assez générale. Elle est la super interface de plusieurs interfaces du framework.
Plusieurs classes qui gèrent une collection implémentent une interface qui hérite de l'interface Collection. Cette interface est une des deux racines de l'arborescence des collections.
Cette interface représente un minimum commun pour les objets qui gèrent des collections : ajout d'éléments, suppression d'éléments, vérification de la présence d'un objet dans la collection, parcours de la collection et quelques opérations diverses sur la totalité de la collection.
Ce tronc commun permet entre autres de définir pour chaque objet gérant une collection, un constructeur pour cet objet demandant un objet de type Collection en paramètre. La collection est ainsi initialisée avec les éléments contenus dans la collection fournie en paramètre.
Il existe de nombreuses implémentations qui proposent différentes fonctionnalités : support des doublons ou non, tri des éléments ou non, support des null.
L'API Collections ne propose pas d'implémentation directe de cette interface : elle propose des implémentations pour des interfaces filles qui définissent les fonctionnalités des grandes familles de collections : List, Set, Map, Queue.
Elle hérite de l'interface Iterable depuis Java 5.
Chaque implémentation de l'interface Collection devrait fournir au moins deux constructeurs :
L'interface Collection définit plusieurs méthodes :
Méthode |
Rôle |
boolean add(E e) |
Ajouter un élément à la collection (optionnelle) |
boolean addAll(Collection<? extends E> c) |
Ajouter tous les éléments de la collection fournie en paramètre dans la collection (optionnelle) |
void clear() |
Supprimer tous les éléments de la collection (optionnelle) |
boolean contains(Object o) |
Retourner un booléen qui précise si l'élément est présent dans la collection |
boolean containsAll(Collection<?> c) |
Retourner un booléen qui précise si tous les éléments fournis en paramètres sont présents dans la collection |
boolean equals(Object o) |
Vérifier l'égalité avec la collection fournie en paramètre |
int hashCode() |
Retourner la valeur de hachage de la collection |
boolean isEmpty() |
Retourner un booléen qui précise si la collection est vide |
Iterator<E> iterator() |
Retourner un Iterator qui permet le parcours des éléments de la collection |
boolean remove(Object o) |
Supprimer un élément de la collection s'il est présent (optionnelle) |
boolean removeAll(Collection<?> c) |
Supprimer tous les éléments fournis en paramètres de la collection s'ils sont présents (optionnelle) |
boolean retainAll(Collection<?> c) |
Ne laisser dans la collection que les éléments fournis en paramètres : les autres éléments sont supprimés (optionnelle). Elle renvoie un booléen qui précise si le contenu de la collection a été modifié |
int size() |
Retourner le nombre d'éléments contenus dans la collection |
Object[] toArray() |
Retourner un tableau contenant tous les éléments de la collection |
<T> T[] toArray(T[] a) |
Retourner un tableau typé de tous les éléments de la collection |
Attention : il ne faut pas ajouter dans une collection une référence à la collection elle-même.
Certaines méthodes de cette interface peuvent lever une exception de type UnsupportedOperationException car leur implémentation est optionnelle : add(), addAll(), remove(), removeAll, retainAll() et clear(). Cette exception peut aussi être levée si l'opération n'a aucune influence sur l'état de la collection.
Chaque implémentation est libre de :
Cette interface définit des méthodes pour des objets capables de parcourir les données d'une collection.
La définition de cette nouvelle interface par rapport à l'interface Enumeration a été justifiée par l'ajout de la fonctionnalité de suppression et la réduction des noms de méthodes.
| Méthode | Rôle |
| boolean hasNext() | Indiquer s'il reste au moins un élément à parcourir dans la collection |
| Object next() | Renvoyer le prochain élément dans la collection |
| void remove() | Supprimer le dernier élément parcouru |
La méthode hasNext() est équivalente à la méthode hasMoreElements() de l'interface Enumeration.
La méthode next() est équivalente à la méthode nextElement() de l'interface Enumeration.
La méthode next() lève une exception de type NoSuchElementException si elle est appelée alors que la fin du parcours des éléments est atteinte. Pour éviter la levée de cette exception, il suffit d'appeler la méthode hasNext() et selon le résultat de conditionner l'appel à la méthode next().
| Exemple ( code Java 1.2 ) : |
Iterator iterator = collection.iterator();
while (iterator.hasNext()) {
System.out.println("objet = "+iterator.next());
}La méthode remove() permet de supprimer l'élément renvoyé par le dernier appel à la méthode next(). Il est ainsi impossible d'appeler la méthode remove() sans un appel correspondant à next() : on ne peut pas appeler deux fois de suite la méthode remove().
| Exemple ( code Java 1.2 ) : suppression du premier élément |
Iterator iterator = collection.iterator();
if (iterator.hasNext()) {
iterator.next();
itérator.remove();
}Si aucun appel à la méthode next() ne correspond à celui de la méthode remove(), une exception de type IllegalStateException est levée
Une collection de type List est une collection simple et ordonnée d'éléments qui autorise les doublons. La liste étant ordonnée, un élément peut être accédé à partir de son index.
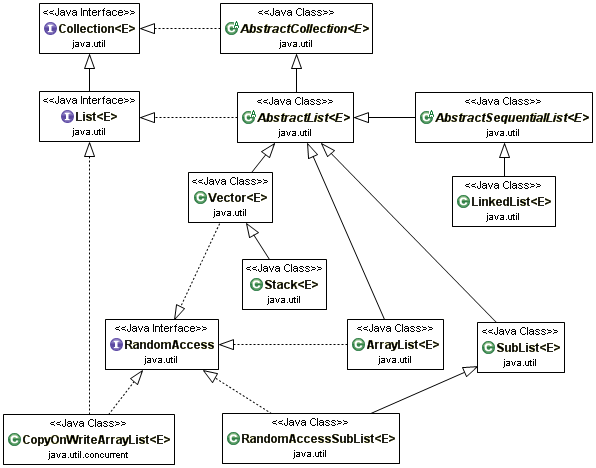
Implémentation |
Rôle |
java.util.Vector<E> |
Une implémentation thread-safe fournie depuis Java 1.0 |
java.util.Stack<E> |
Une implémentation d'une pile : elle hérite de la classe Vector et fournit des opérations pour un comportement de type LIFO (Last In First Out) |
java.util.ArrayList<E> |
Une implémentation qui n'est pas synchronized, donc à n'utiliser que dans un contexte monothread |
java.util.LinkedList<E> |
Une implémentation qui n'est pas synchronized d'une liste doublement chaînée. Les insertions de nouveaux éléments sont très rapides |
java.util.concurrent.CopyOnWriteArrayList<E> |
Une variante thread-safe de la classe ArrayList dans laquelle toutes les opérations de modification du contenu de la liste recréent une nouvelle copie du tableau utilisé pour stocker les éléments de la collection |
Plusieurs classes de l'API JMX implémentent l'interface List : javax.management.AttributeList, javax.management.relation.RoleList et javax.management.relation.RoleUnresolvedList.
Cette interface, ajoutée à Java 1.2, étend l'interface Collection.
Une collection de type List permet :
Pour les listes, une interface particulière est définie pour permettre le parcours dans les deux sens de la liste et réaliser des mises à jour : l'interface ListIterator
L'interface List définit plusieurs méthodes qui permettent un accès aux éléments de la liste à partir d'un index, de gérer les éléments, de rechercher la position d'un élément, d'obtenir une liste partielle (sublist) et d'obtenir des Iterator :
Méthode |
Rôle |
void add(int index, E e) |
Ajouter un élément à la position fournie en paramètre |
boolean addAll(int index, Collection<? extends E> c) |
Ajouter des éléments à la position fournie en paramètre |
E get(int index) |
Retourner l'élément à la position fournie en paramètre |
int indexOf(Object o) |
Retourner la première position dans la liste du premier élément fourni en paramètre. Elle renvoie -1 si l'élément n'est pas trouvé |
int lastIndexOf(Object o) |
Retourner la dernière position dans la liste du premier élément fourni en paramètre. Elle renvoie -1 si l'élément n'est pas trouvé |
ListIterator<E> listIterator() |
Renvoyer un Iterator positionné sur le premier élément de la liste |
ListIterator<E> listIterator(int indx) |
Renvoyer un Iterator positionné sur l'élément dont l'index est fourni en paramètre |
E remove(int index) |
Supprimer l'élément à la position fournie en paramètre |
E set(int index, E e) |
Remplacer l'élément à la position fournie en paramètre |
List<E> subList(int fromIndex, int toIndex) |
Obtenir une liste partielle de la collection contenant les éléments compris entre les index fromIndex inclus et toIndex exclus fournis en paramètres |
La collection de type List obtenue en invoquant la méthode subList() est liée à la collection qui a permis sa création. Une modification faite dans la sous liste est reportée dans la liste originelle. Par contre, si un élément est ajouté ou supprimé dans la liste originelle alors une exception de type ConcurrentModificationException est levée lors d'une utilisation de la sous liste
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.ArrayList;
import java.util.List;
public class TestSubList {
public static void afficherListe(final String nom,
final List<String> sousListe) {
int i = 0;
for (String element : sousListe) {
System.out.format("%s %2d : %s\n", nom, i, element);
i++;
}
}
public static void main(final String[] args) {
List<String> liste = new ArrayList<String>();
liste.add("1");
liste.add("2");
liste.add("3");
liste.add("4");
liste.add("5");
List<String> sousListe = liste.subList(1, 4);
afficherListe("sous liste", sousListe);
System.out.println("");
sousListe.remove(1);
afficherListe("liste",liste);
System.out.println("");
afficherListe("sous liste", sousListe);
System.out.println("");
liste.remove(1);
afficherListe("liste", liste);
System.out.println("");
afficherListe("sous liste", sousListe);
System.out.println("");
}
}| Résultat : |
sous liste 0 : 2
sous liste 1 : 3
sous liste 2 : 4
liste 0 : 1
liste 1 : 2
liste 2 : 4
liste 3 : 5
sous liste 0 : 2
sous liste 1 : 4
liste 0 : 1
liste 1 : 4
liste 2 : 5
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.SubList.checkForComodification(Unknown Source)
at java.util.SubList.listIterator(Unknown Source)
at java.util.AbstractList.listIterator(Unknown Source)
at java.util.SubList.iterator(Unknown Source)
at com.jmdoudoux.test.collections.TestSubList.afficherListe(TestSubList.java:11)
at com.jmdoudoux.test.collections.TestSubList.main(TestSubList.java:39)Remarque : il est préférable d'utiliser un Iterator pour parcourir les éléments d'une collection de type List plutôt que de faire une boucle sur son nombre d'éléments et d'obtenir chaque élément en utilisant son indice.
Le framework propose des classes qui implémentent l'interface List : Vector, ArrayList, LinkedList et CopyOnWriteArrayList.
La classe Vector, présente depuis Java 1.0, est un tableau dont la taille peut varier selon le nombre d'éléments qu'il contient.
Lors de la création d'une instance de type Vector, il est possible de lui préciser une capacité initiale et une taille d'incrémentation en utilisant la surcharge correspondante du constructeur.
Toutes les méthodes de la classe Vector sont synchronized : elle est donc moins performante que la classe ArrayList car elle est thread-safe.
La classe Vector est antérieure à l'API Collections : elle a été mise à jour ultérieurement pour implémenter l'interface Liste. Il y a de ce fait plusieurs méthodes redondantes comme par exemple les méthodes add() et addElement().
Avant l'API Collections la classe Vector était fréquemment utilisée : il est préférable d'utiliser une des implémentations de l'API Collections.
Les éléments sont stockés dans l'ordre dans lequel ils sont ajoutés dans la collection. Un élément peut être ajouté ou supprimé à n'importe qu'elle position dans la collection.
Les tableaux font partis du langage Java et sont faciles à utiliser mais leur taille ne peut pas varier. La classe ArrayList, ajoutée à Java 1.2, est un tableau d'objets dont la taille est dynamique : elle utilise un tableau dont la taille s'adapte automatiquement au nombre d'éléments de la collection. Cette adaptation a cependant un coût car elle nécessite l'instanciation d'un nouveau tableau et la copie des éléments dans ce nouveau tableau.
Elle hérite de la classe AbstractList donc elle implémente l'interface List.
Le fonctionnement de cette classe est similaire à celui de la classe Vector. La différence avec la classe Vector est que cette dernière est multithread (toutes ses méthodes sont synchronisées). Pour une utilisation dans un thread unique, la synchronisation des méthodes est inutile et coûteuse. Il est alors préférable d'utiliser un objet de la classe ArrayList.
La classe ArrayList est l'implémentation la plus simple de l'interface List. Elle présente plusieurs caractéristiques :
La classe ArrayList dispose de plusieurs constructeurs :
Constructeur |
Rôle |
ArrayList() |
Créer une instance vide de la collection avec une capacité initiale de 10 |
ArrayList(Collection<? extends E> c) |
Créer une instance contenant les éléments de la collection fournie en paramètre dans l'ordre obtenu en utilisant son iterator |
ArrayList(int initialCapacity) |
Créer une instance vide de la collection avec la capacité initiale fournie en paramètre |
Elle définit plusieurs méthodes dont les principales sont :
| Méthode | Rôle |
| boolean add(Object) | Ajouter un élément à la fin du tableau |
| boolean addAll(Collection) | Ajouter tous les éléments de la collection fournie en paramètre à la fin du tableau |
| boolean addAll(int, Collection) | Ajouter tous les éléments de la collection fournie en paramètre dans la collection à partir de la position précisée |
| void clear() | Supprimer tous les éléments du tableau |
| void ensureCapacity(int) | Augmenter la capacité du tableau pour s'assurer qu'il puisse contenir le nombre d'éléments passé en paramètre |
| Object get(index) | Renvoyer l'élément du tableau dont la position est précisée |
| int indexOf(Object) | Renvoyer la position de la première occurrence de l'élément fourni en paramètre |
| boolean isEmpty() | Indiquer si le tableau est vide |
| int lastIndexOf(Object) | Renvoyer la position de la dernière occurrence de l'élément fourni en paramètre |
| Object remove(int) | Supprimer dans le tableau l'élément fourni en paramètre |
| void removeRange(int, int) | Supprimer tous les éléments du tableau de la première position fournie incluse jusqu'à la dernière position fournie exclue |
| Object set(int, Object) | Remplacer l'élément à la position indiquée par celui fourni en paramètre |
| int size() | Renvoyer le nombre d'éléments du tableau |
| void trimToSize() | Ajuster la capacité du tableau sur sa taille actuelle |
Chaque instance de type ArrayList possède une capacité qui correspond à la taille du tableau de stockage des éléments : c'est donc le nombre total d'éléments qu'il est possible d'insérer avant d'agrandir le tableau. Cette capacité a donc une relation avec le nombre d'éléments contenus dans la collection : elle est toujours au moins supérieure ou égale à la taille de la collection. La capacité de la collection est automatiquement ajustée selon les besoins lors de l'ajout d'un élément. Cette capacité et le nombre d'éléments de la collection déterminent si le tableau doit être agrandi.
Si un nombre important d'éléments doit être ajouté, il est possible de forcer l'agrandissement de cette capacité avec la méthode ensureCapacity() : elle permet de demander que le tableau puisse au moins accepter le nombre d'éléments fourni en paramètre. Cela peut améliorer les performances en changeant la taille une seule fois si de nombreux éléments doivent être ajoutés plutôt que de changer la taille plusieurs fois selon les besoins. Son usage évite une perte de temps liée au recalcul de la taille de la collection. Un constructeur permet de préciser la capacité initiale.
Lors de l'ajout d'un élément dans la collection, si le tableau de stockage est trop petit alors un nouveau, plus grand, est créé pour contenir les éléments courants plus le nouvel élément. Le temps d'ajout d'un élément n'est donc pas constant. Les temps d'exécution de l'insertion ou de suppression d'un élément à une position quelconque est aussi variable puisque cela peut nécessiter l'adaptation de la position d'autres éléments.
Lors de l'ajout ou du retrait d'un élément, la collection doit réindexer ses éléments. Si la taille de la collection est importante et qu'il y a de nombreux ajouts et suppressions d'éléments alors il est préférable d'utiliser une collection de type LinkedList.
Par défaut, les méthodes de la classe ArrayList ne sont pas synchronized : si plusieurs threads doivent modifier le contenu de la collection, il faut utiliser une instance retournée par la méthode synchronizedList() de la classe Collections.
List liste = Collections.synchronizedList(new ArrayList());
Les Iterator et les ListIterator de la classe ArrayList sont de type fail-fast : ils peuvent lever une exception de type ConcurrentModificationException si une modification du nombre d'éléments intervient durant le parcours sans utiliser leurs méthodes add() ou remove().
L'API Collections propose deux solutions pour convertir un tableau en ArrayList :
La méthode Arrays.asList() est facile à utiliser mais les éléments du tableau et de la liste sont liés. Les modifications faites aux éléments du tableau sont propagées dans la liste. Toute tentative de modification de la liste lève une exception de type UnsupportedOperationException.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class ArrayToArrayList {
public static void main(final String[] args) {
String[] tableau = { "A", "B", "C", "D" };
List<String> liste = new ArrayList<String>();
System.out.println("Contenu du tableau");
for (String str : tableau) {
System.out.print(" " + str);
}
liste = Arrays.asList(tableau);
System.out.println("\nContenu de la liste");
for (String str : liste) {
System.out.print(" " + str);
}
System.out.println("\n");
tableau[0] = "AA";
System.out.println("\nContenu de la liste");
for (String str : liste) {
System.out.print(" " + str);
}
liste.add("E");
System.out.println("\nContenu du tableau");
for (String str : tableau) {
System.out.print(" " + str);
}
}
}| Résultat : |
Contenu du tableau
A B C D
Contenu de la liste
A B C D
Contenu de la liste
AA B C D
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at com.jmdoudoux.test.collections.ArrayToArrayList.main(ArrayToArrayList.java:35)La méthode Collections.addAll() copie les éléments. Les deux objets peuvent alors être modifiés de manière indépendante.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class ArrayToArrayList {
public static void main(final String[] args) {
String[] tableau = { "A", "B", "C", "D" };
List<String> liste = new ArrayList<String>();
Collections.addAll(liste, tableau);
System.out.println("Contenu du tableau");
for (String str : tableau) {
System.out.print(" " + str);
}
System.out.println("\nContenu de la liste");
for (String str : liste) {
System.out.print(" " + str);
}
tableau[0] = "AA";
liste.add("E");
System.out.println("\nContenu du tableau");
for (String str : tableau) {
System.out.print(" " + str);
}
System.out.println("\nContenu de la liste");
for (String str : liste) {
System.out.print(" " + str);
}
}
}| Résultat : |
Contenu du tableau
A B C D
Contenu de la liste
A B C D
Contenu du tableau
AA B C D
Contenu de la liste
A B C D E
La classe LinkedList, ajoutée à Java 1.2, est une implémentation d'une liste doublement chaînée dans laquelle les éléments de la collection sont reliés par des pointeurs. La suppression ou l'ajout d'un élément se fait simplement en modifiant des pointeurs.
Elle hérite de la classe AbstractSequentialList et implémente toutes les méthodes, même celles optionnelles, de l'interface List. Elle implémente l'interface Deque à partir de Java 6.
Elle présente plusieurs caractéristiques :
La classe LinkedList possède plusieurs constructeurs :
Constructeur |
Rôle |
LinkedList() |
Créer une nouvelle instance vide |
LinkedList(Collection<? extends E> c) |
Créer une nouvelle instance contenant les éléments de la collection fournie en paramètre triés dans l'ordre obtenu par son Iterator |
| Exemple ( code Java 1.2 ) : |
LinkedList listeChainee = new LinkedList();
listeChainee.add("element 1");
listeChainee.add("element 2");
listeChainee.add("element 3");
Iterator iterator = listeChainee.iterator();
while (iterator.hasNext()) {
System.out.println("objet = "+iterator.next());
}La méthode toString() renvoie une chaîne qui contient tous les éléments de la liste.
Plusieurs méthodes pour ajouter, supprimer ou obtenir le premier ou le dernier élément de la liste permettent d'utiliser cette classe pour gérer une pile ou une file :
| Méthode | Rôle |
| void addFirst(Object) | Insèrer l'objet au début de la liste |
| void addLast(Object) | Insèrer l'objet à la fin de la liste |
| Object getFirst() | Renvoyer le premier élément de la liste |
| Object getLast() | Renvoyer le dernier élément de la liste |
| Object removeFirst() | Supprimer le premier élément de la liste et renvoie l'élément qui est devenu le premier |
| Object removeLast() | Supprimer le dernier élément de la liste et renvoie l'élément qui est devenu le dernier |
Une liste chaînée gère une collection de façon ordonnée : l'ajout d'un élément peut se faire au début ou à la fin de la collection. L'utilisation d'une LinkedList est plus avantageuse par rapport à une ArrayList lorsque des éléments doivent être ajoutés ou supprimés de la collection en dehors de son début ou de sa fin. Dans ce cas, le temps d'exécution des opérations se fait toujours de manière constant puisqu'elles consistent simplement en la manipulation de pointeurs.
De par les caractéristiques d'une liste chaînée, il n'existe pas de moyen d'obtenir un élément de la liste directement. Pourtant, la méthode contains() permet de savoir si un élément est contenu dans la liste et la méthode get() permet d'obtenir l'élément à la position fournie en paramètre. Il ne faut toutefois pas oublier que ces méthodes parcourent la liste jusqu'à obtention du résultat, ce qui peut être particulièrement gourmand en terme de temps de réponse surtout si la méthode get() est appelée dans une boucle. Pour cette raison, il ne faut surtout pas utiliser la méthode get() pour parcourir la liste.
Une collection de type ArrayList permet un accès direct à un élément dans un temps constant. L'accès direct à un élément d'une collection de type LinkedList est beaucoup moins performant car elle doit parcourir tous les éléments successivement depuis le premier élément jusqu'à l'élément désiré.Les méthodes de la classe LinkedList ne sont pas synchronized. Si plusieurs threads doivent accéder à la collection avec au moins un d'entre-eux qui modifie la structure de la liste (ajout ou suppression d'un élément) alors il faut créer une instance de type List en invoquant la méthode synchronizedList() de la classe Collections en lui passant l'instance de type List.
List liste = Collections.synchronizedList(new LinkedList());
Les Iterator obtenus en invoquant les méthodes iterator() ou listIterator() sont de type fail-fast : une exception de type ConcurrentModificationException est généralement levée lors du parcours des Iterator si la structure de la collection est modifiée.
L'ajout d'un élément après n'importe quel élément est lié à la position courante lors d'un parcours : pour répondre à ce besoin, l'interface qui permet le parcours de la collection est une sous-classe de l'interface Iterator : l'interface ListIterator.
Comme les Iterator sont utilisés pour faire des mises à jour dans la liste, une exception de type ConcurrentModificationException est levée si un iterator parcourt la liste alors qu'une mise à mises à jour est faite (ajout ou suppression d'un élément dans la liste). Pour gérer facilement cette situation, il est préférable si l'on sait qu'il y a des mises à jour à faire de n'avoir qu'un seul iterator qui soit utilisé.
| Exemple ( code Java 1.2 ) : |
LinkedList listeChainee = new LinkedList();
Iterator iterator = listeChainee.iterator();
listeChainee.add("element 1");
listeChainee.add("element 2");
listeChainee.add("element 3");
while (iterator.hasNext()) {
System.out.println("objet = "+iterator.next());
}| Résultat : |
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.LinkedList$ListItr.checkForComodification(LinkedList.java:761)
at java.util.LinkedList$ListItr.next(LinkedList.java:696)
at snippet.Snippet.main(Snippet.java:14)Il existe plusieurs différences entre une ArrayList et une LinkedList :
L'interface ListIterator définit des fonctionnalités d'un Iterator permettant aussi le parcours en sens inverse de la collection, l'ajout d'un élément ou la modification du courant.
En plus des méthodes définies dans l'interface Iterator dont elle hérite, l'interface ListIterator définit plusieurs méthodes :
Méthode |
Rôle |
void add(E e) |
Ajouter un élément dans la collection |
boolean hasPrevious() |
Retourner true si l'élément courant possède un élément précédent |
int nextIndex() |
Retourner l'index de l'élément qui serait retourné en invoquant la méthode next() |
E previous() |
Retourner l'élément précédent dans la liste |
int previousIndex() |
Retourner l'index de l'élément qui serait retourné en invoquant la méthode previous() |
void set(E e) |
Remplacer l'élément courant par celui fourni en paramètre |
La méthode add() de cette interface ne retourne pas un booléen indiquant que l'ajout a réussi.
Pour ajouter un élément en début de liste, il suffit d'appeler la méthode add() sans avoir appelé une seule fois la méthode next(). Pour ajouter un élément en fin de la liste, il suffit d'appeler la méthode next() autant de fois que nécessaire pour atteindre la fin de la liste et d'appeler la méthode add(). Plusieurs appels à la méthode add() successifs, ajoutent les éléments à la position courante dans l'ordre d'appel de la méthode add().
Les méthodes set() et remove() agissent sur l'élément courant qui correspond à l'élément obtenu par la dernière invocation de la méthode next() ou previous(). Elles lèvent une exception de type IllegalStateException s'il n'y a pas d'élément courant.
L'utilisation d'un wrapper synchronized d'une ArrayList n'est pas toujours indiquée lorsqu'il y a beaucoup de lectures car celles-ci sont aussi synchronized dans ce cas, ce qui peut introduire de la contention si plusieurs threads effectuent des lectures concurrentes.
La classe CopyOnWriteArrayList, ajoutée à Java 1.5, est une variante thread-safe de la classe ArrayList dans laquelle toutes les opérations de modification du contenu de la liste recréent une nouvelle copie du tableau utilisé pour stocker les éléments de la collection.
En interne, les opérations de modification du contenu de la collection s'effectuent sur une nouvelle copie du tableau des éléments, ce qui permet à d'autres threads de lire le contenu de la collection sans surcoût de synchronisation.
Elle implémente les interfaces List et RandomAccess.
Elle présente plusieurs caractéristiques :
Elle possède trois constructeurs :
Constructeur |
Rôle |
CopyOnWriteArrayList() |
Créer une collection vide |
CopyOnWriteArrayList(Collection<? extends E> c) |
Créer une collection initialisée avec les éléments de la collection fournie en paramètre insérés dans l'ordre de l'itérateur de cette collection |
CopyOnWriteArrayList(E[] toCopyIn) |
Créer une collection initialisée avec les éléments du tableau fourni en paramètre |
La méthode addIfAbsent() permet d'ajouter de manière atomique un élément qui n'appartient pas à la collection.
La méthode addAllAbsent(Collection< ? extends E>) permet d'ajouter de manière atomique les éléments de la collection en paramètre qui n'appartiennent pas déjà à la collection.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Iterator;
import java.util.List;
import java.util.Random;
import java.util.concurrent.CopyOnWriteArrayList;
public class TestCopyOnWriteArrayList {
static Thread modifThread;
static Thread parcoursThread;
private static void lancerModifThread(final CopyOnWriteArrayList<String> list) {
modifThread = new Thread(new Runnable() {
long compteur = 0;
@Override
public void run() {
while (!Thread.interrupted()) {
int taille = list.size();
Random random = new Random();
if (random.nextBoolean()) {
if (taille > 1) {
list.remove(random.nextInt(taille - 1));
}
} else {
if (taille < 10) {
list.addIfAbsent("Element " + compteur);
}
}
compteur++;
}
System.out.println("Arret du thread modif");
}
});
modifThread.start();
}
private static void lancerParcoursThread(final List<String> list) {
parcoursThread = new Thread(new Runnable() {
@Override
public void run() {
while (!Thread.interrupted()) {
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
String element = iter.next();
System.out.println(element);
}
System.out.println("");
}
System.out.println("Arret du thread parcours");
}
});
parcoursThread.start();
}
public static void main(final String[] args) {
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<String>();
lancerParcoursThread(list);
lancerModifThread(list);
try {
Thread.sleep(10000);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
modifThread.interrupt();
parcoursThread.interrupt();
}
}Les Iterator créés par cette collection parcourent une copie du tableau au moment de la création de leurs instances. Le contenu de ce tableau ne peut pas être modifié : les méthodes de l'Iterator qui permettent de modifier le contenu de la collection comme la méthode remove() lèvent une exception de type UnsupportedOperationException. Un Iterator ne peut donc pas lever d'exception de type ConcurrentModificationException.
L'utilisation de la classe CopyOnWriteArrayList, s'il y a de nombreuses mises à jour de ses éléments, implique un surcoût de mémoire et de temps d'exécution. Son usage est limité ; un bon exemple d'utilisation de la classe CopyOnWriteArrayList est pour stocker les listeners d'un JavaBean pour lequel il y a beaucoup de lectures et peu d'écritures normalement.
S'il n'y a aucun accès concurrent sur la collection, le choix doit se faire entre les classes ArrayList et LinkedList. Ce choix dépendant de l'utilisation qui sera faite de la collection :
Un élément peut être accédé directement par son index dans une ArrayList, ce qui n'est pas possible avec une LinkedList sauf pour le premier et le dernier élément.
Si les accès concurrents doivent être gérés alors il y a deux cas de figure :
Le tableau ci-dessous compare les performances de certaines fonctionnalités de base de différentes implémentations de type List.
get |
add |
contains |
next |
remove(0) |
iterator.remove |
|
ArrayList |
O(1) |
O(1) |
O(n) |
O(1) |
O(n) |
O(n) |
LinkedList |
O(n) |
O(1) |
O(n) |
O(1) |
O(1) |
O(1) |
CopyOnWriteArrayList |
O(1) |
O(n) |
O(n) |
O(1) |
O(n) |
O(n) |
Une collection de type Set ne permet pas l'ajout de doublons ni l'accès direct à un élément de la collection. Les fonctionnalités de base de ce type de collection sont définies dans l'interface java.util.Set.
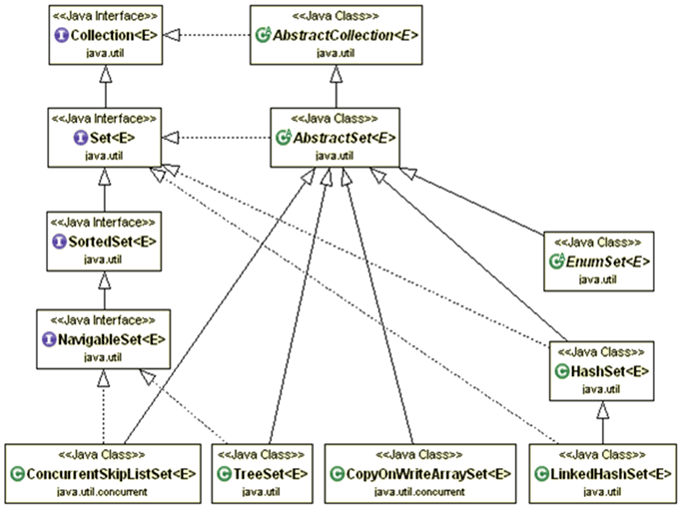
L'interface Set possède deux interfaces filles : SortedSet et NavigableSet.
L'API Collections propose plusieurs implémentations de l'interface Set:
Implémentation |
Rôle |
java.util.HashSet<E> |
La collection n'est pas thread-safe, il est possible d'ajouter un élément null |
java.util.TreeSet<E> |
Les éléments sont triés, la collection n'est pas thread-safe, il est impossible d'ajouter un élément null |
java.util.concurrent.CopyOnWriteArraySet<E> |
La collection est thread-safe : elle créé une nouvelle copie lors de l'invocation de méthode qui modifie le contenu de la collection, se qui rend ces opérations coûteuses. |
java.util.EnumSet<E extends Enum<E>> |
Tous les éléments de la collection doivent appartenir à la même énumération |
java.util.LinkedHashSet<E> |
Similaire à la collection HashSet en définissant l'ordre de parcours qui est celui dans lequel les éléments ont été ajoutés dans la collection |
java.util.concurrent.ConcurrentSkipListSet<E> |
Un ensemble ordonné d'éléments capable de gérer une forte concurrence d'accès |
L'interface Set définit les fonctionnalités d'une collection qui ne peut pas contenir de doublons dans ses éléments.
Les éléments ajoutés dans une collection de type Set doivent réimplémenter leurs méthodes equals() et hashCode(). Ces méthodes sont utilisées lors de l'ajout d'un élément pour déterminer s'il est déjà présent dans la collection. La valeur retournée par hashCode() est recherchée dans la collection :
Le comportement d'une collection de type Set n'est pas spécifié si des objets mutables lui sont ajoutés notamment si des modifications changent le résultat des méthodes equals() et hashCode().
Une collection de type Set peut contenir un objet null mais cela dépend des implémentations. Certaines d'entre-elles ne permettent pas l'ajout de null.
L'interface définit plusieurs méthodes :
Méthode |
Rôle |
boolean add(E e) |
Ajouter l'élément fourni en paramètre à la collection si celle-ci ne le contient pas déjà et renvoyer un booléen qui précise si la collection a été modifiée (l'implémentation de cette opération est optionnelle) |
boolean addAll(Collection<? extends E> c) |
Ajouter tous les éléments de la collection fournie en paramètre à la collection si celle-ci ne les contient pas déjà et renvoyer un booléen qui précise si la collection a été modifiée (l'implémentation de cette opération est optionnelle) |
void clear() |
Retirer tous les éléments de la collection (l'implémentation de cette opération est optionnelle) |
boolean contains(Object o) |
Renvoyer un booléen qui précise si la collection contient l'élément fourni en paramètre |
boolean containsAll(Collection<?> c) |
Renvoyer un booléen qui précise si tous les éléments de la collection fournie en paramètre sont contenus dans la collection |
boolean equals(Object o) |
Comparer l'égalité de la collection avec l'objet fourni en paramètre. L'égalité est vérifiée si l'objet est de type Set, que les deux collections ont le même nombre d'éléments et que chaque élément d'une collection est contenu dans l'autre |
int hashCode() |
Retourner la valeur de hachage de la collection |
boolean isEmpty() |
Renvoyer un booléen qui précise si la collection est vide |
Iterator<E> iterator() |
Renvoyer un Iterator sur les éléments de la collection |
boolean remove(Object o) |
Retirer l'élément fourni en paramètre de la collection si celle-ci le contient et renvoyer un booléen qui précise si la collection a été modifiée (l'implémentation de cette opération est optionnelle) |
boolean removeAll(Collection<?> c) |
Retirer les éléments fournis en paramètres de la collection si celle-ci les contient et renvoyer un booléen qui précise si la collection a été modifiée. (l'implémentation de cette opération est optionnelle) |
boolean retainAll(Collection<?> c) |
Retirer tous les éléments de la collection qui ne sont pas dans la collection fournie en paramètre (l'implémentation de cette opération est optionnelle) |
int size() |
Renvoyer le nombre d'éléments de la collection. Si ce nombre dépasse Integer.MAX_VALUE alors la valeur retournée est MAX_VALUE |
Object[] toArray() |
Renvoyer un tableau des éléments de la collection |
<T> T[] toArray(T[] a) |
Renvoyer un tableau des éléments de la collection dont le type est celui fourni en paramètre |
Il est possible d'utiliser un Iterator pour parcourir les éléments de la collection.
L'invocation de la méthode add() avec en paramètre un élément déjà présent dans la collection n'aucun effet.
L'interface Set possède deux interfaces filles : SortedSet et NavigableSet.
L'API Collections propose plusieurs implémentations de l'interface Set : ConcurrentSkipListSet, CopyOnWriteArraySet, EnumSet, HashSet, LinkedHashSet et TreeSet.
Il faut choisir judicieusement l'implémentation à utiliser selon ses besoins de performance des méthodes add(), contains(), de l'itération sur la collection et l'ordre dans lequel les éléments sont retournés.
L'interface SortedSet, ajoutée à Java 1.2, définit les fonctionnalités pour une collection de type Set qui garantit l'ordre ascendant du parcours de ses éléments.
L'interface SortedSet hérite de l'interface Set et propose plusieurs méthodes :
Méthode |
Rôle |
E first() |
Retourner le premier élément de la collection |
E last() |
Retourner le dernier élément de la collection |
SortedSet headSet(E toElement) |
Retourner un sous-ensemble des premiers éléments de la collection jusqu'à l'élément fourni en paramètre exclus |
SortedSet tailSet(E fromElement) |
Retourner un sous-ensemble contenant les derniers éléments de la collection à partir de celui fourni en paramètre inclus |
SortedSet subSet(E fromElement, E toElement) |
Retourner un sous-ensemble des éléments dont les bornes sont ceux fournis en paramètres. fromElement est inclus et toElement est exclus. Si les deux éléments fournis en paramètres sont les mêmes, la méthode renvoie une collection vide |
Comparator< ? super E> comparator() |
Renvoyer l'instance de type Comparator associée à la collection ou null s'il n'y en a pas |
L'ordre des éléments peut être défini de deux manières :
L'interface SortedSet ne précise pas comment la collection va utiliser l'une ou l'autre de ces options. Généralement, les implémentations définissent un constructeur particulier qui attend en paramètre une instance de type Comparator. Si une telle instance n'est pas fournie alors c'est l'ordre naturel des objets contenus dans la collection qui est utilisé.
Un collection de type Set utilise la méthode equals() pour vérifier si un élément est déjà présent ou non dans la collection. Une collection de type SortedSet utilise la méthode compareTo() lors de l'utilisation de l'ordre naturel de ses éléments. Il est donc important que l'implémentation des méthodes equals() et compareTo() soient cohérentes.
Java 6 propose deux implémentations de l'interface SortedSet : java.util.TreeSet et java.util.concurrent.ConcurrentSkipListSet.
L'interface NavigableSet qui hérite de l'interface SortedSet définit des fonctionnalités qui permettent le parcours de la collection dans l'ordre ascendant ou descendant et d'obtenir des éléments proches d'un autre élément.
Méthode |
Rôle |
E ceiling(E e) |
Retourner le plus petit élément qui soit plus grand ou égal à celui fourni en paramètre. Renvoie null si aucun élément n'est trouvé |
Iterator<E> descendingIterator() |
Retourner un Iterator qui permet le parcours dans un ordre descendant des éléments de la collection |
NavigableSet<E> descendingSet() |
Retourner un ensemble parcourable dans le sens inverse de l'ordre de la collection actuelle |
E floor(E e) |
Retourner le plus grand élément qui soit plus petit ou égal à celui fourni en paramètre. Renvoie null si aucun élément n'est trouvé |
SortedSet<E> headSet(E toElement) |
Retourner un ensemble qui contient les éléments de la collection qui sont strictement plus petits que celui fourni en paramètre |
NavigableSet<E> headSet(E toElement, boolean inclusive) |
Retourner un ensemble parcourable qui contient les éléments de la collection qui sont strictement plus petits (ou plus petits ou égaux si le paramètre inclusive vaut true) que celui fourni en paramètre |
E higher(E e) |
Retourner le plus petit élément qui soit strictement plus grand que celui fourni en paramètre. Renvoie null si aucun élément n'est trouvé |
Iterator<E> iterator() |
Retourner un Iterator qui permet le parcours des éléments dans l'ordre ascendant |
E lower(E e) |
Retourner le plus grand élément qui soit strictement plus petit que celui fourni en paramètre. Renvoie null si aucun élément n'est trouvé |
E pollFirst() |
Retourner le premier élément et le retirer de la collection. Renvoie null si la collection est vide |
E pollLast() |
Retourner le dernier élément et le retirer de la collection. Renvoie null si la collection est vide |
NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) |
Retourner un sous-ensemble parcourable qui contient les éléments compris entre les deux éléments fournis en paramètres. Un booléen permet de préciser si chaque borne doit être incluse ou non. |
SortedSet<E> subSet(E fromElement, E toElement) |
Retourner un sous-ensemble qui contient les éléments compris entre le premier fourni en paramètre inclus et le second exclu |
SortedSet<E> tailSet(E fromElement) |
Retourner un sous-ensemble des éléments qui sont plus grands ou égaux à celui fourni en paramètre |
NavigableSet<E> tailSet(E fromElement, boolean inclusive) |
Retourner un ensemble parcourable qui contient les éléments de la collection qui sont strictement plus grands (ou plus grands ou égaux si le paramètre inclusive vaut true) que celui fourni en paramètre |
Il est recommandé aux implémentations de cette interface de ne pas permettre d'accepter la valeur null dans la collection pour éviter l'ambiguité lorsque certaines méthodes renvoient null.
L'API Collections propose deux implémentations de cette interface : TreeSet et ConcurrenSkipListSet.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Iterator;
import java.util.NavigableSet;
import java.util.Set;
import java.util.TreeSet;
public class TestNavigableSet {
public static void afficherSet(final Set<String> set) {
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
System.out.print(element);
if (iterator.hasNext()) {
System.out.print(", ");
} else {
System.out.println("");
}
}
}
public static void main(final String[] args) {
NavigableSet<String> set = new TreeSet<String>();
for (int i = 1; i < 10; i++) {
set.add("" + i);
}
System.out.println(set);
System.out.println("ceiling(5)=" + set.ceiling("5"));
System.out.println("floor(5)" + set.floor("5"));
System.out.println("higher(5)=" + set.higher("5"));
System.out.println("lower(5)=" + set.lower("5"));
System.out.print("Ordre descendant=");
afficherSet(set.descendingSet());
System.out.print("headSet(5)=");
afficherSet(set.headSet("5"));
System.out.print("headSet(5,true)=");
afficherSet(set.headSet("5", true));
System.out.print("subSet(3,5)=");
afficherSet(set.subSet("3", "5"));
System.out.print("subSet(3,true,5,true)=");
afficherSet(set.subSet("3", true, "5", true));
System.out.print("tailSet(5)=");
afficherSet(set.tailSet("5"));
System.out.print("tailSet(5,true)=");
afficherSet(set.tailSet("5", true));
System.out.println("pollFirst()=" + set.pollFirst());
System.out.println("pollLast()=" + set.pollLast());
System.out.println(set);
}
}| Résultat : |
[1, 2, 3, 4, 5, 6, 7, 8, 9]
ceiling(5)=5
floor(5)5
higher(5)=6
lower(5)=4
Ordre descendant=9, 8, 7, 6, 5, 4, 3, 2, 1
headSet(5)=1, 2, 3, 4
headSet(5,true)=1, 2, 3, 4, 5
subSet(3,5)=3, 4
subSet(3,true,5,true)=3, 4, 5
tailSet(5)=5, 6, 7, 8, 9
tailSet(5,true)=5, 6, 7, 8, 9
pollFirst()=1
pollLast()=9
[2, 3, 4, 5, 6, 7, 8]
La classe HashSet, ajoutée à Java 1.2, est une implémentation simple de l'interface Set qui utilise une HashMap. La clé de la HashMap est la valeur de hachage de l'élément.
La classe HashSet présente plusieurs caractéristiques :
La classe HashSet utilise en interne une HashMap dont la clé est l'élément et dont la valeur est une instance d'Object identique pour tous les éléments.
La classe HashSet possède plusieurs constructeurs :
Constructeur |
Rôle |
HashSet() |
Créer une nouvelle instance vide dont la HashMap interne utilisera une capacité initiale et un facteur de charge par défaut |
HashSet(Collection<? extends E> c) |
Créer une nouvelle instance contenant les éléments de la collection fournie en paramètre |
HashSet(int initialCapacity) |
Créer une nouvelle instance vide dont la HashMap interne utilisera la capacité initiale fournie en paramètre et un facteur de charge par défaut |
HashSet(int initialCapacity, float loadFactor) |
Créer une nouvelle instance vide dont la HashMap interne utilisera la capacité initiale et un facteur de charge par défaut |
Il est possible de préciser, dans la surcharge de certains constructeurs, la capacité initiale de la collection et le facteur de charge (par défaut, la taille est 16 et le facteur de charge est 0,75). Le facteur de charge est une valeur qui précise le pourcentage de remplissage de la collection à atteindre avant d'augmenter sa taille.
Les classes des éléments qui sont insérés dans la collection doivent impérativement définir les méthodes equals() et hashCode() pour respecter la cohérence entre ces deux méthodes qui est imposée par contrat par Java.
La méthode add() permet d'ajouter un élément dans la collection : elle renvoie un booléen qui précise si l'opération a réussi ou non. Elle échoue par exemple si l'élément est déjà présent dans la collection.
| Exemple ( code Java 1.2 ) : |
import java.util.*;
public class TestHashSet {
public static void main(String args[]) {
Set set = new HashSet();
set.add("CCCCC");
set.add("BBBBB");
set.add("DDDDD");
set.add("BBBBB");
set.add("AAAAA");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}| Résultat : |
AAAAA
DDDDD
BBBBB
CCCCC
La classe TreeSet, ajoutée à Java 1.2, stocke ses éléments de manière ordonnée en les comparant entre-eux. Cette classe permet d'insérer des éléments dans n'importe quel ordre et de restituer ces éléments dans un ordre précis lors de son parcours.
Une collection de type TreeSet ne peut pas contenir de doublons.Elle implémente l'interface NavigableSet depuis Java 6
L'ordre des éléments de la collection peut être défini par deux moyens :
Le mécanisme utilisé pour la comparaison lors de la définition de l'ordre (Comparable ou Comparator) doit être cohérent avec l'implémentation de la méthode equals() : si element1.compareTo(element2) == 0 alors obligatoirement element1.equals(element2) == true.
Cela implique que l'algorithme de comparaison des éléments soit suffisamment discriminant pour éviter les égalités qui seraient alors interprétés comme des doublons qui n'en sont pas en réalité.
Par exemple : pour des personnes, il n'est pas possible de comparer uniquement le nom et le prénom car dans ce cas, il ne pourrait pas y avoir d'homonymes dans la collection. Il faut en plus comparer un élément discriminant ou faire la comparaison sur une valeur unique comme un numéro de sécurité sociale ou un identifiant.
En interne, la classe TreeSet utilise un arbre binaire pour stocker ses éléments. Chaque élément est encapsulé dans un noeud (node). Chaque noeud peut faire référence à aucun, un ou deux autres noeuds.
Si un noeud fait référence à un ou deux autres noeuds alors il est le noeud parent de ses noeuds fils : ceci permet de construire l'arborescence des éléments de l'arbre. Si un noeud n'a pas de fils alors c'est une feuille de l'arbre.
L'ajout d'un noeud fils suit toujours les mêmes règles :
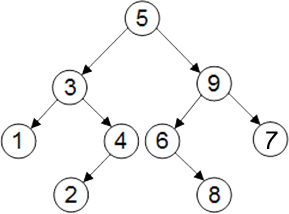
Un seul noeud dans l'arbre ne possède pas de parent : le noeud racine.
La recherche d'un élément dans un arbre binaire est rapide : elle nécessite généralement un temps proportionnel à log(n) où n est le nombre d'éléments dans la collection.
Le parcours commence par le noeud racine qui est comparé à l'élément recherché.
S'il est égal, l'élément est trouvé sinon la branche de l'arbre selon que la valeur est plus petite ou plus grande est parcourue.
A chaque noeud la valeur est testée par rapport à l'élément recherché
Si le dernier parcouru ne correspond pas à la valeur recherchée, alors l'élément n'est pas dans la collection.
Ce mode de fonctionnement est efficace si l'ordre d'insertion des éléments est aléatoire : si tous les éléments sont ajoutés dans leur ordre alors le parcours reviendra à parcourir tous les éléments un par un jusqu'à trouver la bonne valeur ou une valeur supérieure auquel cas la valeur n'est pas trouvée.
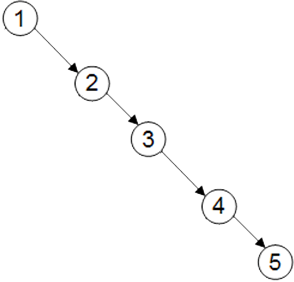
Pour pallier à cette problématique, la classe TreeSet met en oeuvre un algorithme complexe qui va permettre d'équilibrer l'arbre. Un arbre est équilibré lorsque les feuilles de l'arbre sont à peu près à la même distance de la racine de l'arbre. La distance est le nombre de noeuds parent entre la feuille et le noeud racine.
La mise en oeuvre de ce type d'algorithme peut imposer de réorganiser la structure de l'arbre à chaque ajout ou suppression d'un élément. Le maintient d'un arbre parfaitement équilibré peut être très coûteux. Certains algorithmes maintiennent un arbre partiellement équilibré jusqu'à une certaine limite clairement définie par l'algorithme.
Il est intéressant que l'arbre soit parfaitement équilibré si les recherches sont beaucoup plus nombreuses que les opérations d'ajouts ou de suppressions d'éléments. La classe TreeSet ayant pour vocation un usage généraliste, elle met en oeuvre un algorithme nommé Red-Black Tree qui équilibre partiellement l'arbre en garantissant que la distance entre la racine et la feuille la plus éloignée n'est pas plus importante que deux fois la distance entre la racine et la feuille la plus proche. Cet algorithme met en oeuvre plusieurs règles pour réorganiser les éléments de l'arbre pour le maintenir équilibré :
La classe TreeSet stocke en interne ses éléments dans une collection de type TreeMap.
La classe TreeSet possède plusieurs constructeurs :
Constructeur |
Rôle |
TreeSet() |
Créer une instance vide dont l'ordre naturel de tri de ses éléments est utilisé |
TreeSet(Collection<? extends E> c) |
Créer une instance contenant les éléments de la collection fournie en paramètre dont l'ordre naturel de tri de ses éléments est utilisé |
TreeSet(Comparator<? super E> comparator) |
Créer une instance vide dont l'ordre utilisé est celui définit par l'instance de type Comparator fournie en paramètre |
TreeSet(SortedSet<E> s) |
Créer une instance contenant les éléments de la collection fournie en paramètre dont l'ordre est celui utilisé par la collection |
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Iterator;
import java.util.TreeSet;
public class TestTreeSet {
public static void main(final String[] args) {
TreeSet<String> set = new TreeSet<String>();
set.add("CCCCC");
set.add("BBBBB");
set.add("DDDDD");
set.add("BBBBB");
set.add("AAAAA");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
}
}| Résultat : |
AAAAA BBBBB CCCCC DDDDD La classe TreeSet n'est pas thread-safe : comme aucune de ses méthodes n'est synchronized, un seul thread doit pouvoir modifier le contenu de la collection. Si plusieurs threads doivent pouvoir modifier la collection, il faut invoquer la méthode synchronizedSortedSet() de la classe Collections qui va créer un wrapper dont les méthodes sont synchronized.
SortedSet set = Collections.synchronizedSortedSet(new TreeSet());
Avec cette solution, plusieurs threads peuvent modifier la collection mais un seul à la fois, ce qui peut engendrer des dégradations de performances en cas de forte concurrence d'accès. Dans ce cas, il est préférable d'utiliser une autre implémentation de type Set comme la classe ConcurrentSkipListSet.
La classe ConcurrentSkipListSet, ajoutée à Java 1.6, permet de mettre en oeuvre un ensemble ordonné d'éléments capable de gérer une forte concurrence d'accès.
Elle implémente l'interface NavigableSet et utilise en interne une instance de type ConcurrentSkipListMap.
Elle présente plusieurs caractéristiques :
La classe ConcurrentSkipListSet utilise une structure de données de type skip list. Contrairement à un arbre binaire, dans une structure de type skip list, l'organisation n'a pas besoin d'être réajustée lors de l'ajout ou la suppression d'un élément.
La classe ConcurrentSkipListSet possède plusieurs constructeurs :
Constructeur |
Rôle |
ConcurrentSkipListSet() |
Créer une nouvelle instance vide dont les éléments sont triés avec leur ordre naturel |
ConcurrentSkipListSet(Collection<? extends E> c) |
Créer une nouvelle instance contenant les éléments de la collection fournie en paramètre triés avec leur ordre naturel |
ConcurrentSkipListSet(Comparator<? super E> comparator) |
Créer une nouvelle instance vide dont les éléments sont triés en utilisant l'instance de type Comparator fournie en paramètre |
ConcurrentSkipListSet(SortedSet<E> s) |
Créer une nouvelle instance contenant les éléments de la collection fournie en paramètre triés selon l'ordre de cette collection |
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Iterator;
import java.util.concurrent.ConcurrentSkipListSet;
public class TestConcurrentSkipListSet {
public static void main(final String[] args) {
final ConcurrentSkipListSet<MaTache> set = new ConcurrentSkipListSet<MaTache>();
System.out.println("debut");
final Thread modificateur = new Thread(new Runnable() {
@Override
public void run() {
MaTache[] MesTaches = new MaTache[5];
for (int i = 1; i <= 5; i++) {
MesTaches[i - 1] = new MaTache(6 - i, "Tache " + i);
}
for (int j = 1; j <= 100; j++) {
if (j % 2 == 0) {
for (int i = 1; i <= 5; i++) {
MaTache element = MesTaches[i - 1];
System.out.println("insertion element " + element);
set.add(element);
}
System.out.println("taille de la queue=" + set.size());
} else {
for (int i = 1; i <= 5; i++) {
MaTache element = MesTaches[i - 1];
System.out.println("retirer element " + element);
set.remove(element);
}
}
}
}
}, "Modificateur");
modificateur.start();
Thread iterateur = new Thread(new Runnable() {
@Override
public void run() {
int i = 0;
while (modificateur.isAlive()) {
Iterator<MaTache> iterator = set.iterator();
StringBuilder contenu = new StringBuilder("[");
while (iterator.hasNext()) {
contenu.append(iterator.next().getDescription());
if (iterator.hasNext()) {
contenu.append(", ");
}
}
contenu.append("]");
System.out.println("Contenu=" + contenu);
i++;
}
}
}, "iterateur");
iterateur.start();
try {
modificateur.join();
iterateur.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("fin");
}
}La classe ConcurrentSkipListSet est particulièrement utile pour gérer un ensemble ordonné d'éléments qui peut être accédé et modifié par plusieurs threads. L'ajout, la suppression et l'obtention d'un élément de la collection se font de manière concurrente par plusieurs threads.
Les méthodes qui effectuent des opérations sur plusieurs éléments comme addAll(), removeAll() et containsAll() n'offrent aucune garantie de s'exécuter de manière atomique.
Les performances des opérations de base de la classe ConcurrentSkipListSet sont moins bonnes que celles de la classe TreeSet pour une utilisation mono-thread : dans ce cas, il est préférable d'utiliser une instance de type TreeSet.
Le temps d'exécution de la méthode size() n'est pas constant : il est proportionnel au nombre d'éléments de la collection car celle-ci doit reparcourir tous les éléments pour calculer le nombre d'éléments qu'elle contient. Elle ne pose aucun verrou pour maintenir fraîche la valeur du nombre d'éléments dans la collection.
Les Iterator ne lèvent jamais d'exception de type ConcurrentModificationException : il est possible de les utiliser alors que d'autres threads modifient la collection car l'itération se fait sur l'état de la collection au moment de la création de l'instance de l'Iterator.
Les itérations sur les éléments dans l'ordre ascendant sont plus rapides que les itérations dans l'ordre descendant.
La classe CopyOnWriteArraySet, ajoutée à Java 1.5, est une implémentation de type Set qui est thread safe et offre de bonnes performances en lecture.
Elle implémente les interfaces Collection, Set et Iterable.
Elle utilise en interne une instance de type CopyOnWriteArrayList pour stocker les éléments de la collection. Elle présente plusieurs caractéristiques :
La classe CopyOnWriteArraySet possède plusieurs constructeurs :
Constructeur |
Rôle |
CopyOnWriteArraySet () |
Créer une nouvelle instance vide |
CopyOnWriteArraySet (Collection<? extends E> c) |
Créer une nouvelle instance contenant les éléments de la collection fournie en paramètre |
Certaines implémentations sont spécialisées pour être utilisées dans des situations particulières.
C'est notamment le cas de la classe EnumSet qui ne doit être utilisée que pour gérer un ensemble d'énumérations.
La classe CopyOnWriteArraySet ne doit être utilisée que pour des collections thread-safe de petites tailles, où les opérations réalisées sont essentiellement des lectures et où les Iterator ne peuvent pas modifier le contenu de la collection.
Le JDK contient plusieurs implémentations généralistes de l'interface Set qui peuvent selon les besoins :
Ordre des clés |
Pas d'accès concurrent |
Gestion des accès concurrents |
Aucun |
HashSet |
|
Trié |
TreeSet |
ConcurrentSkipListMap |
Fixe |
LinkedHashSet |
CopyOnWriteArraySet |
Si la collection n'est pas utilisée par plusieurs threads, il est possible d'utiliser les classes HashSet, LinkedHashSet et TreeSet. Si les données doivent être triées, il faut utiliser la classe TreeSet. Si les données de la collection doivent être fréquemment parcourues, il est préférable d'utiliser la classe LinkedHashSet.
Si la collection doit être utilisée par plusieurs threads, il faut utiliser la classe ConcurrentSkipListSet ou CopyOnWriteArraySet uniquement si les accès sont essentiellement des lectures. Il est aussi possible d'utiliser une version synchronized d'une implémentation de type Set en utilisant la méthode synchronizedSet() de la classe Collections.
Si les éléments de la collection doivent être triés, il faut utiliser les classes TreeSet ou ConcurrentSkipListSet. Si en plus les accès concurrents doivent être gérés, seule la classe ConcurrentSkipListSet doit être utilisée. Sinon il est préférable d'utiliser la classe TreeSet pour des collections de grandes tailles ou si de nombreuses opérations de suppressions d'éléments doivent être réalisées.
Indépendamment des fonctionnalités, les performances peuvent être un critère important dans le choix d'une implémentation de type Set.
Classe |
add() |
contains() |
next() |
thread-safe |
HashSet |
O(1) |
O(1) |
O(h/n) |
Non |
LinkedHashSet |
O(1) |
O(1) |
O(1) |
Non |
CopyOnWriteArraySet |
O(n) |
O(n) |
O(1) |
Non |
EnumSet |
O(1) |
O(1) |
O(1) |
Oui |
TreeSet |
O(log n) |
O(log n) |
O(log n) |
Oui |
ConcurrentSkipListSet |
O(log n) |
O(log n) |
O(1) |
Oui |
Remarque : dans le tableau ci-dessus, h est la capacité de la collection
Les collections de type Map sont définies et implémentées comme des dictionnaires sous la forme d'associations de paires de type clés/valeurs. La clé doit être unique. En revanche, la même valeur peut être associée à plusieurs clés différentes.
Avant l'apparition du framework Collections, la classe dédiée à cette gestion était la classe Hashtable.
Un objet de type Map permet de lier un objet avec une clé qui peut être un type primitif ou un autre objet. Il est ainsi possible d'obtenir un objet à partir de sa clé.
Au fur et à mesure des versions de Java, des classes et interfaces de type Map ont été ajoutées :
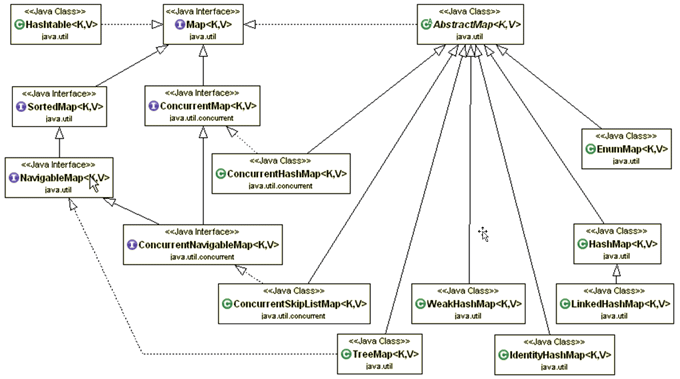
L'interface Map possède plusieurs interfaces filles : SortedMap, NavigableMap, ConcurrentMap et ConcurrentNavigableMap.
L'API Collections propose plusieurs implémentations de l'interface Map :
Classe |
Rôle |
java.util.TreeMap<K,V> |
Map non thread safe dont l'ordre de parcours des clés est garanti |
java.util.Hashtable<K,V> |
Map thread-safe, null ne peut pas être utilisé comme clé |
java.util.HashMap<K,V> |
Similaire à Hashtable mais elle n'est pas thread-safe et null peut être utilisé comme clé |
java.util.concurrent.ConcurrentHashMap<K,V> |
Similaire à Hashtable, avec une gestion des accès concurrents et de meilleures performances |
java.util.WeakHashMap<K,V> |
Map qui va retirer automatiquement les éléments dont les clés ne peuvent plus être utilisées. S'il n'existe plus aucune référence forte dans le tas de la JVM sur un objet utilisé comme clé, alors l'élément correspondant dans la collection sera retiré |
java.util.LinkedHashMap<E> |
Map non thread safe qui conserve les clés dans leur ordre d'insertion |
java.util.IdentityHashMap<K,V> |
Map non thread-safe qui utilise un test d'égalité sur les références (habituellement les implémentations de l'interface Map utilisent l'égalité des objets). Deux clés cle1 et cle2 sont donc égales si cle1==cle2. |
java.util.EnumMap<K,V> |
Map non thread-safe dont les valeurs doivent appartenir à la même énumération |
java.util.IdentityHashMap<K,V> |
Map appropriée lorsque la comparaison des éléments doit se faire sur l'identité des objets et non sur leur égalité (elle n'utilise pas les méthodes equals() et hashCode() pour comparer les clés) |
L'interface java.util.Map<K,V> , ajoutée à Java 1.2, définit les fonctionnalités pour une collection qui associe des clés à des valeurs. Chaque clé ne peut être associée qu'à une seule valeur. Chaque clé d'une Map doit être unique.
L'interface Map de l'API Collections remplace la classe abstraite Dictionary de Java 1.0.
Elle définit plusieurs méthodes pour agir sur la collection :
| Méthode | Rôle |
| void clear() | Supprimer tous les éléments de la collection |
| boolean containsKey(Object) | Indiquer si la clé est contenue dans la collection |
| boolean containsValue(Object) | Indiquer si la valeur est contenue dans la collection |
| Set entrySet() | Renvoyer un ensemble contenant les paires clé/valeur de la collection |
| Object get(Object) | Renvoyer la valeur associée à la clé fournie en paramètre |
| boolean isEmpty() | Indiquer si la collection est vide |
| Set keySet() | Renvoyer un ensemble contenant les clés de la collection |
| Object put(Object, Object) | Insèrer la clé et sa valeur associée fournies en paramètres |
| void putAll(Map) | Insèrer toutes les clés/valeurs de l'objet fourni en paramètre |
| Collection values() | Renvoyer une collection qui contient toutes les valeurs des éléments |
| Object remove(Object) | Supprimer l'élément dont la clé est fournie en paramètre |
| int size() | Renvoyer le nombre d'éléments de la collection |
La méthode keySet() permet d'obtenir un ensemble contenant toutes les clés.
La méthode values() permet d'obtenir une collection contenant toutes les valeurs. La valeur de retour est une Collection et non un ensemble car il peut y avoir des doublons (plusieurs clés peuvent être associées à la même valeur).
Elle définit une interface interne Map.Entry<K,V> qui définit les fonctionnalités pour un objet qui encapsule une paire clé/valeur.Il est recommandé d'utiliser des objets immuables comme clés.
Une collection de type Map ne propose pas directement d'Iterator sur ses éléments : la collection peut être parcourue de trois manières :
L'API Collections propose plusieurs implémentations de l'interface Map notamment HashMap, Hashtable, TreeMap, LinkedHashMap, ConcurrentHashMap, ConcurrentSkipListMap, EnumMap et WeakHashMap.
L'interface java.util.SortedMap<K,V>, ajoutée à Java 1.2, définit les fonctionnalités d'une Map dont les clés sont triées. Elle hérite de l'interface Map.
L'ordre dans les clés est assuré en utilisant l'ordre naturel des éléments (en implémentant l'interface Comparable) ou en fournissant un Comparator à la création de l'instance de la collection. Tous les éléments insérés dans la collection doivent donc implémenter l'interface Comparable ou pouvoir être utilisés par le Comparator associé à la Map selon la solution utilisée. Ils doivent aussi avoir une implémentation de la méthode equals() qui soit en accord avec cette solution car elle est invoquée pour déterminer si la clé est déjà dans la collection.
L'ordre des éléments est respecté lors de l'invocation des méthodes entrySet(), keySet() et values().
Les implémentations de l'interface SortedMap doivent garantir que les Iterator parcourent la collection dans l'ordre des clés.
L'interface SortedMap définit plusieurs méthodes :
Méthode |
Rôle |
Comparator< ? super K) comparator() |
Retourner l'instance de type Comparator associée à la collection ou null si c'est l'ordre naturel qui doit être utilisé |
Set<Map.Entry<K,V>> entrySet() |
Retourner un ensemble des paires clé/valeur de la collection |
K firstKey() |
Retourner la première clé de la collection. Lève une exception de type NoSuchElementException si la collection est vide |
SortedMap<K,V> headMap(K toKey) |
Retourner un sous-ensemble de la collection contenant les éléments dont les clés sont strictement inférieures à celle fournie en paramètre |
Set<K> keySet() |
Retourner un ensemble des clés de la collection |
K lastKey() |
Retourner la dernière clé de la collection. Lève une exception de type NoSuchElementException si la collection est vide |
sortedMap<K, V> subMap(K fromKey, K toKey) |
Retourner un sous-ensemble de la collection contenant les éléments dont les clés sont strictement inférieures à celle fournie en premier paramètre et supérieures ou égales à celle fournie en second paramètre |
SortedMap<K,V> tailMap(K fromKey) |
Retourner un sous-ensemble de la collection contenant les éléments dont les clés sont supérieures ou égales à celle fournie en paramètre |
Collection(V) values() |
Retourner une collection de toutes les valeurs de la Map |
Chaque implémentation de l'interface SortedMap devrait fournir au moins quatre constructeurs (ceci ne peut être qu'une recommandation puisque les constructeurs ne peuvent pas être définis dans une interface) :
Elle possède deux interfaces filles depuis Java 6 : NavigableMap et ConcurrentNavigableMap.
L'API Collections propose deux implémentations de l'interface SortedMap : TreeMap et ConcurrentSkipListMap.
La classe Hashtable, présente depuis Java 1.0, permet d'associer dans une collection des éléments sous la forme de paires clé/valeur.
La classe Hashtable hérite de la classe Dictionary qui n'appartient pas à l'API Collections et a été modifiée, à partir de Java 1.2, pour implémenter l'interface Map et ainsi devenir une classe de l'API Collections.
La classe Hashtable présente plusieurs caractéristiques :
Tous les objets qui sont utilisés comme clés doivent obligatoirement redéfinir les méthodes equals() et hashCode() en respectant le contrat portant sur l'implémentation de ces deux méthodes.
La classe Hashtable est composée de buckets : en fonction de la valeur de hachage de la clé, l'élément est inséré dans un bucket particulier. Plusieurs objets ayant la même valeur de hachage seront dans le même bucket.
La classe Hashtable possède deux propriétés qui affectent ses performances :
Il est important de ne pas utiliser une capacité initiale trop importante ou un facteur de charge trop petit pour ne pas dégrader les performances lors du parcours de la collection.
Lorsque le nombre d'éléments de la collection est supérieur à la taille de la collection multiplié par le facteur de charge alors la collection est agrandie. Cette opération est coûteuse car elle impose un rehash de la collection (reconstruction de sa structure de données liée à un accroissement du nombre de buckets). L'invocation de la méthode rehash() est spécifique à l'implémentation.
La capacité estimée et le facteur de charge de la collection doivent être pris en compte pour définir la capacité initiale afin d'éviter au maximum le nombre d'opérations de type rehash effectué lors de l'agrandissement de la taille de la collection.
Si la collection doit contenir de nombreux éléments, il est donc intéressant de créer son instance avec une capacité initiale suffisament élevée pour contenir les éléments plus une marge correspondant à la capacité multipliée par le facteur de charge. Les performances seront améliorées car cela évitera une ou plusieurs opérations d'agrandissement de la collection.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Hashtable;
public class TestHashtable {
public static void main(final String[] args) {
Hashtable<Integer, String> numbers = new Hashtable<Integer, String>();
numbers.put(1, "Element1");
numbers.put(2, "Element2");
numbers.put(3, "Element3");
String n = numbers.get(2);
if (n != null) {
System.out.println("2 = " + n);
}
}
}| Résultat : |
2 = Element2Les Iterator de cette classe sont de type fail-fast : les instances de type Iterator retournées par la méthode iterator() lèvent généralement une exception de type ConcurrentModificationException si une modification est effectuée dans la collection durant le parcours (exception faite des modifications réalisées avec la méthode remove() de l'Iterator).
La classe HashMap, ajoutée à Java 1.2, est une implémentation de l'interface Map qui utilise une Hashtable. La classe HashMap est similaire à la classe Hashtable sauf qu'elle n'est pas synchronized et qu'elle autorise l'utilisation de la valeur null.
La classe HashMap utilise un tableau de listes chaînées pour le stockage de ses éléments. L'index d'une clé dans le tableau est déterminé grâce à un algorithme utilisant la valeur de hachage de l'objet.
La valeur de hachage n'est pas utilisée directement : l'algorithme fait appel à la méthode hash() de la classe HashMap qui utilise la valeur de hachage pour en déterminer une autre, ceci afin de réduire les risques de collision.
Si deux objets possèdent la même valeur de hachage, il y a une collision car les deux objets doivent être insérés dans le même bucket. Pour gérer les problèmes, le bucket contient une liste chaînée : chaque élément (sa clé et sa valeur) est encapsulé dans une instance de type Entry.
Toutes les méthodes optionnelles de l'interface Map sont implémentées.
La classe HashMap présente plusieurs caractéristiques :
La classe HashMap possède deux propriétés :
Il est important que la valeur de la capacité initiale soit une puissance de 2 : si ce n'est pas le cas la capacité initiale sera la valeur 2n supérieure. Si la capacité c fournie est 2n-1 > c < 2n alors la capacité sera 2n. La valeur de la capacité doit être une puissance de 2 pour permettre à l'algorithme qui détermine l'index dans le tableau à partir de la valeur de hachage de fonctionner.
Le facteur de charge définit le pourcentage de remplissage maximum de la collection avant que celle-ci ne soit agrandie. Si le pourcentage du nombre d'éléments contenus dans la collection par rapport à la capacité de la collection est supérieur au facteur de charge, alors la capacité maximale de la collection est doublée.
La classe HashMap propose plusieurs constructeurs dont certains peuvent préciser la capacité initiale et le facteur de charge.
Pour pouvoir correctement mettre en oeuvre la classe HashMap, il est nécessaire de connaître son mode de fonctionnement.
En interne, une HashMap stocke les paires clé/valeur dans des buckets qui peuvent être vus comme un index de premier niveau. Lors de l'ajout d'un élément ou la recherche d'un élément dans la collection, la valeur de hachage de la clé est utilisée pour déterminer un index dans le tableau des buckets.
Chaque bucket possède une liste chaînée qui stocke les éléments dont la clé possède la même valeur de hachage. Comme deux objets égaux doivent avoir la même valeur de hachage mais que deux objets ayant la même valeur de hachage ne sont pas forcément égaux, une liste chaînée est utilisée pour stocker les éléments ayant la même valeur de hachage.
La classe HashMap possède la classe interne Entry qui implémente l'interface Map.Entry et encapsule une paire clé/valeur. La liste chaînée du bucket contient donc des objets de type Entry qui encapsulent la clé et la valeur. La méthode next() permet d'obtenir l'élément suivant dans la liste.
Lors de l'invocation de la méthode put(), plusieurs opérations sont réalisées :
La classe HashMap accepte la valeur null comme clé : dans ce cas, la clé est placée à l'index 0 dans le tableau.
Plusieurs éléments pouvant être stockés à un même index, il est nécessaire de parcourir ses éléments qui sont dans une liste chaînée, encapsulés dans des objets de type Entry. Le parcours se fait en invoquant la méthode next(). La clé de l'élément courant est comparée à la clé recherchée en utilisant la méthode equals() si les instances sont différentes.
Pour obtenir un élément de la collection grâce à la méthode get(), le mode de fonctionnement est similaire à l'ajout. Lors de l'invocation de la méthode get() :
L'implémentation des méthodes equals() et hashCode() d'objets utilisés comme clés doit respecter les spécifications qui sont imposées par Java. La valeur de hachage de la clé obtenue en invoquant sa méthode hashCode() est utilisée pour calculer l'index du bucket. La méthode equals() des clés est utilisée pour assurer l'unicité des clés dans la collection et pour retrouver le bon élément.
Comme une HashMap repose sur l'utilisation de la valeur de hachage des clés, l'idéal est d'utiliser des instances immuables d'objets dont les méthodes equals() et hashCode() sont correctement implémentées. L'utilisation d'objets immuables comme clés assure, si l'implémentation de la méthode hashCode() est bien faite, que la valeur de hachage de l'objet ne change pas. Ainsi des objets de type String ou des classes de type wrapper de primitives sont de bons candidats pour les clés de la collection.
Il est très important que la valeur de hachage d'un objet utilisé comme clé ne change pas car cette valeur est utilisée pour déterminer le bucket de la collection qui contient l'élément. Si un élément est ajouté dans la collection avec une clé ayant une certaine valeur de hachage et que cette valeur de hachage est différente lors de la recherche de clé dans la collection, l'élément ne sera probablement pas retrouvé alors qu'il est bel et bien dans la collection. Cette recherche échoue car la valeur de hachage à l'ajout place l'élément dans un bucket et la recherche avec une autre valeur de hachage détermine un autre bucket qui ne contient pas l'élément.
Si le facteur de charge est atteint, alors la taille de la collection est agrandie : la taille du tableau contenant les buckets est doublée en recréant une nouvelle instance du tableau. Cette opération implique un recalcul de tous les buckets : cette fonctionnalité est appelée rehash car elle redéfinit toutes les valeurs des index.
Lorsque la collection est redimensionnée, chaque élément est déplacé du tableau initial dans le nouveau tableau dont la taille est doublée. Lors de ce transfert, l'index de l'élément dans le bucket est recalculé, ce qui fait qu'il peut rester le même ou être modifié.
Le temps d'exécution de cette opération est proportionnel à la taille de la collection : pour limiter ses occurrences, il est possible de préciser la capacité initiale de la collection si l'on possède une idée plus ou moins précise du nombre d'éléments que contiendra la collection.
La classe HashMap n'est pas synchronized, elle n'est donc pas thread-safe. Si plusieurs threads doivent ajouter ou supprimer des éléments dans la collection, il faut gérer manuellement la concurrence d'accès. Il est par exemple possible d'utiliser une instance de la collection retournée par la méthode synchronizedMap() de la classe Collections.
Map m = Collections.synchronizedMap(new HashMap());
Une collection de type HashMap n'est pas prévue pour être utilisée par plusieurs threads. Par exemple, une invocation de la méthode get() peut déclencher une boucle infinie si une opération de rehash() est réalisée en même temps que l'insertion d'un élément. Durant l'agrandissement de la collection, les éléments de la liste chaînée d'un bucket sont déplacés dans un nouveau bucket dans leur sens inverse de la liste courante. Si un accès est fait à ce moment là, une boucle infinie peut être engendrée. Ceci peut aussi arriver si deux threads effectuent en même temps une opération de type rehash().
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.HashMap;
import java.util.Map;
class MonElement {
private final int valeur;
public MonElement(final int valeur) {
this.valeur = valeur;
}
@Override
public boolean equals(final Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
MonElement other = (MonElement) obj;
if (valeur != other.valeur) {
return false;
}
return true;
}
@Override
public int hashCode() {
return valeur / 100;
}
}
public class TestHashMapBoucleInfinie {
/**
* Attention : cette application engendre généralement une boucle infinie
* qui consomme toute la CPU de la machine
*/
public static void main(final String[] args) {
final Map<MonElement, String> map = new HashMap<MonElement, String>(2, 0.2f);
System.out.println("debut");
for (int j = 0; j < 10; j++) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 100000; i++) {
map.put(new MonElement(i), "element " + i);
}
}
}, "Thread 0" + j);
t1.start();
}
for (int j = 0; j < 10; j++) {
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 10000; i++) {
map.get(i);
}
}
}, "Thread 1" + j);
t2.start();
}
}
}
Les Iterator de cette classe sont de type fail-fast : ils lèvent généralement une exception de type ConcurrentModificationException si une modification de la structure de la collection est réalisée (ajout ou suppression d'un élément) durant le parcours sauf si cette modification est faite grâce à l'Iterator.
Comme l'index est calculé à partir de la valeur de hachage de l'objet, l'ordre de parcours des clés n'est pas garanti. Il peut même changer au cours du temps si de nouveaux éléments sont ajoutés dans la collection.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.HashMap;
public class TestHashMapIterator {
public static void main(final String[] args) {
HashMap<String, String> map = new HashMap<String, String>(34);
map.put("1", "un");
map.put("2", "deux");
map.put("3", "trois");
map.put("4", "quatre");
map.put("5", "cinq");
for (String s : map.keySet()) {
System.out.print(s + " ");
}
}
}| Résultat : |
3 2 1 5 4Les performances des opérations get() et put() sont constantes sous réserve que la répartition des éléments dans les différents buckets grâce à leur valeur de hachage soit équitable.
La valeur de hachage doit être la plus discriminante possible pour permettre notamment de réduire les collisions (objets différents ayant la même valeur de hachage). Si tous les éléments de la collection possèdent la même valeur de hachage, alors ils sont tous dans le même bucket et les performances pour retrouver un élément sont de type O(n). Si la répartition des valeurs de hachage est équilibrée alors ces performances peuvent être de type O(log n).
Il existe plusieurs différences entre les classes Hashtable et HashMap bien qu'elles implémentent toutes les deux l'interface Map et ont un mode de fonctionnement similaire :
La classe LinkedHashMap, ajoutée à Java 1.4, est une implémentation de type Map qui utilise une liste doublement chaînée pour maintenir par défaut ses éléments dans leur ordre d'insertion.
Cette collection permet de garantir l'ordre de ses éléments sans avoir un subir un surcoût comme par exemple lors de l'utilisation d'une classe TreeSet.
La classe LinkedHashMap possède plusieurs constructeurs :
Constructeur |
Rôle |
LinkedHashMap() |
Créer une instance vide avec les propriétés par défaut : capacité initiale à 16 et facteur de charge à 0.75. |
LinkedHashMap(int initialCapacity) |
Créer une instance vide avec les propriétés : capacité initiale fournie et facteur de charge par défaut. |
LinkedHashMap(int initialCapacity, float loadFactor) |
Créer une instance vide avec les propriétés : capacité initiale et facteur de charge fournis |
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) |
Créer une instance vide avec les propriétés : capacité initiale, facteur de charge et l'ordre d'accès fournis |
LinkedHashMap(Map<? extends K,? extends V> m) |
Créer une instance remplie avec les éléments de la collection fournie en paramètres |
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.LinkedHashMap;
import java.util.Map;
public class TestLinkedHashMap {
private static void afficherMap(final LinkedHashMap<String, String> map) {
for (String s : map.keySet()) {
System.out.print(s + " ");
}
System.out.println("");
for (Map.Entry<String, String> s : map.entrySet()) {
System.out.print(s.getKey() + " ");
}
}
public static void main(final String[] args) {
LinkedHashMap<String, String> map = new LinkedHashMap<String, String>();
map.put(null, "");
for (int i = 10; i < 19; i++) {
map.put("" + i, "");
}
afficherMap(map);
}
}| Résultat : |
null 10 11 12 13 14 15 16 17 18
null 10 11 12 13 14 15 16 17 18La surcharge du constructeur qui attend en paramètre le booléen accessOrder permet de préciser l'ordre des éléments :
Cette fonctionnalité peut être intéressante pour créer un cache de type LRU.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.LinkedHashMap;
import java.util.Map;
public class TestLinkedHashMap {
private static void afficherMap(final LinkedHashMap<String, String> map) {
for (String s : map.keySet()) {
System.out.print(s + " ");
}
System.out.println("");
for (Map.Entry<String, String> s : map.entrySet()) {
System.out.print(s.getKey() + " ");
}
}
public static void main(final String[] args) {
LinkedHashMap<String, String> map = new LinkedHashMap<String, String>(16, 0.75f, true);
map.put(null, "");
for (int i = 10; i < 19; i++) {
map.put("" + i, "");
}
map.get("11");
map.get("14");
map.get("14");
map.get("11");
map.get("16");
map.get("11");
afficherMap(map);
}
}| Résultat : |
null 10 12 13 15 17 18 14 16 11
null 10
12 13 15 17 18 14 16 11La classe LinkedHashMap peut être utilisée pour créer une copy d'une autre collection de type Map qui permettra son parcours toujours de la même façon.
| Exemple : |
Map copie = new LinkedHashMap(m);L'ordre des éléments n'est pas modifié si un élément est de nouveau ajouté dans la collection alors qu'il est déjà présent dans cette dernière.
La méthode removeEldestEntry(Map.Entry<K,V>) peut être surchargée pour renvoyer un booléen qui précise si les éléments les plus anciens doivent être retirés de la collection.
La méthode containsValue(Object value) renvoie un booléen qui précise si une ou plusieurs de ses clés sont associées à la valeur fournie en paramètre.
Elle présente plusieurs caractéristiques :
La classe LinkedHashMap n'est pas synchronized, elle n'est donc pas thread-safe. Si plusieurs threads doivent ajouter ou supprimer des éléments dans la collection, il faut gérer manuellement la concurrence d'accès. Il est par exemple possible d'utiliser une instance de la collection retournée par la méthode synchronizedMap() de la classe Collections.
Map m = Collections.synchronizedMap(new LinkedHashMap());
Les Iterator de la classe LinkedHashMap sont de type fail-fast : les instances de type Iterator retournées par la méthode iterator() lèvent généralement une exception de type ConcurrentModificationException si une modification est effectuée dans la collection durant le parcours (exception faite des modifications réalisées avec la méthode remove() de l'Iterator).
Une LinkedHashMap, comme la classe HashMap, possède deux paramètres qui peuvent affecter ses performances lors de son utilisation : capacité initiale et facteur de charge. Cependant, contrairement à une HashMap, l'utilisation d' une capacité initiale largement surestimée est moins importante car le temps d'itération de cette collection n'est pas proportionnel à sa capacité.
Si la répartition dans les différents buckets réalisée grâce à la valeur de hachage de ses éléments est équitable, les méthodes add(), contains() et remove() sont exécutées avec des performances constantes. Le temps requis pour parcourir la collection est proportionnel à sa taille.
La classe TreeMap, ajoutée à Java 1.2, est une Map qui stocke des éléments de manière triée dans un arbre de type rouge-noir (Red-black tree).
Les éléments de la collection sont triés selon l'ordre naturel de leur clé (s'is implémentent l'interface Comparable) ou en utilisant une instance de type Comparator fournie au constructeur de la collection.
Elle implémente les interfaces Map et SortedMap. Elle implémente aussi l'interface NavigableMap depuis Java 6.
La classe TreeMap propose plusieurs constructeurs dont un qui permet de préciser l'objet Comparable pour définir l'ordre dans la collection :
Constructeur |
Rôle |
TreeMap() |
Constructeur par défaut qui crée une collection vide utilisant l'ordre naturel des clés des éléments |
TreeMap(Comparator<? super K> comparator) |
Créer une instance vide qui utilisera le Comparator fourni en paramètre pour déterminer l'ordre des éléments |
TreeMap(Map<? extends K,? extends V> m) |
Créer une instance contenant les éléments fournis en paramètres qui utilisera l'ordre naturel des clés des éléments |
TreeMap(SortedMap<K,? extends V> m) |
Créer une instance contenant les éléments fournis en paramètres |
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Map;
import java.util.TreeMap;
public class TestTreeMap {
public static void main(final String[] args) {
TreeMap<String, String> map = new TreeMap<String, String>();
map.put("cle3", "valeur3");
map.put("cle2", "valeur2");
map.put("cle1", "valeur1");
for (Map.Entry<String, String> element : map.entrySet()) {
System.out.println(element.getKey() + " : " + element.getValue());
}
}
}La classe TreeMap n'est pas synchronized. Pour obtenir une instance synchronized, il faut invoquer la méthode synchronizedSortedMap() de la classe Collections.
SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));
Toutes les instances de type Map.Entry retournées par les méthodes d'une TreeMap représente une vue des éléments de l'instance au moment où elles sont créées. La méthode setValue() de la classe Map.Entry lève une exception de type UnsupportedOperationException si elle est invoquée.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Map;
import java.util.TreeMap;
public class TestTreeMap {
public static void main(final String[] args) {
TreeMap<String, String> map = new TreeMap<String, String>();
map.put("cle1", "valeur1");
map.put("cle2", "valeur2");
map.put("cle3", "valeur3");
Map.Entry<String, String> dernier = map.lastEntry();
dernier.setValue("valeur3 modifie");
for (Map.Entry<String, String> element : map.entrySet()) {
System.out.println(element.getKey() + " : " + element.getValue());
}
}
}| Résultat : |
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.AbstractMap$SimpleImmutableEntry.setValue(Unknown Source)
at com.jmdoudoux.test.collections.TestTreeMap.main(TestTreeMap.java:15)Pour changer la valeur associer à une clé, il faut utiliser la méthode put().
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Map;
import java.util.TreeMap;
public class TestTreeMap {
public static void main(final String[] args) {
TreeMap<String, String> map = new TreeMap<String, String>();
map.put("cle1", "valeur1");
map.put("cle2", "valeur2");
map.put("cle3", "valeur3");
map.put("cle3", "valeur3 modifie");
for (Map.Entry<String, String> element : map.entrySet()) {
System.out.println(element.getKey() + " : " + element.getValue());
}
}
} | Résultat : |
cle1 : valeur1
cle2 : valeur2
cle3 : valeur3 modifieLes opérations basiques get(), put() et remove() s'exécutent dans un délai de type O(log n).
Les Iterator sont de type fail-fast.
La classe WeakHashMap, ajoutée dans Java 1.2, est une implémentation d'une collection de type Map dont les clés sont stockées avec des références faibles (WeakReference). La classe WeakHashMap retire automatiquement les éléments dont la clé a été récupérée par le ramasse-miettes.
Elle hérite de la classe AbstractMap et implémente l'interface Map<K,V>.
Cette collection présente plusieurs caractéristiques :
Une clé n'est pas stockée directement dans une WeakHashMap : c'est une référence faible sur l'instance qui est stockée. Un objet qui encapsule une valeur est stocké dans la WeakHashMap avec une référence forte. Il ne doit pas faire référence à sa clé sinon celle-ci ne sera pas récupérée par le ramasse-miettes en cas de besoin.
Si l'objet utilisé comme clé n'est plus référencé par d'autres objets, le ramasse-miettes va le récupérer et l'élément sera retiré de la collection.
Il faut être sûr de n'utiliser comme clés que des objets qui puissent être récupérés par le ramasse-miettes : par exemple, il ne faut surtout pas utiliser des chaînes de caractères dont la valeur est codée en dur.
Seules les clés sont stockées avec des références faibles : la valeur associée à l'élément est stockée sous la forme d'une référence forte.
La classe WeakHashMap possède quatre constructeurs :
Constructeur |
Rôle |
WeakHashMap() |
Créer une instance vide de la collection dont la capacité initiale est de 16 et le facteur de charge est 0.75 |
WeakHashMap(int initialCapacity) |
Créer une instance vide de la collection dont la capacité initiale est fournie en paramètre et le facteur de charge est 0.75 |
WeakHashMap(int initialCapacity, float loadFactor) |
Créer une instance vide de la collection dont la capacité initiale et le facteur de charge sont fournies en paramètres |
WeakHashMap(Map map) |
Créer une instance remplie avec les éléments de la collection fournie en paramètre |
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Map;
import java.util.WeakHashMap;
public class TestWeakHashMap {
public static void main(final String args[]) {
String maCle = new String("1");
Map<String, String> map = new WeakHashMap<String, String>();
map.put(maCle, "Element1");
map.put(new String("2"), "Element2");
map.put(new String("3"), "Element3");
System.out.println("map.size()=" + map.size());
System.out.println("Demande d'execution du ramasse-miettes");
System.gc();
try {
Thread.sleep(1000);
} catch (InterruptedException ignored) {
}
System.out.println("map.size()=" + map.size());
maCle = null;
System.out.println("Demande d'execution du ramasse-miettes");
System.gc();
try {
Thread.sleep(1000);
} catch (InterruptedException ignored) {
}
System.out.println("map.size()=" + map.size());
}
}| Résultat : |
map.size()=3
Demande d'execution du ramasse-miettes
map.size()=1
Demande d'execution du ramasse-miettes
map.size()=0 Le fonctionnement d'un objet de type WeakHashMap repose en partie sur l'activité du ramasse-miettes qui peut détruire des objets utilisés comme clés : ces objets seront alors supprimés de la collection. Ainsi le contenu de la collection peut être modifié alors qu'aucune opération n'est explicitement invoquée : ce comportement est spécifique pour une collection de type WeakHashMap.
Il est préférable que l'implémentation de la méthode equals() des objets utilisés comme clés utilise un test d'égalité sur l'identité des objets avec l'opérateur ==. Ceci garantit qu'un objet ne puisse pas être recréé et être égal à l'instance détruite par le ramasse-miettes.
La classe WeakHashMap n'est pas synchronized. Pour obtenir une instance synchronized, il faut invoquer la méthode synchronizedMap() de la classe Collections.
WeakHashMap m = Collections.synchronizedMap(new WeakHashMap(...));
Les performances de cette collection sont similaires à celles de la classe HashMap.
Les Iterator de la classe WeakHashMap sont de type fail-fast.
Il est tentant d'utiliser la classe WeakHashMap comme implémentation d'un cache.
Il est préférable d'utiliser la classe WeakHashMap pour associer des données à un objet : dans ce cas, la clé est l'objet et la valeur contient les informations associées. La classe WeakHashMap va garantir qu'il n'y aura pas de fuites de mémoire liées à l'oubli de suppression de l'élément dans la collection lorsque l'objet n'est plus utilisé.
Ceci peut par exemple être pratique si l'objet est accédé par plusieurs threads. Une WeakHashMap est bien adaptée lorsqu'il n'est pas facile de connaitre le moment où les threads n'auront plus besoin des informations et pourront retirer l'objet les contenant de la collection.
La classe java.util.EnumMap<K extends Enum<K>, V>, ajoutée à Java 5, est une implémentation de l'interface Map qui ne peut utiliser comme clés que les éléments d'une énumérations. Les traitements de la classe sont optimisés en fonction de cette particularité.
Elle hérite de la classe AbstractMap(K, V)
Elle présente plusieurs caractéristiques :
En interne, le stockage des éléments de la collection se fait dans un tableau.
Les Iterator obtenus par les méthodes keySet(), entrySet() et values() sont ordonnés dans l'ordre de définition des éléments de l'énumération. Ces itérateurs ne lèvent jamais d'exception de type ConcurrentModificationException.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.EnumMap;
import java.util.Iterator;
public class TestEnumMap {
public enum ETAT {
NOUVEAU, EN_COURS, EN_PAUSE, INDETERMINE, TERMINE;
}
public static void main(final String args[]) {
EnumMap<ETAT, String> etatLibelle = new EnumMap<ETAT, String>(ETAT.class);
etatLibelle.put(ETAT.NOUVEAU, "Nouvelle tache");
etatLibelle.put(ETAT.EN_COURS, "Tache en cours d'exécution");
etatLibelle.put(ETAT.EN_PAUSE, "Execution de la tache en pause");
etatLibelle.put(ETAT.TERMINE, "Tache terminée");
System.out.println("etatLibelle : " + etatLibelle);
System.out.println("EnumMap cle : " + ETAT.NOUVEAU + ", valeur : "
+ etatLibelle.get(ETAT.NOUVEAU));
Iterator<ETAT> enumKeySet = etatLibelle.keySet().iterator();
while (enumKeySet.hasNext()) {
ETAT currentState = enumKeySet.next();
System.out.println("cle : " + currentState + ", valeur : "
+ etatLibelle.get(currentState));
}
if (etatLibelle.containsKey(ETAT.NOUVEAU)) {
System.out.println("etatLibelle contient la cle : " + ETAT.NOUVEAU);
}
if (!etatLibelle.containsKey(ETAT.INDETERMINE)) {
System.out.println("etatLibelle ne contient pas la cle : "
+ ETAT.INDETERMINE);
}
}
}| Résultat : |
etatLibelle : {NOUVEAU=Nouvelle tache, EN_COURS=Tache en cours
d'exécution, EN_PAUSE=Execution de la tache en pause, TERMINE=Tache terminée}
EnumMap cle : NOUVEAU, valeur : Nouvelle tache
cle : NOUVEAU, valeur : Nouvelle tache
cle : EN_COURS, valeur : Tache en cours d'exécution
cle : EN_PAUSE, valeur : Execution de la tache en pause
cle : TERMINE, valeur : Tache terminée
etatLibelle contient la cle : NOUVEAU
etatLibelle ne contient pas la cle : INDETERMINELa classe EnumMap n'est pas synchronized. Si plusieurs threads doivent accéder à la collection et qu'au moins l'un d'entre-eux modifie la collection, il faut utiliser une instance de la collection retournée par la méthode synchronizedMap() de la classe Collections.
Map<MonEnum, String> map = Collections.synchronizedMap(new EnumMap<MonEnum, String>());
Les opérations de base s'exécutent en temps constant. Les performances des opérations d'une EnumMap sont généralement meilleures que leur équivalent de la classe HashMap avec les mêmes éléments.
Il existe plusieurs différences entre les classes EnumMap et HashMap :
La classe java.util.IdentityHashMap<K extends Enum<K>, V>, ajoutée à Java 1.4, est une implémentation de l'interface Map qui utilise un test d'égalité sur les références (habituellement les implémentations de l'interface Map utilise l'égalité des objets). Deux clés cle1 et cle2 sont donc égales si cle1==cle2.
De ce fait, la classe IdentityHashMap est une implémentation particulière de l'interface Map dont elle ne respecte pas le contrat qui précise que le test d'égalité sur des objets doit se faire en utilisant la méthode equals(). Ce n'est donc pas une implémentation à usage générale mais son utilisation est limitée à quelques cas bien particuliers comme par exemple conserver une trace des objets utilisés lors d'opérations de sérialisation ou de clonage.
Elle hérite de la classe AbstractMap(K, V) et implémente toutes les méthodes optionnelles de l'interface Map.
Elle possède plusieurs caractéristiques :
La classe IdentityHashMap a une propriété qui peut agir sur ses performances : le nombre maximum d'éléments prévus dans la collection. Cette propriété est utilisée pour définir le nombre de buckets. Si la taille de la collection devient insuffisante pour contenir les éléments, le stockage interne de la collection est agrandi et la méthode rehash() est invoquée. Cet agrandissement est coûteux.
La classe IdentityHashMap possède trois constructeurs :
Constructeur |
Rôle |
IdentityHashMap() |
Créer une instance vide de la collection avec une taille maximale prévue par défaut de 21 |
IdentityHashMap(int expectedMaxSize) |
Créer une instance vide de la collection avec une taille maximale prévue fournie en paramètre |
IdentityHashMap(Map map) |
Créer une instance qui contient les éléments fournis en paramètres |
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.IdentityHashMap;
public class TestIdentityHashMap {
public static void main(final String[] args) {
IdentityHashMap<String, String> identityMap = new IdentityHashMap<String, String>();
identityMap.put("1", "Element 1");
identityMap.put(new String("1"), "Element 1_2");
System.out.println("identityHashMap.size() = " + identityMap.size());
System.out.println("identityHashMap = " + identityMap);
identityMap.put("1", "Element 1 modifie");
System.out.println("identityHashMap.size() = " + identityMap.size());
System.out.println("identityHashMap = " + identityMap);
}
}| Résultat : |
identityHashMap.size() = 2
identityHashMap = {1=Element 1_2, 1=Element 1}
identityHashMap.size() = 2
identityHashMap = {1=Element 1_2, 1=Element 1 modifie}La classe IdentityHashMap n'est pas synchronized. Si plusieurs threads doivent accéder à la collection et qu'au moins un d'entre-eux modifie la collection, il faut utiliser une instance de la collection retournée par la méthode synchronizedMap() de la classe Collections.
Map map = Collections.synchronizedMap(new IdentityHashMap());
Les Iterator de la classe IdentityHashMap sont de type fail-fast : les instances de type Iterator retournées par la méthode iterator() lèvent généralement une exception de type ConcurrentModificationException si une modification est effectuée dans la collection durant le parcours (exception faite des modifications réalisées avec la méthode remove() de l'Iterator).
Il existe plusieurs différences entre les classes IdentityHashMap et HashMap :
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.HashMap;
import java.util.IdentityHashMap;
import java.util.Map;
public class TestIdentityMapHashMap {
public static void main(final String[] args) {
Map<String, Integer> identityMap = new IdentityHashMap<String, Integer>();
Map<String, Integer> hashMap = new HashMap<String, Integer>();
identityMap.put("1", 1);
identityMap.put(new String("1"), 2);
identityMap.put("1", 3);
hashMap.put("1", 1);
hashMap.put(new String("1"), 2);
hashMap.put("1", 3);
System.out.println("identityMap.keySet().size() = "
+ identityMap.keySet().size());
System.out.println("hashMap.keySet().size() = "
+ hashMap.keySet().size());
}
}| Résultat : |
identityMap.keySet().size() = 2
hashMap.keySet().size() = 1
L'interface NavigableMap, ajoutée dans Java 6, hérite de l'interface SortedMap. Elle définit des fonctionnalités qui permettent le parcours de la collection dans l'ordre ascendant ou descendant grâce à plusieurs méthodes.
L'interface définit plusieurs méthodes qui peuvent être regroupées selon leur rôle :
Méthode |
Rôle |
Map.Entry<K,V> ceilingEntry(K key) |
Renvoyer la paire clé/valeur correspondant à la plus petite clé supérieure ou égale à celle fournie en paramètre. Elle renvoie null si une telle clé n'est pas trouvée |
K ceilingKey(K key) |
Renvoyer la plus petite clé supérieure ou égale à celle fournie en paramètre. Elle renvoie null si une telle clé n'est pas trouvée |
NavigableSet<K> descendingKeySet() |
Renvoyer une collection qui permette le parcours de la collection dans le sens inverse de l'ordre des clés |
NavigableMap<K,V> descendingMap() |
Renvoyer une collection de paires clé/valeur permettant le parcours de la collection en sens inverse |
Map.Entry<K,V> firstEntry() |
Renvoyer la paire clé/valeur correspondant à la plus petite clé de la collection. Elle renvoie null si la collection est vide |
Map.Entry<K,V> floorEntry(K key) |
Renvoyer la paire clé/valeur correspondant à la plus grande clé inférieure ou égale à celle fournie en paramètre. Elle renvoie null si une telle clé n'est pas trouvée |
K floorKey(K key) |
Renvoyer la plus grande clé inférieure ou égale à celle fournie en paramètre. Elle renvoie null si une telle clé n'est pas trouvée |
SortedMap<K,V> headMap(K toKey) |
Renvoyer une collection qui est un sous-ensemble composé des paires clé/valeur dont la clé est strictement inférieure à celle fournie en paramètre |
NavigableMap<K,V> headMap(K toKey, boolean inclusive) |
Renvoyer une collection qui est un sous-ensemble composé des paires clé/valeur dont la clé est inférieure (ou égale si le paramètre inclusive vaut true) à celle fournie en paramètre |
Map.Entry<K,V> higherEntry(K key) |
Renvoyer la paire clé/valeur correspondant à la plus petite clé supérieure ou égale à celle fournie en paramètre. Elle renvoie null si une telle clé n'est pas trouvée |
K higherKey(K key) |
Renvoyer la plus petite clé supérieure ou égale à celle fournie en paramètre. Elle renvoie null si une telle clé n'est pas trouvée |
Map.Entry<K,V> lastEntry() |
Renvoyer la paire clé/valeur correspondant à la plus grande clé de la collection. Elle renvoie null si la collection est vide |
Map.Entry<K,V> lowerEntry(K key) |
Renvoyer la paire clé/valeur correspondant à la plus grande clé strictement inférieure à celle fournie en paramètre. Elle renvoie null si une telle clé n'est pas trouvée |
K lowerKey(K key) |
Renvoyer la plus petite clé de la collection strictement inférieure à celle fournie en paramètre. Renvoie null si aucune clé n'est trouvée |
NavigableSet<K> navigableKeySet() |
Renvoyer une collection de type NavigableSet contenant les clés de la collection |
Map.Entry<K,V> pollFirstEntry() |
Retirer de la collection et renvoyer la paire clé/valeur dont la clé est la plus petite. Elle renvoie null si la collection est vide |
Map.Entry<K,V> pollLastEntry() |
Retirer de la collection et renvoyer la paire clé/valeur dont la clé est la plus grande. Elle renvoie null si la collection est vide |
NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) |
Renvoyer une collection, qui soit un sous-ensemble de la collection, contenant les paires clé/valeur dont la valeur des clés est comprise entre les valeurs de fromKey et toKey. Les paramètres fromInclusive et toInclusive précisent si ces valeurs doivent être incluses |
SortedMap<K,V> subMap(K fromKey, K toKey) |
Renvoyer un sous-ensemble de la collection qui va contenir les éléments dont les clés sont comprises entre fromKey incluse et toKey exclue |
SortedMap<K,V> tailMap(K fromKey) |
Renvoyer un sous-ensemble de la collection qui va contenir les éléments dont les clés sont plus grandes ou égales à fromKey |
NavigableMap<K,V> tailMap(K fromKey, boolean inclusive) |
Renvoyer un sous-ensemble de la collection qui va contenir les éléments dont les clés sont plus grandes que fromKey. L'élément dont la clé est égale est aussi inclus si le paramètre inclusive vaut true |
L'API Collections propose plusieurs implémentations de l'interface NavigableMap : ConcurrentSkipListMap et TreeMap
L'interface java.util.concurrent.ConcurrentNavigableMap, ajoutée à Java 1.6, définit les fonctionnalités d'une NavigableMap avec une gestion des accès concurrents pour elle-même et pour ses sous Map.
L'interface NavigableMap hérite des interfaces ConcurrentMap et NavigableMap.
L'API Collections ne propose qu'une seule implémentation de cette interface : la classe ConcurrentSkipListMap.
La classe ConcurrentSkipListMap, ajoutée à Java 6, est une implémentation de l'interface ConcurrentNavigableMap en utilisant un algorithme de type SkipList. Les fonctionnalités offertes par la classe ConcurrentSkipListMap peuvent être vues comme une fusion des fonctionnalités des classes ConcurrentHashMap et TreeMap.
Les éléments de cette collection sont triés selon leur ordre naturel en implémentant l'interface Comparable ou en utilisant une instance de type Compator fournie en paramètre du constructeur de la collection.
La classe ConcurrentSkipListMap présente plusieurs caractéristiques :
La classe java.util.ConcurrentSkipMap hérite de la classe abstraite AbstractMap et implémente l'interface ConcurrentNavigableMap. Elle implémente toutes les méthodes optionnelles des interfaces Map et Iterator.
La classe propose plusieurs constructeurs :
Constructeur |
Rôle |
ConcurrentSkipListMap() |
Créer une instance vide dont les éléments seront triés selon leur ordre naturel |
ConcurrentSkipListMap(Comparator<? super K> comparator) |
Créer une instance vide dont les éléments seront triés selon leur l'ordre déterminé par l'instance fournie en paramètre |
ConcurrentSkipListMap(Map<? extends K,? extends V> m) |
Créer une instance qui va contenir les éléments de la collection fournie en paramètre triés selon leur ordre naturel |
ConcurrentSkipListMap(SortedMap<K,? extends V> m) |
Créer une instance qui va contenir les éléments de la collection fournie en paramètre triés selon leur ordre dans la collection |
Les opérations de la classe ConcurrentSkipListMap sont thread-safe.
Les Iterator obtenus de la collection reflètent la liste des éléments à un instant donné, généralement le moment de la création de l'instance de type Iterator. Le parcours ne lève jamais d'exception de type ConcurrentModificationException. Le parcours ascendant est plus rapide que le parcours descendant.
Les opérations groupées proposées par les méthodes clear(), equals() et putAll() ne garantissent pas que leurs exécutions seront atomiques.
Toutes les instances de type Map.Entry retournées par les méthodes de classe ConcurrentSkipListMap sont une représentation des données au moment où l'instance est créée. Il n'est pas possible d'utiliser leur méthode setValue(). Pour modifier une valeur, il faut invoquer une des méthodes put(), putIfAbsent() ou replace().
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Iterator;
import java.util.concurrent.ConcurrentSkipListMap;
public class TestConcurrentSkipListMap {
public static void main(final String[] args) {
final ConcurrentSkipListMap<MaTache, String> map =
new ConcurrentSkipListMap<MaTache, String>();
System.out.println("debut");
final Thread modificateur = new Thread(new Runnable() {
@Override
public void run() {
MaTache[] MesTaches = new MaTache[5];
for (int i = 1; i <= 5; i++) {
MesTaches[i - 1] = new MaTache(6 - i, "Tache " + i);
}
for (int j = 1; j <= 100; j++) {
if (j % 2 == 0) {
for (int i = 1; i <= 5; i++) {
MaTache element = MesTaches[i - 1];
System.out.println("insertion element " + element);
map.putIfAbsent(element, "description " + i);
}
System.out.println("taille de la queue=" + map.size());
} else {
for (int i = 1; i <= 5; i++) {
MaTache element = MesTaches[i - 1];
System.out.println("retirer element " + element);
map.remove(element);
}
}
}
}
}, "Modificateur");
modificateur.start();
Thread iterateur = new Thread(new Runnable() {
@Override
public void run() {
int i = 0;
while (modificateur.isAlive()) {
Iterator<MaTache> iterator = null;
if (i % 2 == 0) {
iterator = map.navigableKeySet().iterator();
} else {
iterator = map.descendingKeySet().iterator();
}
StringBuilder contenu = new StringBuilder("[");
while (iterator.hasNext()) {
contenu.append(iterator.next().getDescription());
if (iterator.hasNext()) {
contenu.append(", ");
}
}
contenu.append("]");
System.out.println("Contenu=" + contenu);
i++;
}
}
}, "iterateur");
iterateur.start();
try {
modificateur.join();
iterateur.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("fin");
}
}Les performances des opérations basiques se situent en moyenne dans un temps dont l'expression est en log(n).
Le temps d'exécution de la méthode size() est variable car le nombre d'éléments de la collection doit être recalculé en la reparcourant.
La classe ConcurrentSkipListMap offre une meilleure scalabilité face aux accès concurrents que la classe ConcurrentHashMap mais en contrepartie les temps d'accès aux éléments ne sont pas constants. Cette contrepartie est liée au fait que la collection soit une SortedMap.
L'interface ConcurrentMap, ajoutée à Java 1.5, définit les méthodes d'une collection qui est capable de gérer les accès concurrents lors des opérations de modifications de ces éléments.
Une collection de type Map est fréquemment utilisée dans un contexte multithread comme par exemple pour implémenter un cache d'objets simple.
Utiliser une instance synchronized de type Map retournée par la méthode synchronizedMap() de la classe Collections ne permet pas d'obtenir de bonnes performances en cas de nombreux accès concurrents car c'est l'instance de la collection elle-même sur laquelle se fait le verrou lors de l'invocation d'une méthode.
De plus, une Map synchronized ne garantit pas non plus l'atomicité de ses opérations qui nécessitent l'invocation de plusieurs méthodes : par exemple, pour ajouter un élément dans la collection, il est nécessaire de vérifier au préalable qu'elle ne contient pas déjà la clé en utilisant la méthode containsKey() ou get(). Comme le verrou est posé durant l'invocation de chaque méthode, il est possible que deux threads qui tentent d'ajouter un élément entraînent une race condition.
Par exemple, le premier thread obtient le verrou en invoquant la méthode containsKey() qui renvoie false, le second obtient à son tour le verrou en invoquant la méthode containsKey() qui renvoie false, le premier thread obtient le verrou en invoquant la méthode put() pour ajouter l'élément, le premier thread obtient le verrou en invoquant la méthode put() pour écraser l'élément ajouté par le premier thread.
Ce type de problématique est difficile à détecter et à reproduire : l'interface ConcurrentMap, ajoutée dans Java 5, hérite de l'interface Map. Elle définit quatre méthodes dont le comportement est atomique
Méthode |
Rôle |
V putIfAbsent(K key, V value) |
Ajouter un élément dans la collection de manière atomique uniquement si la clé n'est pas déjà présente dans la collection. Renvoie null si l'élément est ajouté sinon renvoie la valeur associée à la clé (qui peut être null) |
boolean remove(Object key, Object value) |
Retirer un élément de la collection de manière atomique si la clé est présente dans la collection et est associée à la valeur fournie en paramètre. Renvoie un booléen qui indique le succès de l'opération |
V replace(K key, V value) |
Modifier la valeur associée à la clé de manière atomique uniquement si la clé est présente dans la collection. Renvoie null si l'élément est modifié sinon renvoie la valeur associée à la clé (qui peut être null) |
boolean replace(K key, V oldValue, V newValue) |
Modifier un élément de la collection de manière atomique si la clé est présente dans la collection et est associée à la valeur fournie au paramètre oldValue. Renvoie un booléen qui indique le succès de l'opération |
L'API Collections propose deux implémentations de l'interface ConcurrentMap : ConcurrentHashMap et ConcurrentSkipListMap.
La classe ConcurrentHashMap, ajoutée à Java 1.5, implémente l'interface ConcurrentMap qui utilise une HashMap en garantissant les accès concurrents et les performances. Son but est de remplacer la classe Hashtable car elle est similaire à celle-ci avec une meilleure gestion des accès concurrents.
La classe ConcurrentHashMap implémente toutes les méthodes optionnelles des interfaces Map et Iterator.
Elle présente plusieurs caractéristiques :
Les accès pour retrouver un élément ne sont pas bloquants. Les mises à jour de la collection ne bloquent pas l'intégralité de la HashMap utilisée en interne car elle utilise des segments. Ce paramètre influe sur les performances lors des mises à jour concurrentes : il correspond au nombre de segments dans lesquels la collection va être découpée. Chaque thread qui effectue une mise à jour le fait dans son propre segment pour éviter la contention.
Idéalement, la valeur du paramètre concurrencyLevel doit être au moins égale au nombre de threads qui peuvent mettre à jour la collection de manière concurrente. Si la valeur est trop petite, il y a un risque d'avoir de la contention. Si la valeur est vraiment trop grande, il y a une consommation excessive de la mémoire requise. Par exemple, la valeur 1 est utilisable si un seul thread peut mettre à jour la collection et que les autres threads accèdent à la collection en lecture seulement.
Un des constructeurs attend un paramètre nommé concurrencyLevel qui correspond à ce nombre de segments. La valeur par défaut du paramètre concurrencyLevel est 16.
Deux autres paramètres influent sur les performances de la collection :
Plusieurs surcharges du constructeur permettent de préciser ces paramètres afin d'optimiser les performances.
Constructeur |
Rôle |
ConcurrentHashMap() |
Créer une collection vide avec les paramètres par défaut |
ConcurrentHashMap(int initialCapacity) |
Créer une collection vide avec la capacité initiale fournie en paramètre |
ConcurrentHashMap(int initialCapacity, float loadFactor) |
Créer une collection vide avec la capacité initiale et le facteur de charge fournis en paramètres |
ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) |
Créer une collection vide avec la capacité initiale, le facteur de charge et le niveau de concurrence fournis en paramètres |
ConcurrentHashMap(Map<? extends K,? extends V> m) |
Créer une collection initialisée avec la collection de type Map fournie en paramètre |
Généralement les opérations qui permettent d'obtenir un élément de la collection ne sont pas bloquantes et peuvent être réalisées en concurrence avec des opérations de mises à jour : la valeur retournée est alors le résultat de la dernière opération unitaire de mise à jour entièrement terminée. Si les opérations de mises à jour concernent plusieurs éléments (clear() ou putAll() par exemple), alors la ou les valeurs retournées peuvent ne contenir que tout ou partie des mises à jour en cours de réalisation.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Map;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
public class TestConcurrentHashMap {
private final ConcurrentMap<String, AtomicInteger> cache =
new ConcurrentHashMap<String, AtomicInteger>(3, 0.75f, NB_THREADS);
private final CyclicBarrier barriere =
new CyclicBarrier(NB_THREADS);
private static final int NB_THREADS = 50;
public static void main(final String[] args) {
System.out.println("debut");
TestConcurrentHashMap tchm = new TestConcurrentHashMap();
tchm.exec();
System.out.println("fin");
}
private void ajouter(final String cle) {
AtomicInteger value;
value = cache.putIfAbsent(cle, new AtomicInteger(1));
if (value != null) {
value.incrementAndGet();
}
}
private void exec() {
final ExecutorService executor = Executors.newFixedThreadPool(NB_THREADS);
try {
for (int i = 0; i < NB_THREADS; i++) {
executor.submit(new Runnable() {
@Override
public void run() {
try {
barriere.await();
for (int i = 0; i < 1000000; i++) {
ajouter("chaine1");
ajouter("chaine2");
ajouter("chaine3");
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
});
}
} finally {
executor.shutdown();
}
while (!executor.isTerminated()) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
for (Map.Entry<String, AtomicInteger> entry : cache.entrySet()) {
System.out.println("[" + entry.getKey() + ", " +
entry.getValue() + ']');
}
}
}| Résultat : |
debut
[chaine1, 50000000]
[chaine3, 50000000]
[chaine2, 50000000]
finLa classe ConcurrentHashMap est optimisée pour les opérations courantes mais certaines opérations peuvent être coûteuses : c'est notamment le cas de la méthode size() qui pose un verrou sur tous les segments pour calculer le nombre d'éléments que chacun contient.
Les parcours de la collection avec un Iterator reflètent l'état de la collection à un instant donné ou au moment de la création de l'Iterator. Les Iterator créés par cette collection ne lève jamais d'exception de type ConcurrentModificationException si une modification de structure est réalisée dans la collection durant son parcours. Ces Iterator ne sont toutefois pas prévus pour être utilisés par plusieurs threads.
Le JDK contient plusieurs implémentations de l'interface Map pour un usage spécifique :
Le JDK contient plusieurs implémentations de l'interface Map pour un usage généraliste qui peuvent selon les besoins :
Ordre des clés |
Pas d'accès concurrent |
Gestion des accès concurrents |
Aucun |
HashMap |
Hashtable ConcurrentHashMap |
Trié |
TreeMap |
ConcurrentSkipListMap |
Fixe |
LinkedHashMap |
Pour une Map triée, il faut utiliser la classe TreeMap s'il n'y a pas d'utilisation concurrente sinon il faut utiliser la classe ConcurrentSkipListMap.
Trois classes sont utilisables dans un contexte généraliste et non concurrentiel. Le critère de choix est essentiellement l'ordre de tri des éléments que la collection doit utiliser :
Si la collection peut être utilisée de manière concurrente, plusieurs classes peuvent être mises en oeuvre :
Le tableau ci-dessous compare les performances relatives de trois opérations permettant d'obtenir des données de plusieurs instances de type Map.
|
get() |
containsKey() |
next() |
HashMap |
O(1) |
O(1) |
O(h/n) |
LinkedHashMap |
O(1) |
O(1) |
O(1) |
IdentityHashMap |
O(1) |
O(1) |
O(h/n) |
EnumMap |
O(1) |
O(1) |
O(1) |
TreeMap |
O(log n) |
O(log n) |
O(log n) |
ConcurrentHashMap |
O(1) |
O(1) |
O(h/n) |
ConcurrentSkipListMap |
O(log n) |
O(log n) |
O(1) |
Dans le tableau ci-dessus, h représente la capacité de la collection et n le nombre d'éléments.
Une Queue est une collection qui stocke des éléments dans un certain ordre avant d'être consommés pour être traités.
La plupart des implémentations proposées par le framework Collection utilise l'ordre FIFO (First In, First Out) mais l'ordre peut être différent.
La majorité des implémentations sont dans le package java.util.concurrent
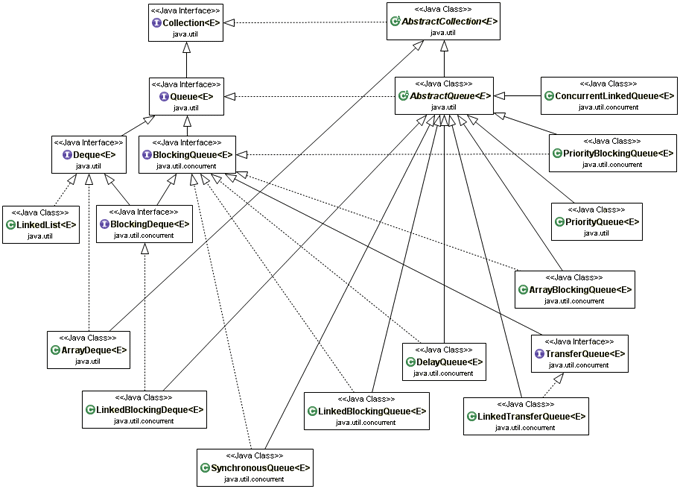
L'interface Queue, ajoutée dans Java 5, définit les fonctionnalités pour une file d'objets (une collection qui permet de stocker des éléments avant leur traitement).
Une file propose trois opérations standard :
L'interface Queue propose des méthodes pour deux comportements différents en cas d'échec de ses opérations par exemple si la collection est vide ou pleine : le renvoie d'un booléen qui indique le succès de l'opération ou la levée d'une exception.
L'interface Queue définit plusieurs méthodes :
Méthode |
Rôle |
E element() |
Consulter le premier élément disponible sans le retirer de la collection. Cette méthode lève une exception si la collection est vide |
boolean offer(E o) |
Ajouter l'élément dans la collection. Le booléen indique si l'ajout a réussi ou non |
E peek() |
Consulter le premier élément disponible sans le retirer de la collection. Cette méthode renvoie null si la collection est vide |
E poll() |
Obtenir le premier élément et le retirer de la file. Cette méthode renvoie null si la collection est vide |
E remove() |
Obtenir le premier élément et le retirer de la file. Cette méthode lève une exception si la collection est vide |
Les méthodes pour ajouter un élément à la fin de la collection ou obtenir l'élément au début de la collection peuvent être classées en deux catégories selon qu'elles lèvent une exception ou retournent une valeur spéciale en cas d'échec :
Lever une exception |
Retourner une valeur spéciale |
|
Ajouter un élément à la fin |
add() |
offer() |
Obtenir et retirer le premier élément |
remove() |
poll() |
Obtenir sans le retirer le premier élément |
element() |
peek() |
La méthode add() est héritée de l'interface collection : elle renvoie un booléen qui ne peut valoir false que si l'ajout est impossible car l'élément est déjà présent dans la collection. Dans les autres cas d'erreurs, la méthode add() doit lever une exception. C'est la différence avec la méthode offer() qui ne lève pas d'exceptions.
Il n'y a que la classe LinkedList qui permet l'ajout d'éléments null dans les implémentations de l'interface Queue proposées par l'API Collections.
La classe abstraite AbstractQueue, ajoutée à Java 5.0, est la classe mère de la plupart des collections de type Queue. Ces collections ne doivent pas accepter de valeur null.
Elle implémente les interfaces Collection, Iterable et Queue.
L'API Collections propose plusieurs classes filles : ArrayBlockingQueue, ConcurrentLinkedQueue, DelayQueue, LinkedBlockingDeque, LinkedBlockingQueue, PriorityBlockingQueue, PriorityQueue et SynchronousQueue.
L'interface TransferQueue, ajoutée dans Java 7, définit les fonctionnalités d'une collection dans laquelle les producteurs peuvent attendre qu'un consommateur reçoive un élément avant de pouvoir ajouter un nouvel élément dans la collection.
L'interface TransferQueue hérite de l'interface BlockingQueue.
Méthode |
Rôle |
int getWaitingConsumerCount() |
Retourner une estimation du nombre de consommateurs qui attendent de recevoir un élément (en ayant invoqué les méthodes take() ou poll() avec un timeout) |
boolean hasWaitingConsumer() |
Retourner une booléen si au moins un consommateur attend de recevoir un élément (en ayant invoqué les méthodes take() ou poll() avec un timeout) |
void transfer(E e) |
Transférer un élément à un consommateur de manière bloquante (attente jusqu'à ce que l'élément soit consommé) |
boolean tryTransfer(E e) |
Transférer un élément à un consommateur : cet élément doit être immédiatement consommé si possible. Renvoie un booléen qui précise si l'élément est consommé |
boolean tryTransfer(E e, long timeout, TimeUnit unit) |
Transférer un élément à un consommateur : cet élément doit être consommé si possible dans le timeout précisé en paramètre. Renvoie un booléen qui précise si l'élément est consommé |
Lors de l'utilisation d'une collection de type TransfertQueue, il est possible de choisir si l'ajout d'un nouvel élément doit être bloquant en utilisant la méthode transfert() ou non bloquant en utilisant la méthode put().
Si des éléments sont déjà dans la collection l'invocation de la méthode transfer() sera bloquante jusqu'à ce que tous les éléments aient été consommés.
Java 7 ne propose qu'une seule implémentation de cette interface : LinkedTransfertQueue.
La classe LinkedTransferQueue, ajoutée dans Java 7, est une implémentation d'une collection de type TransferQueue qui utilise en interne une LinkedList.
Elle présente plusieurs caractéristiques :
Elle hérite de la classe AbstractQueue et implémente l'interface TransferQueue. Elle implémente toutes les méthodes optionnelles des interfaces Collection et Iterator.
La classe LinkedTransferQueue possède deux constructeurs :
Constructeur |
Rôle |
LinkedTransferQueue() |
Créer une collection vide |
LinkedTransferQueue(Collection<? Extends E> c) |
Créer une collection qui va contenir les éléments de la collection fournie en paramètre |
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.concurrent.LinkedTransferQueue;
public class TestLinkedTransferQueue {
private static final int NB_TACHES = 5;
public static void main(final String[] args) {
final LinkedTransferQueue<MaTache> queue = new
LinkedTransferQueue<MaTache>();
final Thread producteur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= NB_TACHES; i++) {
MaTache maTache = new MaTache(NB_TACHES - i, "Tache " + i);
try {
System.out.println("Ajout de " + maTache);
queue.transfer(maTache);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "Producteur");
Thread consommateur = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
MaTache maTache = null;
try {
maTache = queue.take();
System.out.println("Traitement de " + maTache);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "Consommateur");
producteur.start();
consommateur.start();
}
}| Résultat : |
Ajout de MaTache [priorite=4, description=Tache 1]
Traitement de MaTache [priorite=4, description=Tache 1]
Ajout de MaTache [priorite=3, description=Tache 2]
Ajout de MaTache [priorite=2, description=Tache 3]
Traitement de MaTache [priorite=3, description=Tache 2]
Traitement de MaTache [priorite=2, description=Tache 3]
Ajout de MaTache [priorite=1, description=Tache 4]
Traitement de MaTache [priorite=1, description=Tache 4]
Ajout de MaTache [priorite=0, description=Tache 5]
Traitement de MaTache [priorite=0, description=Tache 5]Le temps d'exécution de la méthode size() n'est pas constant : toute la collection doit être parcourue pour déterminer le nombre d'éléments.
Les opérations groupées (addAll(), removeAll(), retainAll(), containsAll(), equals() et toArray()) n'offrent aucune garantie de s'exécuter de manière atomique. Par exemple, le parcours des éléments de la collection durant leur exécution peut ne voir qu'une partie des éléments impactés.
La classe PriorityQueue, ajoutée à Java 1.5, hérite de la classe AbstractQueue. Les éléments de la collection sont ordonnés soit par leur ordre naturel soit par l'utilisation par la collection d'une instance de type Comparator fournie en paramètre du constructeur.
Si la collection utilise l'ordre naturel alors tous les éléments qu'elle contient doivent implémenter l'interface Comparable sinon une exception de type ClassCastException est levée.
Les opérations pour obtenir un élément (poll(), remove(), peek() et element()) renvoie le premier élément de la collection. Le premier élément de la collection est le plus petit selon l'ordre de classement des éléments par la collection.
Une collection de type PriorityQueue ne peut pas contenir d'élément null.
Elle implémente toutes les méthodes optionnelles des interfaces Collection et Iterator.
La taille d'une collection de type PriorityQueue n'est pas bridée mais elle possède une capacité interne initiale qui correspond à la taille du tableau dans lequel les éléments vont être stockés. La taille de ce tableau peut évoluer selon le nombre d'éléments contenu dans la collection.
La classe PriorityQueue possède plusieurs constructeurs :
Constructeur |
Rôle |
PriorityQueue() |
Collection qui utilise l'ordre naturel avec une capacité initiale de 11 éléments |
PriorityQueue(Collection<? extends E> c) |
Collection initialisée avec les éléments de la collection fournie en paramètre qui utilise leur ordre naturel sauf si la collection est de type PriorityQueue ou SortedSet. Dans ce cas l'ordre de la collection est préservé |
PriorityQueue(int initialCapacity) |
Collection qui utilise l'ordre naturel dont la capacité initiale est fournie en paramètre |
PriorityQueue(int initialCapacity, Comparator<? super E> comparator) |
Collection qui utilise l'ordre du Comparator et la capacité initiale fournie en paramètre |
PriorityQueue(PriorityQueue<? extends E> c) |
Collection initialisée avec les éléments de la collection fournie en paramètre, en respectant l'ordre de celle-ci |
PriorityQueue(SortedSet<? extends E> c) |
Collection initialisée avec les éléments de la collection fournie en paramètre, en respectant l'ordre de celle-ci |
L'obtention d'un élément se fait dans l'ordre dans lequel la collection gère ses éléments : soit en utilisant l'ordre naturel des objets (en implémentant l'interface Comparable) soit en utilisant l'instance de type Comparator fournie au constructeur qui a créé l'instance de la collection.
Une collection de type PriorityQueue accepte d'avoir des doublons ou des éléments qui possèdent la même priorité. Il n'y a aucune garantie sur l'ordre d'obtention de ces éléments : la seule solution est d'être suffisamment discriminant dans l'algorithme de comparaison utilisé par la collection pour déterminer l'ordre des éléments.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.PriorityQueue;
public class TestPriorityQueue {
public static void main(final String[] args) {
PriorityQueue<MaTache> queue = new PriorityQueue<MaTache>();
for (int i = 1; i <= 5; i++) {
MaTache element = new MaTache(6 - i, "Tache" + i);
System.out.println("insertion element " + element);
queue.add(element);
}
System.out.println("taille de la queue=" + queue.size());
for (int i = 1; i <= 5; i++) {
MaTache element = queue.poll();
System.out.println(element);
}
}
}| Résultat : |
insertion element MaTache [priorite=5, description=Tache1]
insertion element MaTache [priorite=4, description=Tache2]
insertion element MaTache [priorite=3, description=Tache3]
insertion element MaTache [priorite=2, description=Tache4]
insertion element MaTache [priorite=1, description=Tache5]
taille de la queue=5
MaTache [priorite=1, description=Tache5]
MaTache [priorite=2, description=Tache4]
MaTache [priorite=3, description=Tache3]
MaTache [priorite=4, description=Tache2]
MaTache [priorite=5, description=Tache1]Les Iterator de la classe PriorityQueue sont de type fail-fast. L'ordre de parcours des éléments avec un Iterator obtenu en invoquant la méthode iterator() n'est pas garanti.
La classe PriorityQueue n'est pas thread-safe : si plusieurs threads doivent pouvoir modifier cette collection, il faut utiliser la classe PriorityBlockingQueue.
La classe ConcurrentLinkedQueue, ajoutée à Java 5, est une collection de type FIFO implémentée sous la forme d'une LinkedList.
La classe ConcurrentLinkedQueue possède plusieurs caractéristiques :
L'implémentation de la classe ConcurrentLinkedQueue utilise un algorithme de type CAS pour gérer les opérations concurrentes.
La classe ConcurrentLinkedQueue possède deux constructeurs :
Constructeur |
Rôle |
ConcurrentLinkedQueue() |
Créer une collection vide |
ConcurrentLinkedQueue(Collection<? Extends E> ) |
Créer une collection avec les éléments de la collection fournie en paramètre. Les éléments sont insérés dans l'ordre du parcours des éléments de la collection avec son Iterator. |
Cette classe implémente toutes les méthodes optionnelles de l'interface Queue et les instances de type Iterator obtenues implémentent toutes les méthodes optionnelles de l'interface Iterator.
Un Iterator obtenu à partir de la collection permet le parcours des éléments de la collection à un moment donné ou au moment de la création de l'Iterator. Ce parcours peut se faire en concurrence avec des modifications dans le contenu de la collection. Ce parcours ne lèvera jamais d'exceptions de type ConcurrentModificationException et un même élément ne pourra être obtenu qu'une seule fois lors du parcours.
Le temps d'exécution de la méthode size() n'est pas constant car elle doit parcourir les éléments pour déterminer le nombre d'éléments contenus dans la collection. La valeur renvoyée peut alors être inexacte si une modification du contenu de la collection est réalisée de manière concurrente lors de ce parcours.
L'exécution de manière atomique des opérations de type bulk comme addAll(), removeAll(), retainAll(), containsAll(), equals() et toArray() n'est pas garantie. Il est par exemple possible que le parcours avec un Iterator ne voit qu'une partie des éléments qui sont en cours d'ajout par la méthode addAll() dont l'exécution se fait de manière concurrente.
Le terme anglais deque vient de la contraction de «double ended queue». Une Deque est une file dans laquelle il est possible de réaliser des opérations à ses deux extrémités.
L'interface java.util.Deque, ajoutée dans Java 6, définit des fonctionnalités permettant l'ajout et la suppression d'éléments par les deux bouts dans une file.
L'interface Deque hérite de l'interface Queue. Une collection de type Deque diffère en plusieurs points d'une collection de type Queue :
Méthode |
Rôle |
void addFirst(E e) |
Insérer un nouvel élément au début de la collection |
void addLast(E e) |
Insérer un nouvel élément à la fin de la collection |
void push(E e) |
Insérer un nouvel élément au début de la collection |
boolean removeFirstOccurrence(Object o) |
Supprimer la première occurrence d'un objet dans la collection quelque soit la position de cet élément. Elle renvoie un booléen qui précise si l'opération a réussie |
boolean removeLastOccurrence(Object o) |
Supprimer la dernière occurrence d'un objet dans la collection quelque soit la position de cet élément. Elle renvoie un booléen qui précise si l'opération a réussie |
Iterator<E> descendingIterator() |
Renvoyer un itérateur qui permet le parcours de la fin vers le début de la collection |
boolean offerFirst(E e) |
Insérer un nouvel élément au début de la collection. Elle renvoie un booléen qui précise si l'opération a réussi |
boolean offerLast(E e) |
Insérer un nouvel élément à la fin de la collection. Elle renvoie un booléen qui précise si l'opération a réussi |
E peekFirst() |
Obtenir le premier élément de la liste sans le retirer de la collection |
E peekLast() |
Obtenir le dernier élément de la liste sans le retirer de la collection |
E pollFirst() |
Obtenir le premier élément de la liste et le retirer de la collection |
E pollLast() |
Obtenir le dernier élément de la liste et le retirer de la collection |
E getFirst() |
Obtenir le premier élément de la liste sans le retirer de la collection |
E getLast() |
Obtenir le dernier élément de la liste sans le retirer de la collection |
E removeFirst() |
Supprimer le premier élément de la collection |
E removeLast() |
Supprimer le dernier élément de la collection |
E pop() |
Obtenir le dernier élément de la liste et le retirer de la collection |
L'interface définit des méthodes pour manipuler les éléments de la collection par les deux bouts : à chacune de ces actions, une méthode est proposée pour lever une exception ou renvoyer une valeur particulière en cas d'échec de son exécution.
Début de la collection |
Fin de la collection |
|||
Lever une exception |
Renvoyer une valeur |
Lever une exception |
Renvoyer une valeur |
|
Ajout |
addFirst() |
offerFirst() |
addLast() |
offerLast() |
Retirer |
removeFirst() |
poolFirst() |
removeLast() |
poolLast() |
Consulter |
getFirst() |
peekFirst() |
getLast() |
peekLast() |
Il n'est pas possible d'accéder à un élément particulier de la collection hormis le premier et le dernier.
Il n'est pas recommandé d'insérer la valeur null dans une collection de type Deque essentiellement parce que la valeur null est retournée par plusieurs méthodes pour indiquer qu'elles ont échouées.
Il est préférable d'utiliser les méthodes offerFirst() et offerLast() pour ajouter un élément car elles permettent de gérer les cas ou l'ajout n'est pas possible.
Les méthodes removeFirstOccurence() et removeLastOccurence() agissent comme la méthode remove() mais elles précisent le sens de la recherche de l'élément à supprimer.
Une collection de type Deque peut être utilisé dans le mode FIFO (First In First Out) pour agir comme une file : dans ce cas, les éléments sont insérés à la fin de la collection et sont retirés du début de la collection. Plusieurs méthodes de l'interface Queue sont équivalentes aux méthodes de l'interface Deque :
Méthode de l'interface Queue |
Méthode de l'interface Deque |
add(e) |
addLast(e) |
offer(e) |
offerLast(e) |
remove() |
removeFirst() |
poll() |
pollFirst() |
element() |
getFirst() |
peek() |
peekFirst() |
Une collection de type Deque peut être utilisée dans le mode LIFO (Last In First Out) pour agir comme une pile : dans ce cas, les éléments sont insérés et retirés uniquement en tête de la collection. Il est d'ailleurs recommandé d'utiliser une instance de type Deque plutôt qu'une collection de type Stack pour implémenter une pile.
Trois méthodes facilitent l'utilisation de la collection de type Deque comme une pile :
L'API Collections propose plusieurs implémentations de l'interface Deque : ArrayDeque, ConcurrentLinkedDeque, LinkedBlockingDeque, LinkedList.
La classe ArrayDeque, ajoutée dans Java 6, est une implémentation de l'interface Deque sous la forme d'un tableau dont les dimensions peuvent évoluer.
La classe ArrayDeque est l'implémentation de choix pour une file de type FIFO.
Les performances lors de l'ajout d'un élément en début ou en fin de la collection restent constantes.
La classe ArrayDeque présente plusieurs caractéristiques :
La classe ArrayDeque propose plusieurs constructeurs :
Constructeur |
Rôle |
ArrayDeque() |
Créer une collection vide avec une capacité initiale de 16 éléments |
ArrayDeque(Collection<? extends E> c) |
Créer une collection initialisée avec les éléments de la collection fournie en paramètre. L'ordre d'insertion utilisé est celui de l'Iterator de la collection |
ArrayDeque(int numElements) |
Créer une collection vide avec la capacité initiale fournie en paramètre |
La classe ArrayDeque implémente toutes les méthodes optionnelles des interfaces Collection et Iterator.
La classe ArrayDeque peut remplacer la classe Stack pour une utilisation comme pile et la classe LinkedList pour une utilisation comme file.
Les Iterator obtenus à partir de la collection sont de type fail-fast : si une modification est effectuée dans le contenu de la collection durant le parcours avec l'Iterator alors une exception de type ConcurrentModificationException peut être levée sauf si cette modification est faite avec la méthode remove() de l'Iterator.
Il est parfois utile pour des questions de performances d'implémenter le modèle de conception producteur/consommateur (producer/consumer). Dans ce modèle, un ou plusieurs threads sont utilisés pour produire des objets et un ou plusieurs autres threads sont utilisés pour les consommer.
Avant Java 5, l'implémentation de ce modèle devait être faite manuellement, l eplus souvent en utilisant les méthodes wait() et notify() sur un objet partagé en fonction de l'état de la file d'attente.
Le modèle producteur/consommateur définit trois acteurs :
Ce modèle permet de réduire le couplage entre la production d'éléments et leur traitement. Une file d'attente est utilisée pour gérer les échanges des éléments entre le producteur et le consommateur.
Le modèle permet une coordination et une collaboration entre un ou plusieurs producteurs et un ou plusieurs consommateurs.
Ce modèle présente plusieurs avantages :
La file d'attente gère les accès de manière concurrente et bloquante : si la file est pleine, alors l'opération d'ajout attend qu'un élément soit consommé et inversement si la file est vide, l'opération d'obtention d'un élément attend qu'un nouvel élément soit ajouté.
Ce modèle permet de gérer le flux des éléments et de s'adapter selon les besoins :
Il est important en cas de forte charge sur les échanges d'éléments de surveiller la capacité de la file d'attente pour éviter que celle-ci ne devienne un goulet d'étranglement. Comme les accès concurrents sont gérés par la file d'attente, il n'y a, par exemple, aucun inconvénient à ajouter un ou plusieurs autres consommateurs.
L'interface BlockingQueue facilite la mise en oeuvre de motifs de conception en proposant directement des méthodes bloquantes pour ajouter ou retirer des éléments de la file. L'API Collections propose plusieurs implémentations de l'interface BlockingQueue qui permettent de répondre à différents besoins.
Une collection de type BlockingQueue stocke des éléments et gère la façon dont un élément est ajouté ou retiré éventuellement de manière bloquante lorsque la collection est pleine ou vide.
Les objets de type BlockingQueue permettent facilement d'échanger des objets entre des threads sans avoir à gérer explicitement la synchronisation des échanges par exemple en utilisant les méthodes wait() et notifyAll().
L'interface BlockingQueue, ajoutée dans Java 5, hérite des interfaces Collection, Queue et Iterable. Elle définit notamment des opérations :
L'interface BlockingQueue propose pour certaines méthodes des paramètres pour indiquer un temps d'attente avant de retourner un échec plutôt que d'attendre indéfiniment lors de l'ajout ou l'obtention d'un élément dans la collection. Ceci peut permettre de gérer des situations de blocages.
La principale utilisation des implémentations de l'interface BlockingQueue est pour mettre en oeuvre le paradigme producer/consumer mais les méthodes de l'interface Collection sont aussi implémentées. Il est par exemple possible d'invoquer la méthode remove() même si son invocation devrait être rare.
L'interface BlockingQueue définit plusieurs méthodes :
Méthode |
Rôle |
boolean add(E o) |
Ajouter un nouvel élément. Renvoie true en cas de succès sinon lève une exception de type IllegalStateException |
int drainTo(Collection< ? super E> c) |
Retirer les éléments de la collection pour les copier dans celle fournie en paramètre |
int drainTo(Collection < ? super E> c, int maxElements) |
Retirer au plus le nombre d'éléments de la collection pour les copier dans celle fournie en paramètre |
boolean offer(E o) |
Ajouter un nouvel élément si possible : le booléen indique le succès de l'opération |
boolean offer(E o, long timeout, TimeUnit timeUnit) |
Ajouter un nouvel élément. A la fin du timeout, elle renvoie false si l'élément n'a pu être ajouté à la collection |
E poll(long timeout, TimeUnit timeUnit) |
Obtenir et retirer le premier élément de la queue en attendant au plus le timeout fourni en paramètre. Elle renvoie false si aucun élément ne peut être retiré de la collection à la fin du timeout |
void put(E) |
Ajouter un élément, la méthode est bloquante tant que la collection est pleine |
int remainingCapacity() |
Renvoyer le nombre théorique de nouveaux éléments que peut accepter la collection avant de bloquer l'ajout. Elle renvoie Integer.MAX_VALUE si la capacité n'est pas limitée |
E take() |
Renvoyer un élément, la méthode est bloquante tant que la collection est vide |
Les méthodes put() et take() sont bloquantes :
Les collections de type BlockingQueue ne permettent pas l'ajout d'un élément null : dans ce cas, une exception de type NullPointerException est levée.
Une collection de type BlockingQueue peut avoir :
Les fonctionnalités de l'interface BlockingQueue sont prévues pour être exécutées dans un contexte concurrent (multithread). Les implémentations de type BlockingQueue sont thread-safe : il n'y a aucun soucis pour avoir plusieurs producteurs et plusieurs consommateurs sur la file.
L'interface BlockingQueue hérite de l'interface Queue pour ajouter le support d'opérations bloquantes. Les opérations d'ajout et d'obtention d'un élément dans la collection proposent quatre comportements :
Lever une exception |
Renvoie une valeur spéciale |
Bloquante |
Bloquante avec timeout |
|
Ajouter |
add(e) |
offer(e) |
put(e) |
offer(e, time, unit) |
Retirer |
remove() |
poll() |
take() |
poll(time, unit) |
Consulter |
element() |
peek() |
- |
- |
Attention : l'aspect bloquant de certaines fonctionnalités des implémentations de l'interface BlockingQueue peut induire des problèmes de contention et donc limiter la montée en charge.
Il n'est pas possible d'ajouter un élément null dans une collection de type BlockingQueue : l'invocation des méthodes add(), offer() et put() avec null en paramètre lève une exception de type NullPointerException.
Les implémentations de type BlockingQueue ne proposent en standard aucun mécanisme qui permettrait d'empêcher l'ajout de nouveaux éléments. Ainsi chaque thread qui consomme des éléments de la queue doit proposer son propre mécanisme pour s'arrêter. Le ou les threads qui ajoutent des éléments dans la collection doivent mettre en oeuvre ce mécanisme pour permettre l'arrêt des threads de consommation. Ce mécanisme peut par exemple mettre en oeuvre un élément particulier (poison object) qui, une fois consommé et identifié par le thread, lui permettra de se terminer proprement.
La classe ArrayBlockingQueue implémente l'interface BlockingQueue en utilisant un tableau d'objets.
La classe ArrayBlockingQueue utilise le mode de fonctionnement FIFO (First In First Out) : le premier élément de la file est le plus ancien et le dernier élément est le plus récent.
Son implémentation utilise un tableau ce qui lui impose une taille maximale. La capacité maximale d'un ArrayBlockingQueue doit donc être obligatoirement fixée en paramètre de l'invocation du constructeur et ne peut plus être changée ultérieurement.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Date;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class ArrayBlockingQueueMain {
private static final int NB_ELEMENTS = 5;
public static void main(final String[] args) {
final BlockingQueue<String> queue = new ArrayBlockingQueue<String>(2);
Thread producteur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= NB_ELEMENTS; i++) {
String element = "Element " + i;
try {
System.out.println(new Date() + " insertion element " +
element);
queue.put(element);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}, "Producteur");
producteur.start();
Thread consommateur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= NB_ELEMENTS; i++) {
try {
String element = queue.take();
System.out.println(new Date() + " obtention element : " +
element);
Thread.sleep(2000);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}, "Consommateur");
consommateur.start();
}
}| Résultat : |
Mon Mar 11 18:27:54 CET 2013 insertion element Element 1
Mon Mar 11 18:27:54 CET 2013 insertion element Element 2
Mon Mar 11 18:27:54 CET 2013 insertion element Element 3
Mon Mar 11 18:27:54 CET 2013 obtention element : Element 1
Mon Mar 11 18:27:54 CET 2013 insertion element Element 4
Mon Mar 11 18:27:56 CET 2013 obtention element : Element 2
Mon Mar 11 18:27:56 CET 2013 insertion element Element 5
Mon Mar 11 18:27:58 CET 2013 obtention element : Element 3
Mon Mar 11 18:28:00 CET 2013 obtention element : Element 4
Mon Mar 11 18:28:02 CET 2013 obtention element : Element 5
La classe LinkedBlockingQueue implémente l'interface BlockingQueue en utilisant une LinkedList pour stocker les éléments en interne.
Il est possible de préciser une taille maximale pour le nombre d'éléments que peut contenir la collection : par défaut, la capacité maximale d'une LinkedBlockingQueue est fixée à la valeur Integer.MAX_VALUE sauf si une valeur différente est fournie en paramètre du constructeur.
Dans une LinkedBlockingQueue, les éléments sont stockés selon le mode FIFO (First In, First Out) : le premier élément de la liste est celui qui est dans la file depuis le plus longtemps. Le dernier élément de la liste est celui qui est arrivé le plus récemment dans la file.
L'avantage d'une LinkedBlockingQueue par rapport à une ArrayBlockingQueue est de ne pas être obligé de limiter la taille de la collection : les producteurs ne sont pas bloqués en attendant que la file se vide. Ceci peut cependant engendrer d'autres difficultés comme un manque de mémoire si la collection se remplit beaucoup plus vite qu'elle ne se vide.
Une LinkedBlockingQueue offre généralement de meilleurs performances qu'une ArrayBlockingQueue notamment si la file doit contenir de nombreux objets mais elle requiert plus d'objets en mémoire.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class LinkedBlockingQueueMain {
public static void main(final String[] args) {
final BlockingQueue<String> queue = new LinkedBlockingQueue<String>();
Thread producteur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
String element = "Element " + i;
try {
System.out.println("insertion element " + element);
queue.put(element);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}, "Producteur");
producteur.start();
Thread consommateur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
try {
String element = queue.take();
System.out.println("element : " + element);
Thread.sleep(2000);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}, "Consommateur");
consommateur.start();
}
}Les éléments sont consommés dans l'ordre FIFO.
| Résultat : |
insertion element Element 1
insertion element Element 2
insertion element Element 3
insertion element Element 4
insertion element Element 5
element : Element 1
element : Element 2
element : Element 3
element : Element 4
element : Element 5
La classe PriorityBlockingQueue est une collection de type Queue qui renvoie en premier les éléments les plus prioritaires.
La classe PriorityBlockingQueue implémente l'interface BlockingQueue, Queue, Collection et Iterable.
Elle implémente toutes les méthodes optionnelles des interfaces Collection et Iterator.
Le parcours des éléments en utilisant la méthode iterator() se fait dans un ordre quelconque.
Par défaut, la capacité maximale d'un PriorityBlockingQueue est fixée à la valeur Integer.MAX_VALUE sauf si une valeur différente est fournie en paramètre du constructeur
Il n'est pas possible d'ajouter un élément null dans la collection.
La classe PriorityBlockingQueue stocke ses éléments de manière ordonnée en utilisant une instance de Comparator fournie en paramètre du constructeur ou à défaut en utilisant la méthode de l'interface Comparable implémentée par les éléments de la collection.
Si aucune instance de Comparator n'est fournie en paramètre du constructeur, alors les éléments ajoutés dans la collection doivent implémenter l'interface Comparable sinon une exception de type ClassCastException est levée.
La classe PriorityBlockingQueue n'impose rien concernant des éléments qui possèdent la même priorité : c'est l'implémentation de la méthode compareTo() qui peut gérer ce cas selon les besoins.
| Exemple : |
package com.jmdoudoux.test.collections;
public class MaTache implements Comparable<MaTache> {
private final int priorite;
private final String description;
public MaTache(final int priorite, final String description) {
this.priorite = priorite;
this.description = description;
}
@Override
public int compareTo(final MaTache tache) {
Integer prioriteCourante = getPiorite();
Integer prioriteAutre = tache.getPiorite();
if (prioriteCourante != prioriteAutre) {
return prioriteCourante.compareTo(prioriteAutre);
} else {
return getDescription().compareTo(tache.getDescription());
}
}
@Override
public boolean equals(final Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
MaTache other = (MaTache) obj;
if (description == null) {
if (other.description != null) {
return false;
}
} else if (!description.equals(other.description)) {
return false;
}
if (priorite != other.priorite) {
return false;
}
return true;
}
public String getDescription() {
return description;
}
public int getPiorite() {
return priorite;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result
+ ((description == null) ? 0 : description.hashCode());
result = prime * result + priorite;
return result;
}
@Override public String toString() {
return "MaTache [priorite=" + priorite + ", description=" + description
+ "]";
}
}La classe PriorityBlockingQueue agit comme la classe PriorityQueue avec une gestion des accès concurrents.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.PriorityBlockingQueue;
public class PriorityBlockingQueueMain {
public static void main(final String[] args) {
final BlockingQueue<MaTache> queue = new PriorityBlockingQueue<MaTache>();
Thread producteur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
MaTache element = new MaTache(6 - i, "Tache " + i);
try {
System.out.println("insertion element " + element);
queue.put(element);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
System.out.println("taille de la queue=" + queue.size());
}
}, "Producteur");
producteur.start();
try {
// on attend que tous les éléments soient insérés
// uniquement pour vérifier l'ordre d'obtention
producteur.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
MaTache elt = queue.peek();
System.out.println("peek=" + elt);
Thread consommateur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
try {
MaTache element = queue.take();
System.out.println("element : " + element);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}, "Consommateur");
consommateur.start();
}
}| Résultat : |
insertion element MaTache [priorite=5,
description=Tache 1]
insertion element MaTache [priorite=4, description=Tache 2]
insertion element MaTache [priorite=3, description=Tache 3]
insertion element MaTache [priorite=2, description=Tache 4]
insertion element MaTache [priorite=1, description=Tache 5]
taille de la queue=5 peek=MaTache [priorite=1, description=Tache 5]
element : MaTache [priorite=1, description=Tache 5]
element : MaTache [priorite=2, description=Tache 4]
element : MaTache [priorite=3, description=Tache 3]
element : MaTache [priorite=4, description=Tache 2]
element : MaTache [priorite=5, description=Tache 1]Si l'on supprime le temps d'attente de la fin du thread de production, les tâches obtenues tiennent toujours compte de l'ordre des éléments présents dans la collection au moment où l'on souhaite obtenir un élément.
| Résultat : |
peek=null
insertion element MaTache [priorite=5, description=Tache 1]
insertion element MaTache [priorite=4, description=Tache 2]
element : MaTache [priorite=5, description=Tache 1]
element : MaTache [priorite=4, description=Tache 2]
insertion element MaTache [priorite=3, description=Tache 3]
insertion element MaTache [priorite=2, description=Tache 4]
insertion element MaTache [priorite=1, description=Tache 5]
element : MaTache [priorite=3, description=Tache 3]
taille de la queue=1 element : MaTache [priorite=1, description=Tache 5]
element : MaTache [priorite=2, description=Tache 4]
La classe DelayQueue, ajoutée à Java 1.5, permet de conserver un élément jusqu'à l'expiration d'un délai.
La classe DelayQueue implémente l'interface BlockingQueue
Les éléments insérés dans une DelayQueue doivent implémenter l'interface java.util.concurrent.Delayed. Cette interface ne définit qu'une seule méthode :
Méthode |
Rôle |
long getDelay(TimeUnit timeUnit) |
Renvoyer le délai à attendre avant que l'élément ne soit retirable de la collection |
Si la valeur retournée par la méthode getDelay() est négative ou nulle alors le délai est considéré comme expiré et l'élément est immédiatement retirable. Le paramètre de type TimeUnit permet de préciser l'unité de temps dans laquelle la valeur doit être retournée.
L'interface Delayed hérite de l'interface Comparable<Delayed>.
Chaque implémentation doit donc redéfinir la méthode compareTo() qui est utilisée par le DelayQueue pour déterminer l'ordre de renvoie d'un élément.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Date;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
public class MonElementDelayed implements Delayed {
private final String donnees;
private final long momentDeLiberation;
public MonElementDelayed(final String donnees, final long delai) {
this.donnees = donnees;
this.momentDeLiberation = System.currentTimeMillis() + delai;
}
@Override
public int compareTo(final Delayed o) {
int resultat = -1;
if (o instanceof MonElementDelayed) {
MonElementDelayed med = (MonElementDelayed) o;
if (this.momentDeLiberation < med.momentDeLiberation) {
resultat = -1;
} else {
if (this.momentDeLiberation > med.momentDeLiberation) {
resultat = 1;
} else {
resultat = 0;
}
}
}
return resultat;
}
@Override
public boolean equals(final Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
MonElementDelayed other = (MonElementDelayed) obj;
if (donnees == null) {
if (other.donnees != null) {
return false;
}
} else if (!donnees.equals(other.donnees)) {
return false;
}
if (momentDeLiberation != other.momentDeLiberation) {
return false;
}
return true;
}
@Override
public long getDelay(final TimeUnit unit) {
long diff = momentDeLiberation - System.currentTimeMillis();
return unit.convert(diff, TimeUnit.MILLISECONDS);
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((donnees == null) ? 0 : donnees.hashCode());
result = prime * result
+ (int) (momentDeLiberation ^ (momentDeLiberation >>> 32));
return result;
}
@Override
public String toString() {
return "donnees='" + donnees + "', momentDeLiberation="
+ new Date(momentDeLiberation);
}
}Attention : l'implémentation de la méthode compareTo() doit tenir compte du délai restant lié à l'objet. Cette implémentation nest donc pas cohérente avec la méthode equals() ce qui exclut l'utilisation des objets de type Delayed dans certaines collections notamment celles de type SortedXXX.
Les implémentations de plusieurs méthodes de la classe DelayQueue assurent les comportements spécifiques de cette collection :
Méthode |
Rôle |
int drainTo(Collection<? super E> c) |
Retirer tous les éléments dont le délai est expiré et les ajouter dans la collection fournie en paramètre |
int drainTo(Collection<? super E> c, int maxElements) |
Retirer au plus le nombre d'éléments dont le délai est expiré et les ajouter dans la collection fournie en paramètre |
Iterator<E> iterator() |
Renvoyer un Iterator permettant le parcours sur tous les éléments expirés ou non |
boolean offer(E e, long timeout, TimeUnit unit) |
Ajouter un élément dans la collection. Les paramètres timeout et unit sont ignorés |
E peek() |
Obtenir le prochain élément que son délai soit expiré ou non sans le retirer de la collection. |
E poll() |
Renvoyer le premier élément dont le délai est expiré et le supprimer de la collection. Elle renvoie toujours null tant que le délai d'attente d'au moins un élément n'est pas atteint. |
E poll(long timeout, TimeUnit unit) |
Identique à la méthode poll() mais attend au besoin le délai fourni en paramètre |
int remainingCapacity() |
Renvoyer toujours la valeur Integer.MAX_VALUE car la taille de la collection ne peut pas être limitée explicitement |
boolean remove(Object o) |
Retirer un élément de la collection que son délai soit expiré ou non |
int size() |
Renvoyer le nombre total d'éléments dans la collection qu'ils soient expirés ou non |
E take() |
Renvoyer le premier élément dont le délai est expiré et le supprimer de la collection. Son invocation est bloquante tant que le délai d'aucun élément n'est atteint |
Object[] toArray() |
Renvoyer un tableau de tous les éléments de la collection |
La taille d'un DelayQueue ne peut pas être limitée : l'ajout d'un nouvel élément en utilisant la méthode put() n'est donc jamais bloquante. Par contre, l'invocation de la méthode take() est bloquante tant que le délai d'attente d'un élément n'est pas atteint (dans ce cas, la valeur retournée par la méthode getDelay() est inférieure ou égale à zéro).
Si plusieurs éléments ont leur délai d'attente atteint lors de l'invocation de la méthode take() alors celle-ci renvoie l'élément dont le délai d'attente est le plus dépassé.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Date;
import java.util.concurrent.DelayQueue;
public class DelayQueueMain {
public static void main(final String[] args) {
DelayQueue<MonElementDelayed> queue = new
DelayQueue<MonElementDelayed>();
for (int i = 1; i <= 5; i++) {
MonElementDelayed element = new MonElementDelayed("Message" + i, 2000 * i);
System.out.println("insertion element " + element);
queue.put(element);
}
System.out.println("taille de la queue=" + queue.size());
try {
for (int i = 1; i < 5; i++) {
MonElementDelayed element = queue.take();
System.out.println("element obtenu le" + new Date());
System.out.println(" " + element);
}
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}| Résultat : |
insertion element donnees='Message1',
momentDeLiberation=Fri Mar 01 22:34:04 CET 2013
insertion element donnees='Message2', momentDeLiberation=Fri Mar 01 22:34:06 CET 2013
insertion element donnees='Message3', momentDeLiberation=Fri Mar 01 22:34:08 CET 2013
insertion element donnees='Message4', momentDeLiberation=Fri Mar 01 22:34:10 CET 2013
insertion element donnees='Message5', momentDeLiberation=Fri Mar 01 22:34:12 CET 2013
taille de la queue=5 element obtenu leFri Mar 01 22:34:04 CET 2013
donnees='Message1', momentDeLiberation=Fri Mar 01 22:34:04 CET 2013
element obtenu leFri Mar 01 22:34:06 CET 2013
donnees='Message2', momentDeLiberation=Fri Mar 01 22:34:06 CET 2013
element obtenu leFri Mar 01 22:34:08 CET 2013
donnees='Message3', momentDeLiberation=Fri Mar 01 22:34:08 CET 2013
element obtenu leFri Mar 01 22:34:10 CET 2013
donnees='Message4', momentDeLiberation=Fri Mar 01 22:34:10 CET 2013
La classe SynchronousQueue, ajoutée à Java 1.5 implémente l'interface BlockingQueue pour proposer un moyen facile d'échanger un élément entre deux threads et de synchroniser ces échanges.
Elle ne possède pas de capacité de stockage : elle ne peut contenir qu'un seul élément au plus. L'insertion d'un nouvel élément en invoquant la méthode put() est bloquée jusqu'à ce que l'élément inséré soit retiré. De façon similaire, si la collection est vide alors l'invocation de la méthode take() reste bloquée jusqu'à ce qu'un nouvel élément soit ajouté dans la collection.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.concurrent.BlockingQueue;
public class MonProducer implements Runnable {
private final BlockingQueue<String> queue;
public MonProducer(final BlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
try {
for (int i = 1; i < 6; i++) {
queue.put("Message" + i);
System.out.println("Producer envoie Message" + i);
}
queue.put("Stop");
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.concurrent.BlockingQueue;
public class MonConsumer implements Runnable {
private final BlockingQueue<String> queue;
public MonConsumer(final BlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
try {
String msg = null;
boolean stop = false;
while (!stop) {
msg = queue.take();
if (msg.equals("Stop")) {
stop = true;
} else {
Thread.sleep(2000);
System.out.println("Consumer traite " + msg);
}
}
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.SynchronousQueue;
public class SynchronousQueueMain {
public static void main(final String[] args) {
BlockingQueue<String> queue = new SynchronousQueue<String>();
(new Thread(new MonProducer(queue))).start();
try {
Thread.sleep(1000);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
(new Thread(new MonConsumer(queue))).start();
}
}| Résultat : |
Producer envoie Message1
Consumer traite Message1
Producer envoie Message2
Consumer traite Message2
Producer envoie Message3
Consumer traite Message3
Producer envoie Message4
Consumer traite Message4
Producer envoie Message5
Consumer traite Message5Remarque : les temps d'attente dans l'exemple sont uniquement présents pour faciliter la compréhension du fonctionnement de la classe SynchronousQueue.
L'interface BlockingDeque, ajoutée à Java 6.0, implémente les interfaces Deque et BlockingQueue avec des opérations bloquantes :
L'utilisation d'un BlockingDeque est particulièrement intéressante :
Le comportement des méthodes de l'interface BlockingQueue d'un BlockingDeque est de respecter le mode de fonctionnement prévu par cette interface
Méthode de l'interface BlockingQueue |
Méthode invoquée |
add() |
addLast() |
offer() |
offerLast() |
put() |
putLast() |
remove() |
removeFirst() |
poll() |
pollFirst() |
take() |
takeFirst() |
element() |
getFirst() |
peek() |
peekFirst() |
L'interface BlockingDeque propose quatre comportements différents pour les opérations d'ajout, de retrait et de consultation d'un élément dans la collection si celles-ci ne peuvent pas être réalisées immédiatement :
Lève une exception |
Renvoie une valeur |
Bloquant |
Time out |
|
Ajout |
addFirst() addLast() |
offerFirst() offerLast() |
putFirst() putLast() |
offerFirst(timeout) offerLast(timeout) |
Retrait |
removeFirst() removeLast() |
pollFirst() pollLast() |
takeFirst() takeLast() |
pollFirst(timeout) pollLast(timeout) |
Consultation |
getFirst() getLast() |
peekFirst() peekLast() |
L'API Collections propose une seule implémentation de l'interface BlockingDeque : la classe java.util.concurrent.LinkedBlockingDeque.
La classe LinkedBlockingDeque, ajoutée à Java 6.0, implémente l'interface BlockingDeque.
La classe LinkedBlockingDeque utilise en interne une liste chaînée de type LinkedList pour stocker ses éléments.
Un des constructeurs de la classe LinkedBlockingDeque attend en paramètre une valeur qui précise la capacité maximale de la collection.
| Exemple : |
package com.jmdoudoux.test.collections;
import java.util.Date;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
public class TestLinkedBlockingDequeMain {
private static final int NB_ELEMENTS = 5;
public static void main(final String[] args) {
// final BlockingDeque<String> queue = new LinkedBlockingDeque<String>();
final BlockingDeque<String> queue = new LinkedBlockingDeque<String>(2);
Thread producteur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= NB_ELEMENTS; i++) {
String element = "Element " + i;
try {
System.out.println(new Date() + " insertion element " + element);
queue.putFirst(element);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}, "Producteur");
producteur.start();
Thread consommateur = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= NB_ELEMENTS; i++) {
try {
String element = queue.takeLast();
System.out.println(new Date() + " obtention element : " + element);
Thread.sleep(2000);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}, "Consommateur");
consommateur.start();
}
}| Résultat : |
Fri Mar 15 21:06:34 CET 2013 insertion element
Element 1 Fri Mar 15 21:06:34 CET 2013 insertion element
Element 2 Fri Mar 15 21:06:34 CET 2013 insertion element
Element 3 Fri Mar 15 21:06:34 CET 2013 obtention element :
Element 1 Fri Mar 15 21:06:34 CET 2013 insertion element
Element 4 Fri Mar 15 21:06:36 CET 2013 insertion element
Element 5 Fri Mar 15 21:06:36 CET 2013 obtention element :
Element 2 Fri Mar 15 21:06:38 CET 2013 obtention element :
Element 3 Fri Mar 15 21:06:40 CET 2013 obtention element :
Element 4 Fri Mar 15 21:06:42 CET 2013 obtention element :
Element 5Les performances d'insertion et de suppression d'un élément sont similaires à celles d'une collection de type LinkedBlockingQueue puisqu'elles utilisent toutes les deux une LinkedList pour la gestion de leurs éléments.
Plusieurs implémentations de type Queue et BlockingQueue sont particulièrement utiles pour gérer des échanges d'objets entre threads par exemple en mettant en oeuvre le motif de conception producteur/consommateur.
Plusieurs implémentations de type Queue ne peuvent être utilisées que pour des cas bien particuliers :
Le choix d'une implémentation d'une collection de type Queue pour un usage général doit se faire selon les fonctionnalités qu'elle doit supporter :
Si la collection de type Queue n'a pas besoin de gérer d'accès concurrents alors il faut utiliser la classe LinkedList.
Si les accès concurrents doivent être gérés alors il faut utiliser la classe ConcurrentLinkedList.
Si la taille de la collection de type Queue doit être bornée, alors il faut utiliser la classe ArrayBlockingQueue.
Critère |
Taille limitée |
Taille non limitée |
|
Bloquante |
Aucun |
ArrayBlockingQueue |
LinkedBlockingQueue |
Priorité |
PriorityBlockingQueue |
||
Delai |
DelayQueue |
||
Transfert |
SynchronousQueue LinkedTransferQueue |
||
Deque |
LinkedBlockingDeque |
||
Non-bloquante |
Thread-safe |
ConcurrentLinkedQueue |
|
Non thread-safe |
LinkedList |
||
Non thread-safe, priorité |
PriorityQueue |
||
Non thread-safe, Deque |
ArrayDeque |
L'ordre de tri est défini grâce à deux interfaces :
Tous les objets qui doivent définir un ordre naturel utilisé par le tri d'une collection doivent implémenter cette interface.
Cette interface ne définit qu'une seule méthode : int compareTo(Object).
Cette méthode doit renvoyer :
Les classes wrappers, String et Date implémentent cette interface.
Cette interface représente un ordre de tri quelconque. Elle est utile pour permettre le tri d'objets qui n'implémentent pas l'interface Comparable ou pour définir un ordre de tri différent de celui défini avec Comparable ( l'interface Comparable représente un ordre naturel : il ne peut y en avoir qu'un)
Cette interface ne définit qu'une seule méthode : int compare(Object, Object).
Cette méthode compare les deux objets fournis en paramètres et renvoie :
La classe Collections propose plusieurs méthodes statiques pour effectuer des opérations sur des collections. Ces traitements sont polymorphiques car ils demandent en paramètre un objet qui implémente une interface et retournent une collection.
| Méthode | Rôle |
| void copy(List, List) | Copier tous les éléments de la seconde liste dans la première |
| Enumeration enumeration(Collection) | Renvoyer un objet Enumeration pour parcourir la collection |
| Object max(Collection) | Renvoyer le plus grand élément de la collection selon l'ordre naturel des éléments |
| Object max(Collection, Comparator) | Renvoyer le plus grand élément de la collection selon l'ordre précisé par l'objet Comparator |
| Object min(Collection) | Renvoyer le plus petit élément de la collection selon l'ordre naturel des éléments |
| Object min(Collection, Comparator) | Renvoyer le plus petit élément de la collection selon l'ordre précisé par l'objet Comparator |
| void reverse(List) | Inverser l'ordre de la liste fournie en paramètre |
| void shuffle(List) | Réordonner tous les éléments de la liste de façon aléatoire |
| void sort(List) | Trier la liste dans un ordre ascendant selon l'ordre naturel des éléments |
| void sort(List, Comparator) | Trier la liste dans un ordre ascendant selon l'ordre précisé par l'objet Comparator |
Si la méthode sort(List) est utilisée, il faut obligatoirement que les éléments inclus dans la liste implémentent tous l'interface Comparable sinon une exception de type ClassCastException est levée.
La classe Collections propose aussi plusieurs méthodes pour obtenir une version multithread ou non modifiable des principales interfaces des collections : Collection, List, Map, Set, SortedMap, SortedSet
| Exemple ( code Java 1.2 ) : |
import java.util.*;
public class TestUnmodifiable{
public static void main(String args[]) {
List list = new LinkedList();
list.add("1");
list.add("2");
list = Collections.unmodifiableList(list);
list.add("3");
}
}| Résultat : |
C:\>java TestUnmodifiable
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.Collections$UnmodifiableCollection.add(Unknown Source)
at TestUnmodifiable.main(TestUnmodifiable.java:13)L'utilisation d'une méthode synchronizedXXX() renvoie une instance de l'objet qui supporte la synchronisation pour les opérations d'ajout et de suppression d'éléments. Pour le parcours de la collection avec un objet Iterator, il est nécessaire de synchroniser le bloc de code utilisé pour le parcours. Il est important d'inclure aussi dans ce bloc l'appel à la méthode pour obtenir l'objet de type Iterator utilisé pour le parcours.
| Exemple ( code Java 1.2 ) : |
import java.util.*;
public class TestSynchronized{
public static void main(String args[]) {
List maList = new LinkedList();
maList.add("1");
maList.add("2");
maList.add("3");
maList = Collections.synchronizedList(maList);
synchronized(maList) {
Iterator i = maList.iterator();
while (i.hasNext())
System.out.println(i.next());
}
}
}
L'exception de type UnsupportedOperationException est levée lorsqu'une opération optionnelle n'est pas supportée par l'objet qui gère la collection.
L'exception ConcurrentModificationException est levée lors du parcours d'une collection avec un objet Iterator et que cette collection subit une modification structurelle.